feat: column-level lineage for DuckLake pipelines (SQL-AST inferred + traceable)#9814
Conversation
…ation Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
Deploying windmill with
|
| Latest commit: |
8b86bdc
|
| Status: | ✅ Deploy successful! |
| Preview URL: | https://ce001bfc.windmill.pages.dev |
| Branch Preview URL: | https://pipeline-column-lineage.windmill.pages.dev |
|
Claude finished @rubenfiszel's task in 2m 55s —— View job ReviewGood to merge — no blocking issues. The parser change is correct, fully mirrored across Rust/TS, and locked down by a shared parity corpus; the frontend surfaces are coherent with the existing This is a model example of the "Surface A" discipline: every parser behavior is wired in both parsers and asserted against the same What I verifiedParser parity (Rust ↔ TS). I traced the head-then-tail parse on both sides and they're behaviorally identical at every branch:
Edge cases I poked at manually ( Wire shape. Frontend correctness.
Optional polish (non-blocking)
AGENTS.md complianceComments follow the "record constraints, not narration" rule well — each explains a non-obvious invariant (why Test coverage
|
|
I've now thoroughly reviewed the parser, API, frontend components, test fixtures, and parity assertions. Let me write the final review. Pi ReviewGood to merge ✅ This PR implements column-level lineage for DuckLake pipelines via a What I checked
Test coverage
Manual verification needed before mergeThe PR description calls out one reviewer step: edit a |
Codex Reviewcc @rubenfiszel Found 2 issues:
Test Coverage Backend parser unit/parity fixtures and frontend parser parity cover the annotation grammar. Missing coverage is in graph resolution/render targeting: live editor overlay for Manual verification needed: toggle a |
There was a problem hiding this comment.
1 issue found across 15 files
Prompt for AI agents (unresolved issues)
Check if these issues are valid — if so, understand the root cause of each and fix them. If appropriate, use sub-agents to investigate and fix each issue separately.
<file name="frontend/src/lib/components/assets/AssetGraph/AssetGraphEdge.svelte">
<violation number="1" location="frontend/src/lib/components/assets/AssetGraph/AssetGraphEdge.svelte:77">
P3: When both the data-test badge and the column-lineage badge are present, the 12px vertical offset between two 18px-tall `foreignObject` elements leaves a ~6px overlap. Increase the offset to 16–18px to fully clear the badges visually.</violation>
</file>
Reply with feedback, questions, or to request a fix.
Fix all with cubic | Re-trigger cubic
…verride) Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
Pi ReviewGood to merge — no blocking issues. The column lineage feature follows the established Prior Codex findings re-examined"Live column-lineage edits are not overlaid" This is correct: The Codex reviewer also claimed the pipeline page "keeps the current editor buffer outside "Column lineage is attached to every ducklake write by the same producer" This follows the identical pattern as What I verified
Test coverage
Manual verificationNo manual verification strictly required — the PR description's reviewer step (toggling a
|
Codex Reviewcc @rubenfiszel Found 3 issues:
Test coverage Backend parser/parity tests cover the grammar and basic inference. Missing coverage is around graph endpoint fallback on DuckDB parse failure, live Manual verification should cover editing a |
…otations Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
Codex Reviewcc @rubenfiszel Found 1 issue:
Test coverage Backend parser tests cover successful inference, merge behavior, and annotation parity. Missing coverage is the graph-endpoint fallback path where DuckDB AST parsing fails but explicit Manual verification needed: deploy a DuckDB pipeline member with a |
|
I've now thoroughly examined the diff, the prior reviews, and the relevant source files. Here is my review: Pi Reviewcc @rubenfiszel Should address issues before merging: DuckDB parse failures drop annotation lineage [P1] DuckDB parse failures silently discard
|
Threads the DuckDB SQL-AST column lineage (from the WASM asset parser) through ScriptEditor -> details pane -> page -> resolveGraph, merged with // column annotations (annotation wins) so the live preview matches the deployed graph. Takes effect once windmill-parser-wasm-asset is republished with the inference. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
Pi Reviewcc @rubenfiszel Should address issues before merging: DuckDB parse failures drop annotation lineage [P1] DuckDB parse failures silently discard
|
There was a problem hiding this comment.
1 issue found across 7 files (changes from recent commits).
Prompt for AI agents (unresolved issues)
Check if these issues are valid — if so, understand the root cause of each and fix them. If appropriate, use sub-agents to investigate and fix each issue separately.
<file name="frontend/src/lib/components/assets/AssetGraph/AssetGraphDetailsPane.svelte">
<violation number="1" location="frontend/src/lib/components/assets/AssetGraph/AssetGraphDetailsPane.svelte:375">
P2: `liveColumnLineage` can leak across script switches because it is a persistent `$state` variable that is forwarded in `onAssetsChange` without resetting when `script.path` changes. During a transition from script A to script B, the `$effect` re-runs as soon as `script.path` updates but before the new `ScriptEditor` has computed new lineage, pairing B’s path with A’s stale data. If the new script triggers an inference error, the `watch` in `ScriptEditor` returns without updating the binding, so the leak becomes permanent.</violation>
</file>
Tip: Review your code locally with the cubic CLI to iterate faster.
Fix all with cubic | Re-trigger cubic
| // Body-inferred column lineage (DuckDB SQL AST), bound out of ScriptEditor | ||
| // alongside `liveBodyAssets` and forwarded so the live graph can show | ||
| // inferred column lineage on the edited script before it deploys. | ||
| let liveColumnLineage = $state<ColumnLineage[] | undefined>(undefined) |
There was a problem hiding this comment.
P2: liveColumnLineage can leak across script switches because it is a persistent $state variable that is forwarded in onAssetsChange without resetting when script.path changes. During a transition from script A to script B, the $effect re-runs as soon as script.path updates but before the new ScriptEditor has computed new lineage, pairing B’s path with A’s stale data. If the new script triggers an inference error, the watch in ScriptEditor returns without updating the binding, so the leak becomes permanent.
Prompt for AI agents
Check if this issue is valid — if so, understand the root cause and fix it. At frontend/src/lib/components/assets/AssetGraph/AssetGraphDetailsPane.svelte, line 375:
<comment>`liveColumnLineage` can leak across script switches because it is a persistent `$state` variable that is forwarded in `onAssetsChange` without resetting when `script.path` changes. During a transition from script A to script B, the `$effect` re-runs as soon as `script.path` updates but before the new `ScriptEditor` has computed new lineage, pairing B’s path with A’s stale data. If the new script triggers an inference error, the `watch` in `ScriptEditor` returns without updating the binding, so the leak becomes permanent.</comment>
<file context>
@@ -365,6 +369,10 @@
+ // Body-inferred column lineage (DuckDB SQL AST), bound out of ScriptEditor
+ // alongside `liveBodyAssets` and forwarded so the live graph can show
+ // inferred column lineage on the edited script before it deploys.
+ let liveColumnLineage = $state<ColumnLineage[] | undefined>(undefined)
// Bumped when the runs panel reports a watched job has reached a
</file context>

Codex Reviewcc @rubenfiszel Found 2 issues:
Test coverage Backend parser tests cover successful inference, annotation override, wildcard, subquery avoidance, and parser parity. Missing coverage for the two failing paths above: graph fallback when DuckDB AST parsing fails but annotations exist, and inferred lineage through Frontend parser parity and graph display coverage look appropriate for the UI layer; no Svelte component tests are expected by repo policy. Manual verification should include a DuckDB member with explicit |
…olumn-lineage inference Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
…annotations Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
I now have a clear picture of the two real issues. Let me write the review. Pi Reviewcc @rubenfiszel Should address issues before merging: DuckDB parse failures drop annotation lineage, JOIN columns not resolved for inferred lineage [P1] DuckDB parse failures silently discard
|
Codex Reviewcc @rubenfiszel Found 3 issues:
Test coverage Backend parser tests cover successful inference, annotation override, wildcard handling, subquery avoidance, merge behavior, and annotation parity. Missing coverage for the two failing backend paths above: graph fallback when DuckDB AST parsing fails but annotations exist, and inferred lineage through Frontend parser parity and graph display coverage look appropriate for the UI layer; no Svelte component tests are expected by repo policy. Manual verification should include a DuckDB member with explicit |
|
I now have a complete picture. Here is the review: Pi Reviewcc @rubenfiszel Should address issues before merging: DuckDB parse failures drop annotation lineage, JOIN columns not resolved for inferred lineage [P1] DuckDB parse failures silently discard
|
Codex Reviewcc @rubenfiszel Found 2 issues:
Test coverage Backend parser tests cover successful inference, annotation override, wildcard handling, subquery avoidance, merge behavior, and annotation parity. Missing coverage for the two failing backend paths above: graph fallback when DuckDB AST parsing fails but annotations exist, and inferred lineage through Frontend parser parity and graph display coverage look appropriate for this UI layer; no Svelte component tests are expected by repo policy. Manual verification should include a DuckDB member with explicit |
|
End-to-end verified with the published
Note: the Playwright MCP was down this session, so these were captured via a headless Playwright script driving system Chromium. |
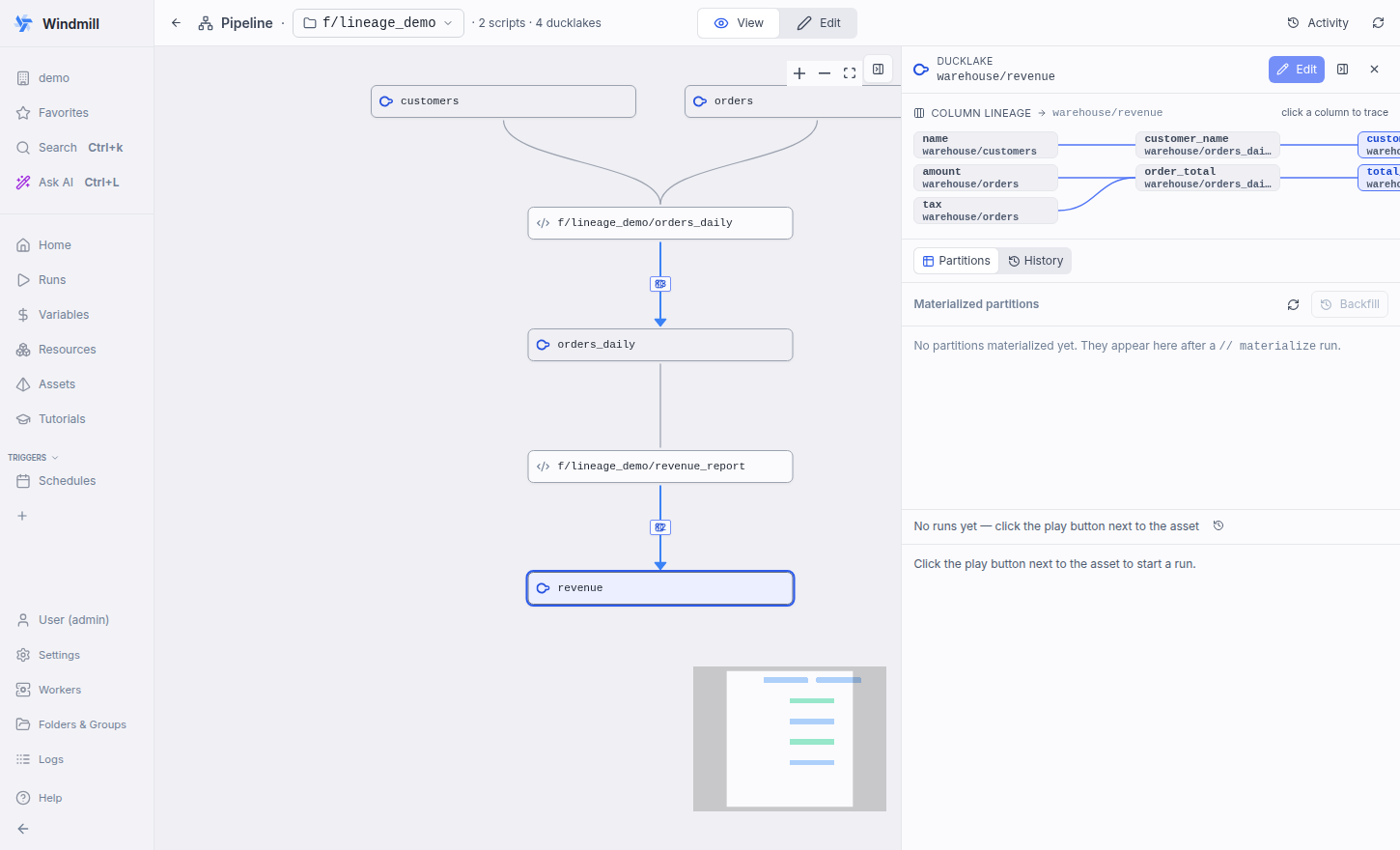
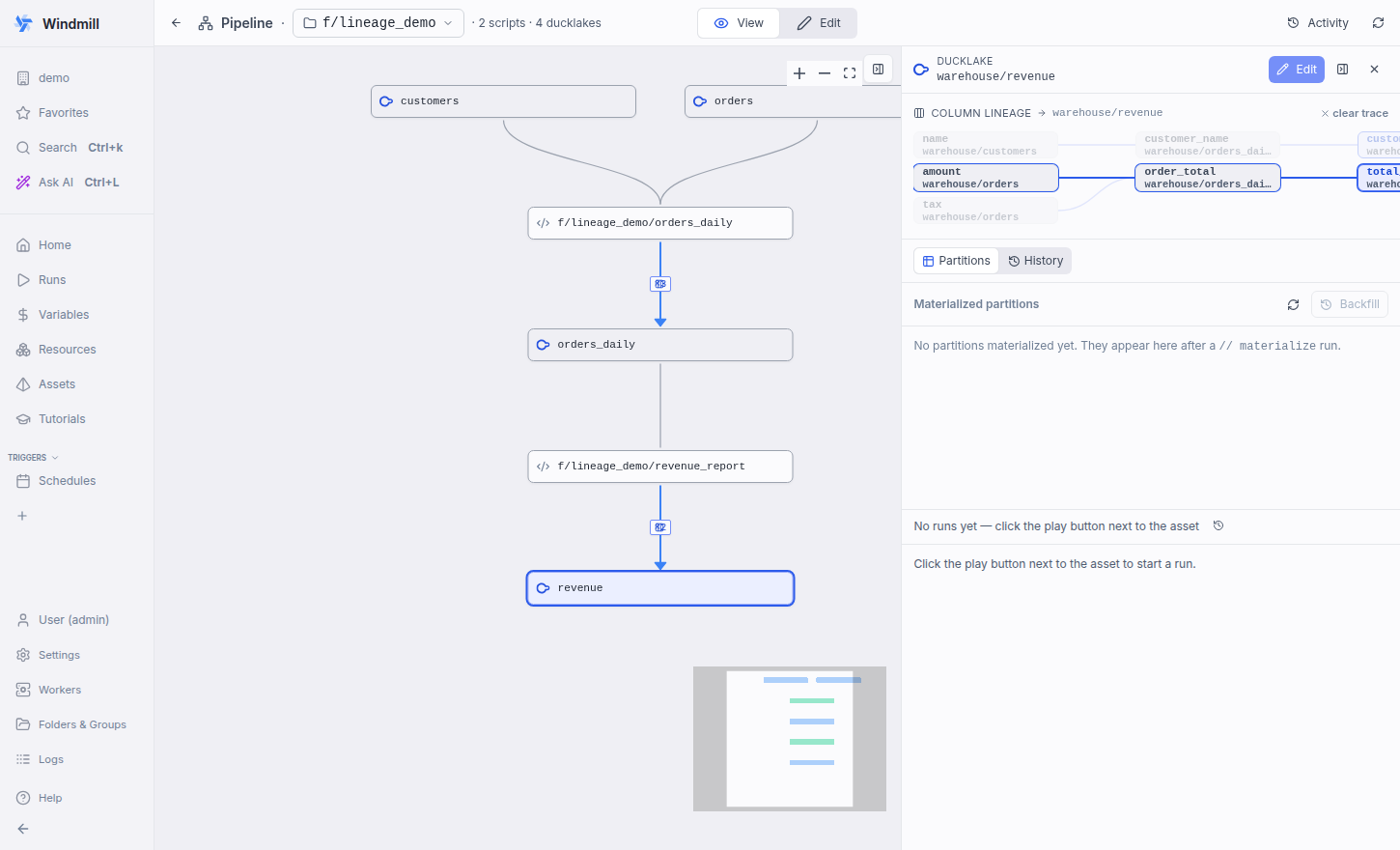
Stitches every producer's column_lineage into a pipeline-wide column graph (columnLineageGraph.ts) and replaces the single-hop diagram with an interactive ColumnLineageTrace: select an asset to see its columns' full upstream/downstream lineage across scripts; click any column to highlight its complete transitive impact set (forward + backward) and dim the rest. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
Transitive column-lineage trace (impact analysis) — turns the static diagram into a tool. New Multi-hop chain in the demo: Select the sink asset
Click
Tests: |
|
Now I have all the information needed. Here's my review: Pi Reviewcc @rubenfiszel Should address issues before merging: DuckDB parse failures drop annotation lineage, JOIN columns not resolved for inferred lineage [P1] DuckDB parse failures silently discard
|
Addressed second Codex pass (commit 4319d74)Both new P1s fixed and verified live against the running graph API:
Tests: 9 |
|
Now I have a complete picture. Let me write the review. Pi ReviewGood to merge — all three P1 issues flagged by prior reviews have been addressed in the fix commits. No new issues introduced. Prior review findings — all fixed
What I verified
Live overlay gap (pre-existing, not a regression)
Test coverage
|
Codex Reviewcc @rubenfiszel Found 1 issues:
Test coverage Missing coverage is specifically the canvas badge targeting: add a graph/render-level case with one producer, a Manual verification: deploy or draft a DuckDB pipeline member that materializes one DuckLake asset and also writes another DuckLake table; the column badge and hover mappings should appear only on the |
The canvas badge keyed on `e.asset_kind === 'ducklake'`, so a multi-output producer showed the same column mapping on every ducklake write-edge. Use the same materialize-target anchor as buildColumnGraph: the badge lands only on the declared output's edge, falling back to the ducklake write-edge when there's no materialize annotation. (Codex P1) Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
[P1] Badge on every ducklake write-edge — fixed (e2cdcee). The canvas badge now uses the same materialize-target anchor as |
# Conflicts: # backend/windmill-api-assets/src/lib.rs # frontend/src/lib/components/assets/AssetGraph/AssetGraphDetailsPane.svelte # frontend/src/lib/components/assets/AssetGraph/types.ts # frontend/src/routes/(root)/(logged)/pipeline/[folder]/+page.svelte
Pi ReviewGood to merge. All three P1 issues flagged in prior review rounds have been resolved in the latest commits ( Previously flagged issues — now fixed
What I verified
Test coverage
|
Codex Reviewcc @rubenfiszel Found 1 issue:
Test coverage Backend parser/parity coverage and frontend column-graph utility tests look solid for the new parser and graph stitching logic. The remaining gap is page-level manual verification: in View mode with drafts hidden, select a deployed DuckLake asset while an unsaved draft changes its |
The transitive column trace was built from graphWithDraft regardless of mode, so in View with drafts hidden it could surface draft `// column` lineage the deployed canvas doesn't show. Build it from `displayGraph` (the graph the canvas actually renders) so the trace matches: draft overlays in edit / show-drafts, deployed-only in plain View. (Codex P2) Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
[Codex P2] Column trace could show draft lineage in View — fixed (4459df7). The trace graph is now built from |
Pi ReviewGood to merge — all three P1 issues flagged by prior reviews have been addressed in the fix commits. No new issues introduced. Prior review findings — all fixed
What I verified
Live overlay gap (pre-existing, not a regression)
Test coverage
Manual verification suggestedVerify a DuckDB pipeline member with explicit Verify a DuckDB transform that JOINs two source assets with output columns from both sides. Deploy and inspect the deployed graph's column lineage trace — columns from both joined tables should appear as upstream sources. |
Codex Reviewcc @rubenfiszel Found 1 issue:
Test coverage Backend parser tests cover annotation parsing, merge precedence, joins, wildcards, and subquery avoidance, but I don’t see coverage for local/temp CTAS inside a materialized script. Frontend graph tests cover anchoring to Manual verification should include a DuckDB pipeline member that stages through a temp table before the final managed-materialize I attempted local targeted tests, but they did not run in this checkout: backend |
A CTAS into a local/temp staging table isn't the materialized output, but its projection was inferred and (flat) column_lineage anchored to the script's // materialize target — so staging columns showed up as the final asset's. Gate inference to the actual output: a top-level managed-materialize SELECT, or a CTAS/CREATE VIEW whose target resolves to a real asset. (Codex P1) Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
[Codex P1] Local/temp staging CTAS reported as final columns — fixed (e6e4b45). Column-lineage inference is now gated to the actual materialized output: a top-level managed-materialize |
There was a problem hiding this comment.
1 issue found across 1 file (changes from recent commits).
Prompt for AI agents (unresolved issues)
Check if these issues are valid — if so, understand the root cause of each and fix them. If appropriate, use sub-agents to investigate and fix each issue separately.
<file name="frontend/src/lib/components/assets/AssetGraph/AssetGraphDetailsPane.svelte">
<violation number="1" location="frontend/src/lib/components/assets/AssetGraph/AssetGraphDetailsPane.svelte:375">
P2: `liveColumnLineage` can leak across script switches because it is a persistent `$state` variable that is forwarded in `onAssetsChange` without resetting when `script.path` changes. During a transition from script A to script B, the `$effect` re-runs as soon as `script.path` updates but before the new `ScriptEditor` has computed new lineage, pairing B’s path with A’s stale data. If the new script triggers an inference error, the `watch` in `ScriptEditor` returns without updating the binding, so the leak becomes permanent.</violation>
</file>
Tip: Review your code locally with the cubic CLI to iterate faster.
Fix all with cubic | Re-trigger cubic
|
All critical fixes confirmed in the current code. Here's the review: Pi ReviewGood to merge — all previously flagged issues have been addressed in the fix commits. No new issues introduced. Prior review findings — all resolved
What I verified
Test coverage
|
Codex Reviewcc @rubenfiszel Found 1 issue:
Test coverage Backend parser tests cover computed columns, passthroughs, annotation override, JOIN resolution, wildcard skipping, subquery skipping, and local/temp staging CTAS. Frontend tests cover transitive stitching and choosing the Frontend component tests are not expected by repo policy. Manual verification should include a DuckDB pipeline member with a managed |
Inference accumulated columns from every output-producing query into one flat list, all anchored (frontend) to the script's // materialize target — so an auxiliary CTAS into a different asset showed its columns on the materialized one. Tag each inferred entry with its output asset and, in parse_assets, scope the list to the // materialize target (keeping untagged top-level-SELECT entries); with no declared target, drop inference when entries span multiple output assets rather than attribute them to an arbitrary one. Parser-internal — no wire change. (Codex P1) Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
[Codex P1] Multi-output lineage attributed to the wrong asset — fixed (57cd092). Inference now tags each entry with its output asset and |
|
Now I have a complete picture of the PR's current state. Let me compile my review. Pi ReviewGood to merge — all findings from prior review rounds have been addressed. No new issues introduced. Prior review findings — all resolved
What I verified
Test coverage
Manual verification still neededDeploy a DuckDB pipeline member that joins two source assets with a computed column mixing both sides (e.g., Deploy a DuckDB pipeline member with explicit |
Codex Reviewcc @rubenfiszel Found 1 issue:
Test coverage Backend parser tests cover joins, annotation override, wildcard skipping, subquery skipping, local/temp staging without Frontend pure-logic tests cover materialize-target anchoring and fallback graph stitching. No Svelte component tests are expected by repo policy. Manual verification should use a DuckDB pipeline member with |
A one-part temp name under `USE dl` resolved to an asset (ducklake://…/tmp) before being registered local, so a final SELECT reading it invented `final.total <- warehouse/tmp.amt` (a phantom DuckLake column) and recorded a phantom asset. track_table_definition now registers any temporary table/view as local up front, bypassing active-asset resolution; CreateTable/CreateView pass their `temporary` flag. (Codex P1) Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
[Codex P1] CREATE TEMP under USE leaked a phantom DuckLake column — fixed (8b86bdc). I also did a proactive audit of the whole inference + asset-resolution path: the remaining cases (CTE-through, INSERT…SELECT, partial multi-source) are missing lineage, not false lineage, and are safe best-effort limitations. |
There was a problem hiding this comment.
1 issue found across 1 file (changes from recent commits).
Prompt for AI agents (unresolved issues)
Check if these issues are valid — if so, understand the root cause of each and fix them. If appropriate, use sub-agents to investigate and fix each issue separately.
<file name="backend/parsers/windmill-parser-sql-asset/src/asset_parser.rs">
<violation number="1" location="backend/parsers/windmill-parser-sql-asset/src/asset_parser.rs:943">
P1: DROP statements ignore the `temporary` flag from sqlparser, hardcoding `is_temporary = false`. This can cause `DROP TEMP TABLE ...` (or similar temporary-drop syntax) to be mis-resolved as an asset write when the name isn't already in `local_table_names`.</violation>
</file>
Tip: Review your code locally with the cubic CLI to iterate faster.
Fix all with cubic | Re-trigger cubic
| self.track_table_definition(name); | ||
| // DROP is a write to the named object; resolve it as an | ||
| // asset if it is one (not a temp-creation context). | ||
| self.track_table_definition(name, false); |
There was a problem hiding this comment.
P1: DROP statements ignore the temporary flag from sqlparser, hardcoding is_temporary = false. This can cause DROP TEMP TABLE ... (or similar temporary-drop syntax) to be mis-resolved as an asset write when the name isn't already in local_table_names.
Prompt for AI agents
Check if this issue is valid — if so, understand the root cause and fix it. At backend/parsers/windmill-parser-sql-asset/src/asset_parser.rs, line 943:
<comment>DROP statements ignore the `temporary` flag from sqlparser, hardcoding `is_temporary = false`. This can cause `DROP TEMP TABLE ...` (or similar temporary-drop syntax) to be mis-resolved as an asset write when the name isn't already in `local_table_names`.</comment>
<file context>
@@ -930,7 +938,9 @@ impl Visitor for AssetCollector {
- self.track_table_definition(name);
+ // DROP is a write to the named object; resolve it as an
+ // asset if it is one (not a temp-creation context).
+ self.track_table_definition(name, false);
}
}
</file context>
Pi ReviewGood to merge — all findings from prior review rounds have been addressed in the fix commits. No new issues introduced. Prior review findings — all resolved
What I verified
Test coverage
|
Codex ReviewGood to merge No issues found in the current diff. Previously raised issues around parse-failure fallback, JOIN resolution, multi-output anchoring, deployed-view draft leakage, local/temp CTAS staging, and Test coverageBackend parser coverage looks solid for the changed logic: annotation parsing/parity, merge precedence, computed and passthrough inference, JOIN inputs, wildcard/subquery skipping, materialize-target scoping, ambiguous multi-output dropping, and temp staging under active Frontend pure-logic coverage covers parser parity and column graph stitching/trace behavior, including materialize-target anchoring and collision-proof node IDs. No Svelte component tests are expected by repo policy. I did not run tests locally for this review. Manual verification should still include the deployed pipeline graph with a DuckDB materializer using |
Summary
Implements column-level lineage for DuckLake data pipelines — parity roadmap gap #5 (
docs/pipelines-vs-dbt.md§3) — and surfaces it in the asset graph.Inferred-first. For DuckDB scripts the lineage is derived automatically from the SQL AST (dbt-style), so no annotation is needed in the common case.
windmill-parser-sql-assetwalks each output-producing query's projection and maps every output column to the source columns its expression reads — passthroughs and computed columns (amount + tax AS total) — resolving each input to its asset via the sameATTACH/alias machinery the asset parser already uses.The
// column <out_col> <- <asset-uri>.<col>[, …]annotation is the override / escape hatch for what inference can't reach: polyglot transforms (Python/TS/Bash — no SQL AST), dynamic SQL (${sql.raw(...)}), or correcting a mis-inferred edge. Inferred and annotated lineage merge per output column with the annotation winning (merge_column_lineage). The annotation is the second extensible annotation family after// data_test(#9708) and follows that exact convention (head-then-tail parse, snake_case serde, full Rust↔TS parser parity via the shared fixture corpus). Lineage is pure metadata — it drives the graph view, never a runtime probe.Scope: column lineage + its graph surface only — no execution, no schema contracts.
Changes
Backend — SQL AST inference (the automatic path)
windmill-parser-sql-asset:infer_column_lineagewalks CTAS /CREATE VIEW/ top-level (managed-materialize) SELECT projections; aColumnIdentCollector(sqlparserVisit) gathers each output expression's identifier leaves, resolved to source-asset columns via a refactoredbuild_from_maps(shared with the existing read-column extraction).parse_assetsmerges inferred lineage with// columnannotations. 4 new tests (computed, passthrough, annotation-override, wildcard).windmill-parser/asset_parser.rs:merge_column_lineage(inferred, annotated)(annotation wins per output column) + test.windmill-api-assets: the graph endpoint runsparse_assetsfor DuckDB pipeline members and surfaces the merged lineage on deployed nodes (other languages fall back to annotation-only). Adds thewindmill-parser-sql-assetdep +languageto the member query.Backend —
// columnannotation (the override, Surface A: both parsers + parity corpus)asset_parser.rs:ColumnLineage/ColumnRef(snake_case serde) onParseAssetsOutput/PipelineAnnotations,// columnparsing + helpers, unit tests.pipeline_annotations.json+pipeline_annotations_parity.rs;windmill-common/assets.rsre-exports.Frontend (parser parity + graph surface)
parsePipelineAnnotations.ts(+.parity.test.ts):ColumnLineage/ColumnReftypes + parsing, behaviorally identical to Rust, asserted against the same corpus.types.ts/resolveGraph.ts:column_lineageon the runnable node, refreshed live from the draft parse.AssetGraphCanvas.svelte+AssetGraphEdge.svelte: a "columns ×N" badge on the producer→materialized-asset write-edge (hover lists each mapping).ColumnLineageView.svelte(new): a column-to-column diagram in the asset details pane, fed byselectionColumnLineagederived in the pipeline+page.svelte.Screenshots
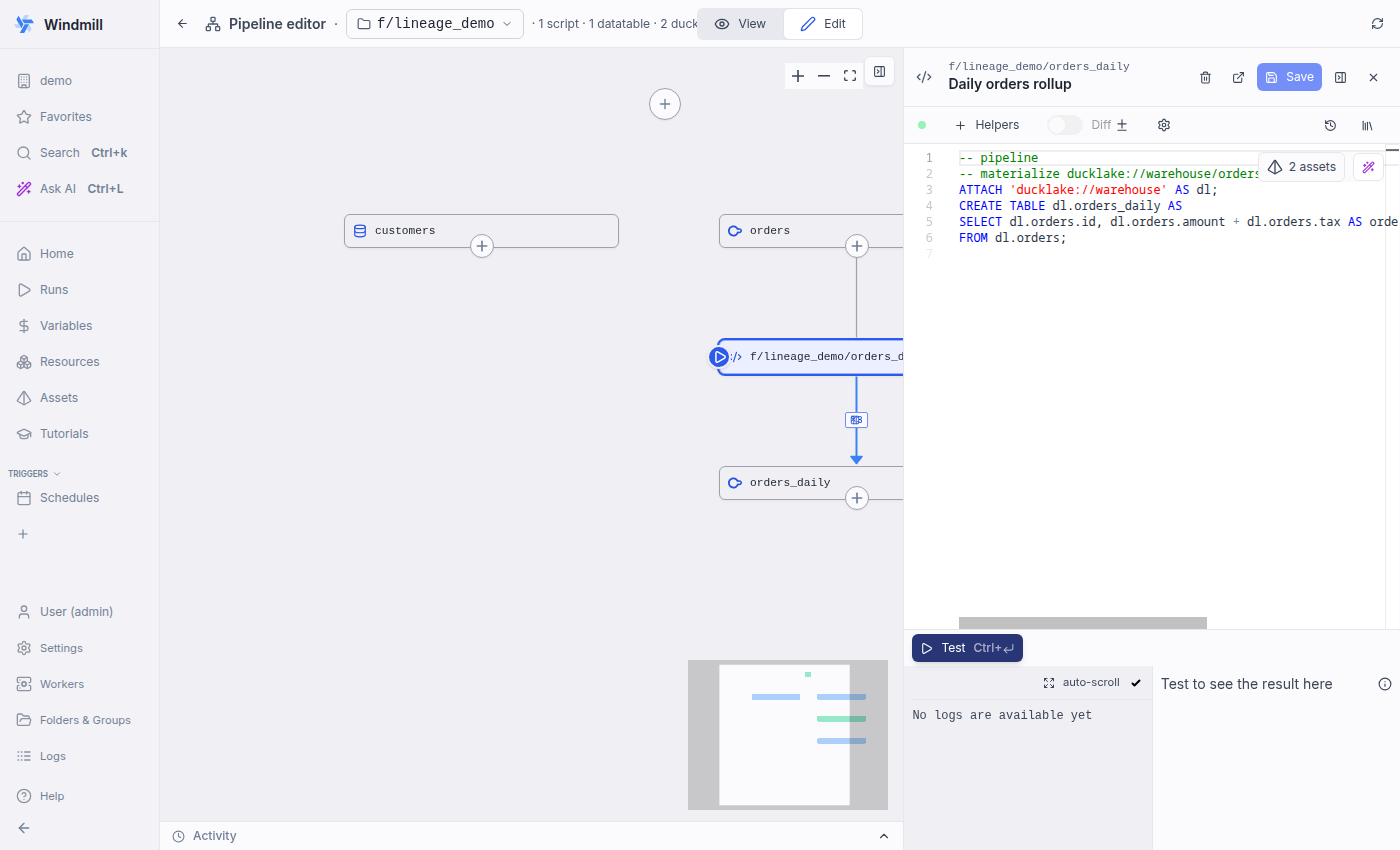
Auto-derived from SQL — no annotation. Script body is
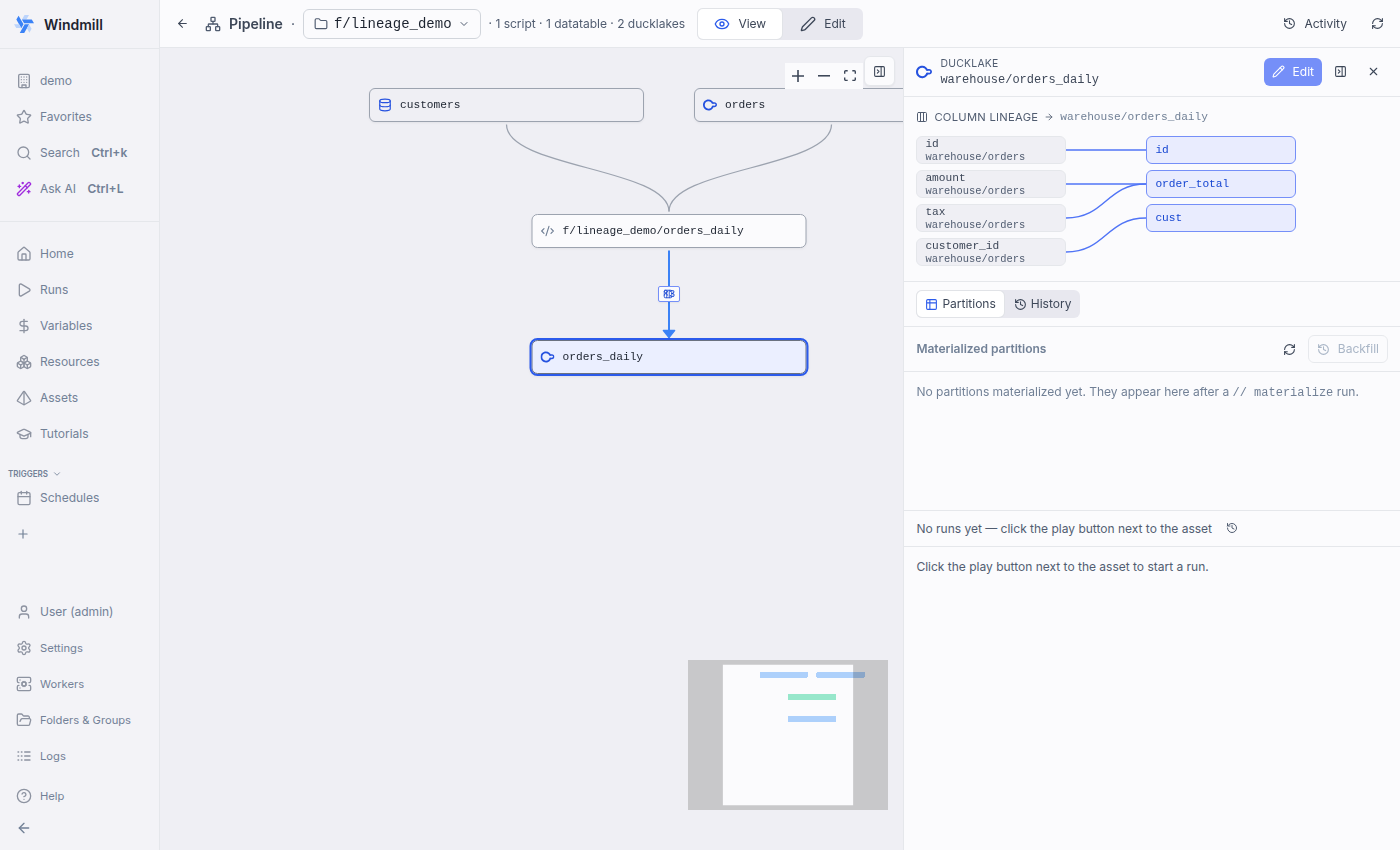
SELECT id, amount + tax AS order_total, customer_id AS cust FROM orders; the diagram is inferred entirely from the AST (noteamount+tax→order_total):Deployed pipeline graph — the "columns ×3" badge on the write-edge (hover lists every mapping):
Column-lineage diagram (with explicit
// columnannotations, the override path):Test plan
cargo test -p windmill-parser -p windmill-parser-sql-asset— 105 + 58 green (incl. SQL inference, annotation parsing, merge, parity)npm run check0 new errors// columnannotation overrides per output column; duplicate-input ref doesn't crash the diagram// columnannotations only — the live preview uses a pinned prebuilt WASM parser that predates this feature; wiring it in is a tracked follow-up. Deployed pipelines are where column lineage matters.🤖 Generated with Claude Code