feat: support compress public inputs#55
Conversation
499e27c to
537d997
Compare
| raw_public_inputs: [Column<Advice>; 32], | ||
| compressed_public_inputs: [Column<Advice>; 32], |
There was a problem hiding this comment.
Was there a specific reason you chose to store 32 bytes/row? In any case, like I said on the call, decoding one Huffman encoded word/row makes more sense to me and should be sufficient. With 32 bytes per row in the worst case we'd have to do a lookup/bit to decode the data which would mean 32*8=256 lookups!
There was a problem hiding this comment.
I think we need to split origin_rpi's row into 32 rows, u256 -> [u8;32], can I treat the Filed in oirigin_rpi as a u256?
Using 32bytes/row is easy to constraint between the origin raw public inputs and split raw public inputs, just compare the combined 32byte data and origin_rpi row
But now, I have no sense to constraint between them if we use the u8/row, so I need help.
| orpi | rpi |
|---|---|
| rpi[0] | rpi[0][0] |
| rpi[1] | rpi[0][1] |
| rpi[0][2] | |
| ...... | |
| rpi[1][31] |
orpi: origin raw public inputs
rpi: split raw public inputs(into bytes stream
There was a problem hiding this comment.
With 32 bytes per row in the worst case we'd have to do a lookup/bit to decode the data which would mean 32*8=256 lookups!
Now, we just encode the raw_public_inputs, and compare with compressed_public_inputs from l1 constract.
So, we lookup code by value(byte)
There was a problem hiding this comment.
I would say don't worry too much about getting all the 32 bytes on a single row again for now (this will still change when the circuit switches to keccak which is also byte based). But the mechanism it the same as you'll need to collect the (un)compressed data stream to check if it matches the original data stream. Whether you see it as encoding (variable number of compressed bits/row) or decoding (variable number of processed bits/row) you'll have to somehow collect those bits/bytes over multiple rows. So you just use the rlc trick with some extra logic.
So the easy example is like this, where on each row simply a single byte is added to the rlc:
| data | acc |
|---|---|
| byte[0] | acc = byte[0] |
| byte[1] | acc = (acc, rot::prev()) * r + byte[1] |
| byte[2] | acc = (acc, rot::prev()) * r + byte[2] |
| .... | .... |
| .... | data_rlc |
At the end you get the data_rlc which it the encoding of all bytes. However, for the compression part or even if the circuit has to consume multiple bytes per row (like needing 32 bytes on some rows) the logic just gets a bit more complicated. On some rows you add 32 bytes to acc, on other row you may not add any bytes to it. For the compression/decompression circuit you may even have to do this on the bit level where you only want to add a couple of bits to the rlc (depends on the implementation because you can also think of ways to keep the rlc accumulation on the byte level). At the end though you'll have to end up with a value that is equal to data_rlc, so that's simply a check you add at the bottom of the circuit.
Now, we just encode the raw_public_inputs, and compare with compressed_public_inputs from l1 constract.
So, we lookup code by value(byte)
Ah yes that would indeed mean only up to 32 lookups. That' still a lot though (no way around this many lookups for some circuits but here seems pretty inefficient to require that).
There was a problem hiding this comment.
I'm sorry, I didn't make it clear, I want to say that how can I constraint the txlist between the tx_table's format and the raw_public_inputs(byte/row)'s format
There was a problem hiding this comment.
- The tx field in
tx_tablemaybe has been rlc encoded, but theraw_public_inputsthat will be compressed into txlist doesn't have rlc encoded fields - The same tx field of txlist in
tx_tablehas been put which is easy for using rotation
|
Starting some discussion on how to do RLC calculation with words of variable number of bits. Here are some possibilities which work but don't look optimal yet but it's a start and they are pretty simple. Do RLC over bitsEasy, but needs a lot of columns because each bit needs to be stored separately. So does not scale very well, especially if codewords can get large. Do RLC over N-bit parts using lookupsThere's quite a few different cases that aren't that easy to implement directly using custom gates (or the implementation would require extra cells as well to do equality checks). Instead we can just hard-code all possible cases in a table and then lookup the correct way to combine the different parts. The inputs are
The outputs are (per part!, but in a single lookup over a lot of columns):
There is another output of the number of bits modulo 8 of the resulting bitstream. (some of the values above may be redundant and maybe could be eliminated, also for some custom gates can be used instead but may require a high degree so just reading from the lookup table is perhaps not so bad. Some data can also be skipped for the "middle parts" e.g. Even if the coded words can get very large, this table is very small (in height): for a max word size of 32 we only need to store 8*32 = 256 rows in the table. The table is quite wide though because we need to store 4 values/part. For each part we of course also have to store the actual data, so in total we need to store 5 values per part (4 of which come from the lookup above). We can then loop over the parts like this: Note that if This method doesn't make a lot of sense when we do the rlc over bytes because we still quite a few columns. However, when do the rlc over 16-bit values (which we can definitely do because the required lookup tables for this are still quite small, needs ~2**17) this methods starts to pay off and is pretty efficient. |
|
Here is my example: circuit layout and assignment
explain:
|
|
Nice! One question I have when looking at your table, are you planning to process a single part per row? I was thinking of just doing all parts on a single row because it's a bit easier, but doing a part/row also works for me. The only downside I think is that we don't decode a single byte/row anymore so the data is more spread out, but I don't immediately see an issue with that. |
I see, you mean that all 4 parts in one cell, because the max num_bits <= 32, so we can use one Cell(31bytes) represent all parts, each part in 4bytes(32bits) Cell layout
I think it's more efficient, let's take this approach |
|
I don't think that is possible because we do have to check that each part is within the allowed range of bits (we cannot do a range check for 32 bit number, that would require a circuit with height >= 2**32). I just meant doing mostly what you did, but instead of using |
Sorry, I misunderstood it. I found it doesn't work when use 4parts/cell(split cell and combine cell is complex |
c7f1182 to
73ab9c9
Compare
73ab9c9 to
7b6a67a
Compare
| CompressCircuitConfigArgs { randomness }: Self::ConfigArgs, | ||
| ) -> Self { | ||
| let q_enable = meta.selector(); | ||
| let word_begin = meta.advice_column(); |
There was a problem hiding this comment.
I think this can be fixed, because it's just set to true every MAX_PARTS rows. If it's fixed you don't need to do a boolean constraint on the value, if it's an advice column you'd have to add a boolean constraint and have additional constraints to only set it to true every MAX_PARTS rows, so a lot more to check.
| // 3. num_bits0 + num_bits1 + num_bits2 + num_bits3 = huffman_code_length | ||
| let input = meta.query_advice(input, Rotation::cur()); | ||
| let code = decode::data_expr(&parts); | ||
| let word_begin = meta.query_advice(word_begin, Rotation::cur()); |
There was a problem hiding this comment.
| let word_begin = meta.query_advice(word_begin, Rotation::cur()); | |
| let q_word_begin = meta.query_fixed(word_begin, Rotation::cur()); |
When it's a fixed selector using q_ prefix makes that more clear.
| meta.create_gate("do RLC over parts", |meta| { | ||
| let mut cb = BaseConstraintBuilder::new(MAX_DEGREE); | ||
| cb.condition(meta.query_advice(word_begin, Rotation::cur()), |cb| { | ||
| let mut data_rlc_prev = meta.query_advice(data_rlc, Rotation::prev()); |
There was a problem hiding this comment.
| let mut data_rlc_prev = meta.query_advice(data_rlc, Rotation::prev()); | |
| let mut data_rlc_expr = meta.query_advice(data_rlc, Rotation::prev()); |
Or some other name, data_rlc_prev is a bit confusing because it gets updated in the loop so then it's not the previous rlc anymore.
| // part.r_multi(bool) | ||
| // part.shift_factor(0..2^32) 2.pow(0..32) | ||
| // part.decode_factor(0..2^32) 2.pow(0..32) | ||
| cb.require_boolean("r_multi", part.r_multi.clone()); |
There was a problem hiding this comment.
If you add the lookup as you described in the comments, r_multi will be checked by the lookup so you won't need to check it's boolean using a custom gate, the lookup table will only contain 0 or 1 for the values so the check is already done by the lookup.
| let mut shift_factor = 0; | ||
| let mut decode_factor = 0; | ||
|
|
||
| if code_len != 0 { |
| // + data3 * decode_factor3 = huffman_code | ||
| // 3. num_bits0 + num_bits1 + num_bits2 + num_bits3 = huffman_code_length | ||
| let input = meta.query_advice(input, Rotation::cur()); | ||
| let code = decode::data_expr(&parts); |
There was a problem hiding this comment.
As you're doing the part/row route, you'll have to be careful to correctly construct your table to return the correct data for each row between 0..MAX_PARTS. Perhaps you'll need to add some row_id to the lookup table or something like that. For example, because you're planning to decode the parts like data0 * decode_factor0 + data1 * decode_factor1 + data3 * decode_factor3, decode_factor may be row dependent, though not sure. Also the decoding could perhaps be done differently so this isn't necessary.
|
Because of the Rotaion::prev() is not woring in row zero, so I will reversal the table just like pi_circuit do. |
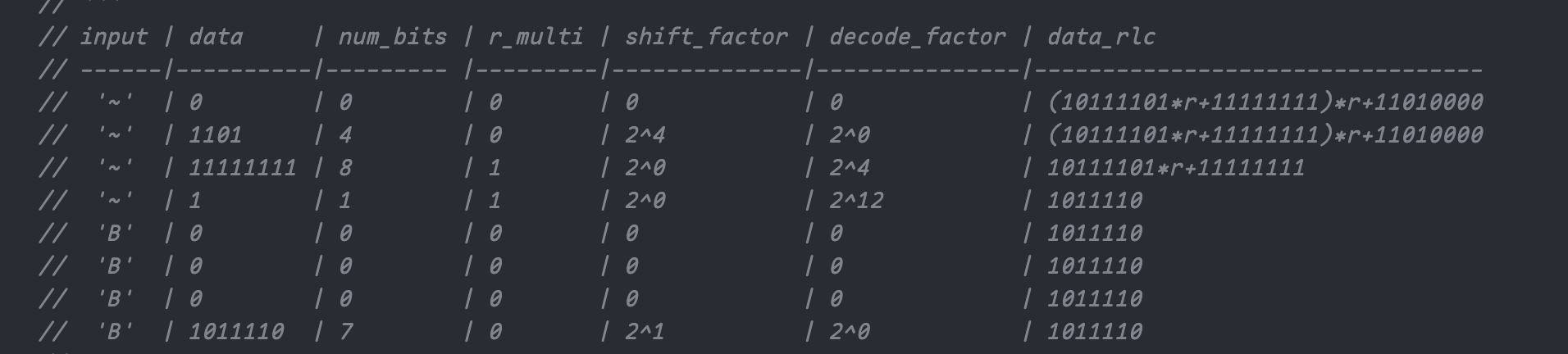
|
Another way around |
1e06a66 to
d9e82ac
Compare
a2b2b0a to
1c00b99
Compare
| macro_rules! range_check { | ||
| ($column:ident, $range:ident) => { | ||
| meta.lookup(concat!(stringify!($column), " range check"), |meta| { | ||
| let column = meta.query_advice($column, Rotation::cur()); | ||
| let q_enable = meta.query_selector(q_enable); | ||
| vec![ | ||
| ( | ||
| q_enable.clone() * FixedTableTag::$range.expr(), | ||
| fixed_table[0], | ||
| ), | ||
| (q_enable * column, fixed_table[1]), | ||
| ] | ||
| }); | ||
| }; | ||
| } | ||
|
|
||
| range_check!(input, Byte); | ||
| range_check!(data, Byte); | ||
| range_check!(num_bits, Range32); | ||
| range_check!(r_multi, Bool); | ||
| range_check!(shift_factor, Exponent8); | ||
| range_check!(decode_factor, Exponent32); |
There was a problem hiding this comment.
Hmmm so not sure I understand why you do it like this. Shouldn't this be a single lookup into a specifically created table? Because this will simply check that each value separately is in the correct range, but this will not check that all values together are the correct values to use for the current state no? Or how are you planning on checking that these values are the ones necessary (e.g. 5 bits are already used, we decode a word with 2 bits so we need to add these 2 bits to the data stream multiplied by 2. These values are all interconnected and so if you put them all in a single table and lookup all values together you know all of them are correctly set and in the expected range, using a single lookup).
There was a problem hiding this comment.
Yeah, you're right. So, I need check some ranges through all parts of one word
There was a problem hiding this comment.
Because I have check the data(decode_factor)/num_bits in "lookup huffman table". So I only needs to check the input/r_multi/shift_factor
There was a problem hiding this comment.
I still don't really understand. For example shift_factor, how do we verify it's the correct value in the circuit? Using my example above:
5 bits are already used, we decode a word with 2 bits so we need to add these 2 bits to the data stream multiplied by 2.
How does the circuit verify that shift_factor needs to be 2 in this case? Any other value would not create the correct rlc encoding of the data stream. It seems to me the prover could currently supply e.g. 1 which should not be valid.
| self.q_not_end.enable(&mut region, offset)?; | ||
| } | ||
|
|
||
| macro_rules! assign_part { |
TODOs:
use 32 bytes per rlc item in compressed public inputspi-circuit export compressed public inputs from compress-circuit