feat: capture managed-materialize output schema as asset metadata (#2a)#9812
Conversation
After a managed `// materialize` run, capture the producer's output schema via a DESCRIBE folded into the existing one-row summary read (no extra round-trip) and persist it in a new versioned `materialized_asset_schema` sidecar table. This is the producer-side capture that pipeline parity gap #2b (save-time consumer-ref contract enforcement) will read back. - materialized_asset_schema sidecar (asset-level grain), versioned: a new version row is inserted only when the captured column set changes. - output_schema column added to the materialize summary codegen. - worker extracts + records the schema on a successful materialize. - /assets/asset_schemas read endpoint exposing the evolution history. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
Deploying windmill with
|
| Latest commit: |
6e57128
|
| Status: | ⚡️ Build in progress... |
|
Claude finished @rubenfiszel's task in 2m 45s —— View job cc @rubenfiszel Should address issues before merging: captured ReviewClean, well-scoped PR. The sidecar-table design, post-run fold into the existing summary read, advisory-locked monotonic versioning, and best-effort isolation are all sound and well-justified. One correctness concern on the captured contract itself, plus a couple of minor notes. P1 — partitioned assets capture the synthetic
|
| let schema_capture = format!( | ||
| "(SELECT list({{'name': column_name, 'type': column_type}}) \ | ||
| FROM (DESCRIBE SELECT * FROM {target_qualified})) AS output_schema" | ||
| ); |
There was a problem hiding this comment.
P1 — for partitioned assets, the captured output_schema includes the synthetic _wm_partition column.
This DESCRIBEs the target table ({target_qualified}), not the user's output SELECT. For a // partitioned materialize, the managed table is bootstrapped with the extra partition column:
CREATE TABLE IF NOT EXISTS {t} AS
SELECT *, CAST(NULL AS VARCHAR) AS _wm_partition FROM ({sel}) WHERE false;
ALTER TABLE {t} SET PARTITIONED BY (_wm_partition);So DESCRIBE SELECT * FROM {target_qualified} returns the producer's columns plus {"name":"_wm_partition","type":"VARCHAR"}, and every partitioned asset's recorded schema carries that windmill-internal column. Since this is exactly the contract #2b enforcement will read back (MAX(version) = current contract), a consumer that declares only the real producer columns would mismatch on the leaked _wm_partition.
Two options: DESCRIBE the user's output (DESCRIBE SELECT * FROM ({user_select})) instead of the physical table, or filter the partition column out of the captured list. The unpartitioned path is unaffected. Worth confirming this is intentional before it sets the grain #2b depends on.
Pi ReviewGood to merge What I reviewedComplete pass across all 14 changed files: the migration, SQL codegen, worker-side schema extraction, the new Public surface checklist
None of the new public surfaces are half-finished or misplaced — FindingsNo P0 or P1 issues. No P2 nits worth surfacing — the one deliberate naming tension (endpoint Test coverageBackend — well-covered:
Frontend — not touched by this PR. Manual verification — the PR acknowledges that a true e2e exercise requires a |
Codex Reviewcc @rubenfiszel
Test coverageBackend coverage exists for schema versioning and worker extraction. Missing coverage for the API path where a non- Manual verification should cover a managed materialize success and a failed/data-test-failing run for the same asset, then confirm |
There was a problem hiding this comment.
3 issues found across 14 files
Reply with feedback, questions, or to request a fix.
Fix all with cubic | Re-trigger cubic
✅ True DuckLake end-to-end run (manual e2e box now checked)Built the full-featured binary ( Script (
Captured summary row (run 1): [{"materialized":"ducklake://analytics/orders_daily","rows":1,"snapshot_id":1,
"output_schema":[{"name":"order_id","type":"BIGINT"},{"name":"status","type":"VARCHAR"},{"name":"amount","type":"DOUBLE"}]}]
[
{"version":2,"snapshot_id":3,"columns":[{"name":"order_id","type":"BIGINT"},{"name":"status","type":"VARCHAR"},{"name":"qty","type":"INTEGER"}]},
{"version":1,"snapshot_id":2,"columns":[{"name":"order_id","type":"BIGINT"},{"name":"status","type":"VARCHAR"},{"name":"amount","type":"DOUBLE"}]}
]This confirms the three designed behaviors against a real substrate: schema captured post-run, an unchanged re-materialize re-affirms in place (snapshot advances, no version bump), and a real column change bumps the version. The throwaway instance, catalog DB, and MinIO data were torn down afterward. |
…s gate) - exclude the synthetic `_wm_partition` column from the captured schema for partitioned assets, so the recorded contract is the producer's logical output, not Windmill's storage detail (claude/cubic P1). - make the captured column list explicitly ordered (`row_number()` over the DESCRIBE + `list(... ORDER BY)`), so the `list()` aggregate can't reorder columns and spuriously bump the schema version (cubic P2). - gate the API `record_materialization` schema upsert on a `Materialized` status, so a failed/running write (or a client attaching a schema to one) can't advance the schema history (cubic P2). Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
Addressed the CI review in 996b6d9:
|
Pi ReviewGood to merge What I reviewedRe-reviewed the full diff (both commits 69ae09f and 996b6d9) against all 14 changed files, with particular focus on the three issues raised by prior reviewers and the author's fix commit that addressed them. Prior findings — all resolvedThe three items flagged in prior CI reviews are fixed in 996b6d9:
Public surface re-check (post-fix)All new pub surfaces ( AGENTS.md compliance
Test coverage
No new tests needed — the coverage is proportional to the surface changed and the prior review concerns are backed by deterministic assertions. |
Codex Reviewcc @rubenfiszel Should address issues before merging: missing auth contract on new schema helpers Found 2 issues:
Test coverageBackend coverage was added for schema versioning, parser SQL shape, partition-column filtering, and worker extraction shapes. Missing coverage for the manual-materialize path above: a manual materialize result containing an Manual verification should include a managed materialize success that records schema history, plus a manual |
- gate output_schema extraction on the managed (`Some((Some(_), _))`) path so a
`// materialize manual` run — whose result is the user's own query output —
can't persist a caller-shaped `output_schema` into materialized_asset_schema
(Codex P2). Verified e2e: a manual run returning a fabricated
`output_schema:[{injected,EVIL}]` records the partition but writes no schema
version, while the managed path still captures normally.
- document the authorization contract on the new public `record_asset_schema`
and `list_asset_schemas` helpers: they perform no access control (mirroring
the materialized_partition siblings) and require callers to pass a
workspace-authorized executor (Codex P1).
Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
Addressed the Codex review in 356aff3 (pi-review was "Good to merge"):
Verified end-to-end against a real DuckLake (Postgres catalog + MinIO), exactly the scenario Codex flagged as missing coverage:
Manual mode still recorded its partition row ( |
Pi ReviewGood to merge What I reviewedComplete pass across all 14 changed files at the final commit (356aff3): the migration, SQL codegen, worker-side schema extraction, Prior findings — all resolved
Public surface checklist
All placed in the correct module ( AGENTS.md compliance
Test coverage
|
Codex ReviewGood to merge No issues found. Checked for bugs, security, and AGENTS.md compliance. The prior Codex findings are addressed in the current head: schema recording is gated to Test coverageBackend coverage is appropriate for the changed layers: parser coverage for schema SQL generation including partition-column filtering, worker unit coverage for schema extraction shapes, and DB integration coverage for schema version insert/reaffirm/bump/order behavior. Manual verification should still include a real managed DuckLake materialize, a schema-changing rerun, and a failed/data-test-failing run for the same asset, confirming |
Adds a "Schema" tab to DucklakeAssetPanel surfacing the captured output-schema versions persisted by the materialize run. Master-detail (mirrors the History tab): the version list (newest first, newest auto-selected) shows column count + snapshot + capture time; selecting a version renders its column/type table. Reads the GET /assets/asset_schemas endpoint via raw fetch, matching the sibling PartitionStatusGrid convention (these materialization endpoints are not in the generated client). Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
Frontend: schema-history tab on the asset nodeAdded a Schema tab to the ducklake asset node panel ( Verified in a real browser against a live DuckLake (Postgres catalog + local-filesystem storage), driving the deployed v2 selected (current — order_id, status, qty, updated_at): v1 selected (the pre-change schema — order_id, status, amount): Validation: |
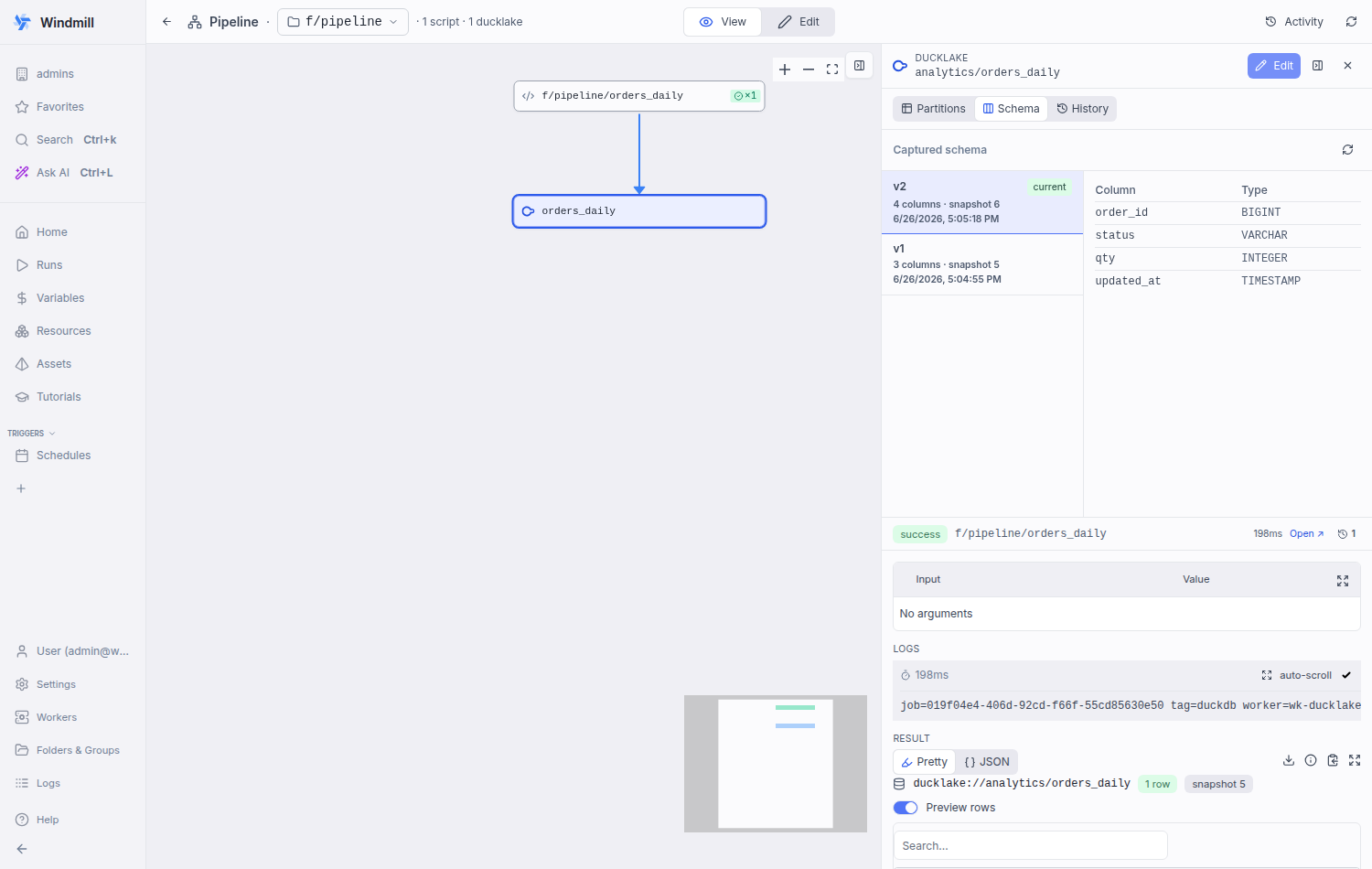
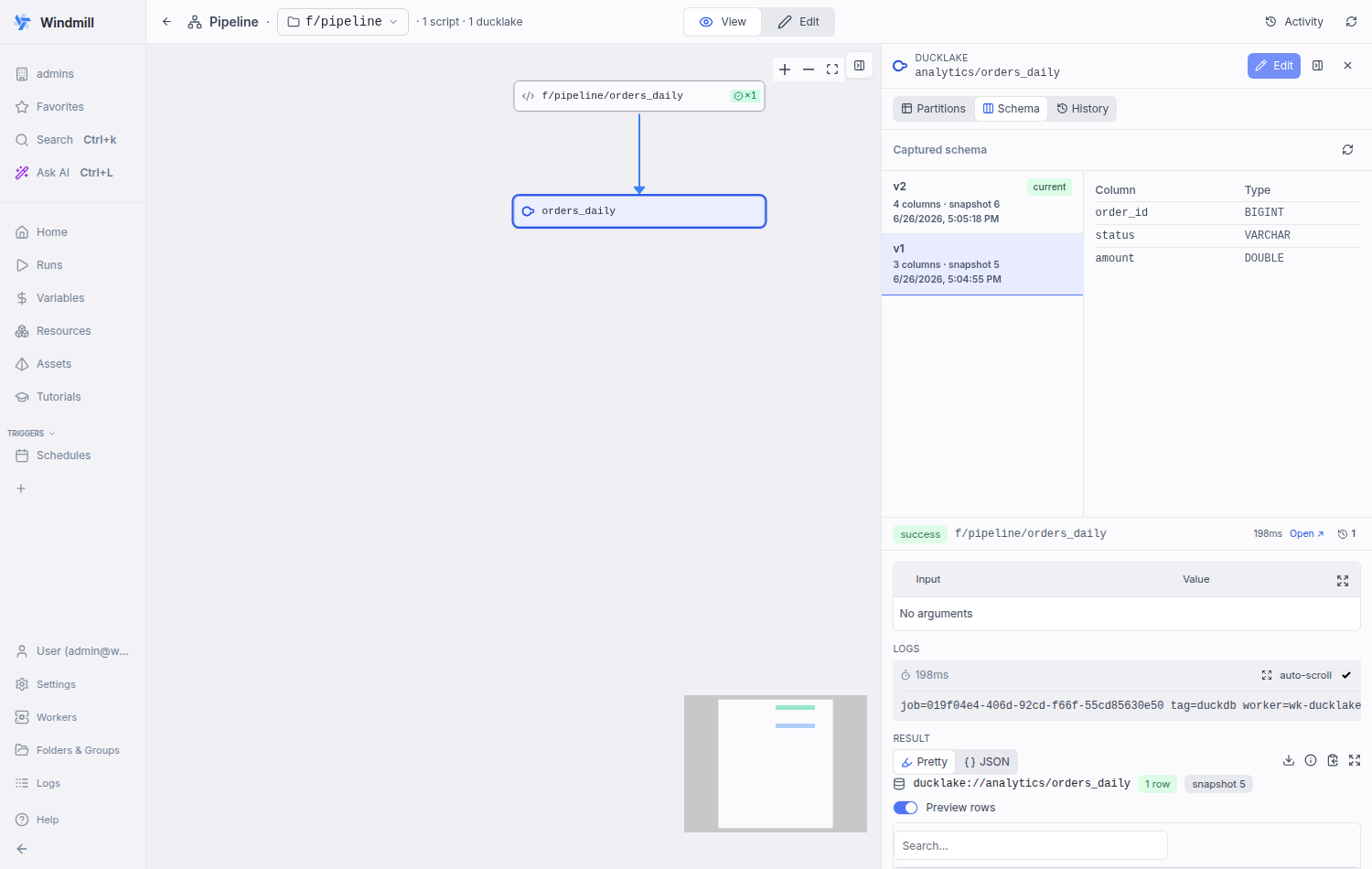
Pi ReviewGood to merge What I reviewedThis PR has been through multiple rounds of CI review (Claude, Codex, Pi) with all findings addressed in fix commits. The latest commit adds frontend changes: a Schema tab on the ducklake asset node panel. I reviewed the new Prior findings — all confirmed resolvedAll five issues from prior CI reviews are fixed in commits
Frontend review (new in
|
Codex ReviewGood to merge No issues found. Checked for bugs, security, and AGENTS.md compliance. Test coverageBackend coverage is strong: parser/unit coverage, worker schema extraction coverage, and DB integration coverage for insert, reaffirm, version bump, ordering, and newest-first listing. Frontend component tests are not generally expected here. Manual verification should cover opening a DuckLake asset node, switching to the Schema tab, and confirming empty and populated schema-history states render correctly. I did not run a dev server or browser verification locally. |
Only a whole-table `replace` producer (CREATE OR REPLACE) can change columns run-to-run; `append`/`merge`/partitioned writes INSERT into a fixed-schema table, so their schema is pinned at first materialize and the "history" framing is degenerate (always one version). - backend: surface the managed `materialize_strategy` (`replace`/`append`/ `merge`) on the asset-graph runnable node, alongside the existing `partition_kind` (same parse-from-annotation path). - frontend: the pipeline page derives `schemaCanEvolve` for the selected asset from its write-producer (`replace` && not partitioned) and threads it to the Schema tab. Evolvable → master-detail version history; fixed → a single current-schema table with a short "schema is fixed" note. Unknown defaults to evolvable so real history is never hidden. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
Schema tab is now strategy-awarePer review discussion: the schema-evolution history only makes sense for a whole-table The backend now surfaces the managed Fixed schema — Evolving schema — whole-table The gate is can the schema evolve (replace && not partitioned), not partitioned-vs-not — an unpartitioned |
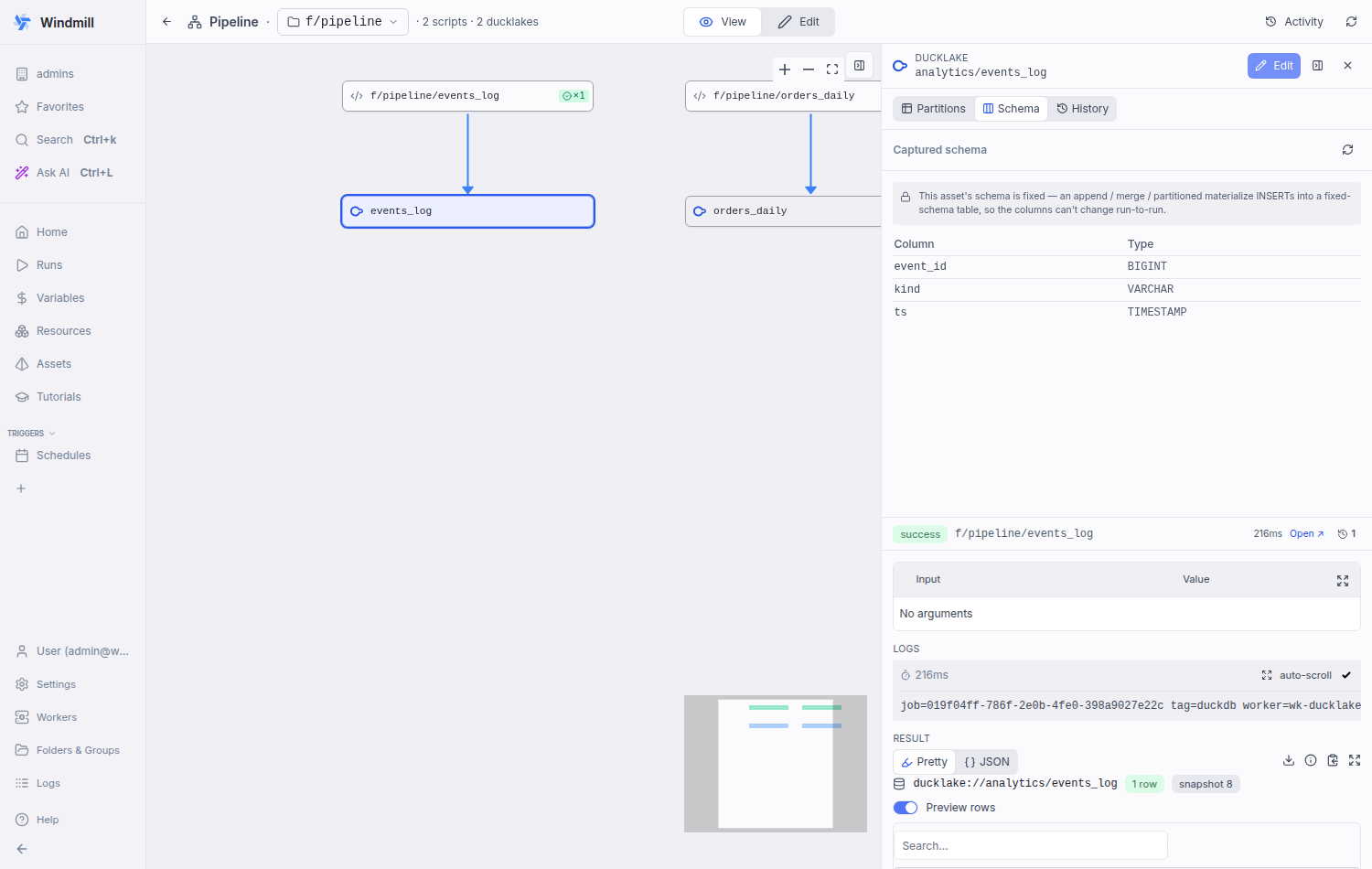
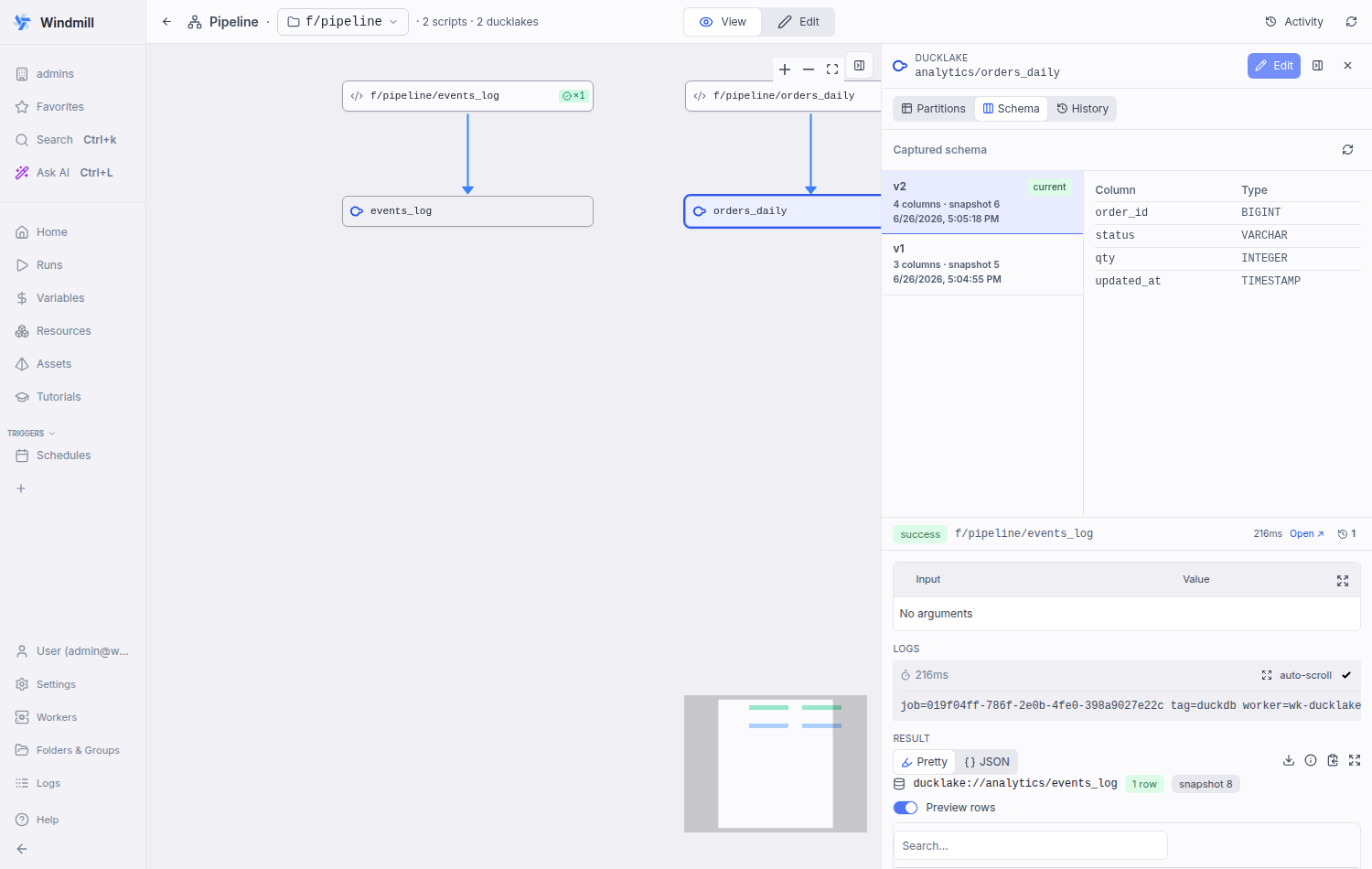
|
I've completed a thorough review of all 19 changed files across the full diff. This PR has been through five prior CI review rounds (Claude, Codex, Pi), with all findings resolved in fix commits Pi ReviewGood to merge Prior findings — all confirmed resolved
Public surface checklist (final commit)
None of the new public surfaces are half-finished — all have callers in the same PR. None are misplaced — all live in the modules that already own the materialization/asset-graph surface. Correctness walkthroughSchema capture SQL (
Worker ( API ( Frontend (
AGENTS.md compliance
Test coverage
No additional manual verification is needed — the PR author has exercised every behavior that requires a real DuckLake substrate. |
Codex Reviewcc @rubenfiszel Mergeable, but should ideally address nits: unknown producer strategy hides schema history
Test coverageBackend coverage looks solid for the new schema versioning helper, parser SQL shape, and worker extraction path. Frontend component tests are not expected here, but if the fix lands in Manual verification should cover a DuckLake asset with multiple captured schema versions and a producer whose strategy metadata is unavailable or draft-derived; the Schema tab should still show the version list rather than the fixed-schema banner. |
There was a problem hiding this comment.
1 issue found across 6 files (changes from recent commits).
Prompt for AI agents (unresolved issues)
Check if these issues are valid — if so, understand the root cause of each and fix them. If appropriate, use sub-agents to investigate and fix each issue separately.
<file name="frontend/src/routes/(root)/(logged)/pipeline/[folder]/+page.svelte">
<violation number="1" location="frontend/src/routes/(root)/(logged)/pipeline/[folder]/+page.svelte:1971">
P2: Producer matching in `schemaCanEvolve` uses path only, ignoring the runnable kind that is part of the asset graph identity; this can match the wrong runnable kind when paths collide across scripts and flows, leading to incorrect schema-tab behavior.</violation>
</file>
Tip: Review your code locally with the cubic CLI to iterate faster.
Fix all with cubic | Re-trigger cubic
| const producerPaths = new Set(selectionProducers.map((p) => p.path)) | ||
| const producers = graphWithDraft.runnables.filter((r) => producerPaths.has(r.path)) |
There was a problem hiding this comment.
P2: Producer matching in schemaCanEvolve uses path only, ignoring the runnable kind that is part of the asset graph identity; this can match the wrong runnable kind when paths collide across scripts and flows, leading to incorrect schema-tab behavior.
Prompt for AI agents
Check if this issue is valid — if so, understand the root cause and fix it. At frontend/src/routes/(root)/(logged)/pipeline/[folder]/+page.svelte, line 1971:
<comment>Producer matching in `schemaCanEvolve` uses path only, ignoring the runnable kind that is part of the asset graph identity; this can match the wrong runnable kind when paths collide across scripts and flows, leading to incorrect schema-tab behavior.</comment>
<file context>
@@ -1958,6 +1958,22 @@
+ let schemaCanEvolve = $derived.by(() => {
+ const sel = selection
+ if (!sel || sel.kind !== 'asset' || sel.asset_kind !== 'ducklake') return true
+ const producerPaths = new Set(selectionProducers.map((p) => p.path))
+ const producers = graphWithDraft.runnables.filter((r) => producerPaths.has(r.path))
+ if (producers.length === 0) return true
</file context>
| const producerPaths = new Set(selectionProducers.map((p) => p.path)) | |
| const producers = graphWithDraft.runnables.filter((r) => producerPaths.has(r.path)) | |
| const producerKeys = new Set(selectionProducers.map((p) => `${p.kind}:${p.path}`)) | |
| const producers = graphWithDraft.runnables.filter((r) => producerKeys.has(`${r.usage_kind}:${r.path}`)) |

Previously a producer present but missing `materialize_strategy` (e.g. a draft-overlay runnable, synthesized without the field) fell through to canEvolve=false, hiding captured history behind the fixed-schema view — contradicting the "unknown defaults to evolvable" intent. Now the fixed view shows only when *every* producer is a known insert-style write (append/merge, or partitioned replace); any producer with unknown (missing) strategy is treated as evolvable, so real history is never hidden. Co-Authored-By: Claude Opus 4.8 <noreply@anthropic.com>
|
Addressed the Codex P2 in 6e57128.
Fixed by failing open: the fixed view now shows only when every producer is a known insert-style write ( |
Summary
Closes pipeline-parity gap #2a — schema capture (the capture half of #2; not #2b enforcement, which depends on #5 column lineage and stays out of scope). After a managed
// materializeDuckLake run, this captures the producer's output schema and persists it as versioned asset metadata — the producer-side foundation #2b will read back to validate consumer references at save time.This is greenfield: #9709 shipped only the time-travel read UX and added no post-run capture seam. It reuses #9709's
DESCRIBE SELECT * FROM …shape but builds its own capture path.It does not re-implement #9708's value-level
data_testchecks (not_null/accepted_values/unique/relationships) — those already exist and are untouched.UI: also adds a Schema tab on the ducklake asset node — a master-detail view of the captured schema versions (column/type per version), reading the new
GET /assets/asset_schemasendpoint. It shows for any ducklake asset with a table (partitioned or whole-table alike, since the schema is table-level); the table-less catalog node renders no tab bar.Design decisions (the three design-open questions)
Where schemas live → a dedicated
materialized_asset_schemasidecar table (keyedworkspace_id, asset_kind, asset_path, version), not a column onmaterialized_partitionand not theassetusage table.materialized_partitionwould duplicate the identical schema across every partition row (a 30-partition backfill writes it 30×).assetusage table).(workspace, kind, path)is exactly what #2b enforcement reads (MAX(version)= current contract).When captured → post-run, folded into the existing one-row materialize summary read (zero extra round-trips).
materialize_result_sqlgains anoutput_schemacolumn:The write has just committed, so the latest snapshot is exactly the recorded
snapshot_id— noAT (VERSION)needed. Captured only for managed mode (we know the target alias+table;manualis skipped) and persisted only on aMaterializedoutcome (a failed run never advances the recorded schema).Versioning across re-materializations → monotonic
versionper asset; a new row only on a real schema change.record_asset_schemacompares the captured column set to the latest stored version: insertsversion = max+1if it differs, otherwise re-affirms the latest row in place (snapshot_id/job_id/captured_at). Serialized per-asset withpg_advisory_xact_lockso concurrent same-asset captures can't both compute the same next version. Result: a compact schema-evolution history. A column reorder counts as a change (the captured list is ordered, andSELECT *consumers see order).Changes
20260626095840_add_materialized_asset_schema— new sidecar table (mirrorsmaterialized_partition:ASSET_KINDenum, FK toworkspace, no RLS) plus explicitGRANT ALL TO windmill_user/windmill_admin(the recurring app-written-table grant-gap pattern —ALTER DEFAULT PRIVILEGESis role-scoped).windmill-common/src/materialization.rs—SchemaColumn,schemafield onRecordMaterializationRequest(#[serde(default)], wire-compatible),record_asset_schema(advisory-locked versioned upsert),list_asset_schemas+AssetSchemaVersion.windmill-parser/src/sql_materialize.rs—output_schemacolumn added tomaterialize_result_sql(a distinct codegen fn; no overlap with chore: lint the frontend and the python-client codebase #5's annotation-parser edits).windmill-worker/src/duckdb_executor.rs—extract_schema(tolerant of nested-array / string-encoded FFI shapes) + threads the captured schema throughrecord_mat→record_asset_schemaon the successful path only; schema recording is its own best-effort transaction that can never fail the materialize run.frontend/.../AssetGraph/SchemaHistoryPanel.svelte+DucklakeAssetPanel.svelte— new Schema tab (master-detail schema-version history) on the asset node; raw-fetchGET /assets/asset_schemas, mirroring the siblingPartitionStatusGrid. Verified in a real browser (screenshots in PR comments).windmill-api-assets/src/lib.rs—GET /assets/asset_schemasread endpoint + therecord_materializationhandler now upserts the schema (in its own transaction, after committing the partition record, so a schema failure can't roll the partition record back).Notes / boundaries
windmill-api-assets/src/lib.rs— is touched only in new/distinct functions./partitions,/record_materialization) are consumed via rawfetchand are deliberately absent fromopenapi.yaml;/asset_schemasfollows the same convention.agent_workers/.../record_materialization, an EE-symlink handler) is left untouched, so agent-worker materializes won't persist schema in v1 — keeps this PR OSS-only. Theschemarequest field is in place for the server-worker and SDK-polyglot paths.Test plan
cargo check—windmill-common,windmill-parser,windmill-api-assets,windmill-worker --features duckdb, and full--features all_sqlx_features(via sqlx prepare) all compile.output_schemafold present in both tests and no-tests summaries.extract_schemaparses nested-array, string-encoded, and absent (None) shapes.windmill-common/tests/asset_schema_capture.rs, real migrated DB): first-insert → v1, unchanged → re-affirm (no new version, snapshot advances), changed → v2 newest-first, column-reorder → new version.(SELECT list({...}) FROM (DESCRIBE SELECT * FROM t))returns exactly[{"name":..,"type":..},…](the shapeextract_schemaparses).duckdb-featured worker + ducklake target — not runnable on the quickjs-only dev backend here): run a managed// materialize, change the model's output columns, re-run, and confirmGET /w/:id/assets/asset_schemas?path=<ducklake>/<table>returns the history newest-first withversionbumping only on real column changes.🤖 Generated with Claude Code
Summary by cubic
Captures the output schema of managed DuckLake
// materializeruns and stores it as versioned asset metadata to support future contract enforcement (issue #2a). Adds a schema read API and a strategy-aware "Schema" UI tab; only managed, successful runs can advance schema history, and unknown producer strategy defaults to “evolvable” so history isn’t hidden.New Features
materialized_asset_schemakeyed by workspace/kind/path +version; insert only when columns change (order counts); exclude_wm_partition; explicitly order columns.manual); upsert only onMaterialized; best-effort in its own transaction with a per-asset advisory lock; tolerant of nested/string JSON shapes.GET /assets/asset_schemaslists versions newest-first;POST /record_materializationupserts schema only onMaterializedand in a separate transaction; wire keepsschemaoptional for older clients.materialize_strategy(replace|append|merge) on runnable nodes.replace, or a single fixed-schema view forappend/merge/partitioned assets; fails open when producer strategy is unknown (treat as evolvable). Backed byGET /assets/asset_schemas.Migration
materialized_asset_schematable with grants (run20260626095840_add_materialized_asset_schema).Written for commit 6e57128. Summary will update on new commits.