{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Natural language processing (NLP) is an important tool in language analysis. NLP is used across disciplines, such as computer science, engineering, mathematics, linguistics and psychology (Chowdhury, 2003). Its applications include speech recognition and text to speech processing, syntactic analysis and relational semantics, and often involve artificial intelligence and machine learning (Hirschberg and Manning, 2015). The goal of NLP is to allow machines to more accurately understand human language in spite of the numerous complexities and contextual nuance (Chowdhury, 2003; Hirschberg and Manning, 2015). This report will demonstrate how NLP can be used to develop content-based recommender systems in the context of recommending resources to different university courses. The report will demonstrate the ability of a cosine similarity and a k-means recommender system to suggest course material to similar subjects, assess their effectiveness and endorse the cosine similarity recommender as the most appropriate for the task.
Natural language is problematic for computers to decipher because of the dynamic nature of human communication; language can be ambiguous and variable, depending on context, dilalogue and colloquialism (Hirschberg and Manning, 2015; Nadkarni et al, 2011). Therefore, the process of extracting meaning from text is subject to a complex series of rules and constraints, but these are often, paradoxically, flexible in everyday language (Nadkarni et al, 2011). The problem of human-machine understanding becomes complicated, because words can have a different meaning, depending on context, outside of their official definition; ‘My house is a dump’ does not mean ‘my house is a refuse tip’, but rather, ‘my house is a mess’ (Hirschberg and Manning, 2015). There are several processes involved in natural language processing, each described below:
- Tokenisation and sentence segmentation/ Lexical analysis: The preliminary stage of identifying and segregating words and punctuation within a sentence (Nadkarni et al, 2011). This stage also involves classifying sections of a string of characters (Indurkhya and Damerau 2010).
- Syntactic analysis, or parsing: Analysis of a string to determine its grammatical and syntactic structure, and correctness (Hirschberg and Manning, 2015).
- Semantic analysis: Interpretation of bodies of text by analysing grammatical structure and the relationships between words, given the context (Wolff, 2020).
- Pragmatic analysis: Extracting information from text using external knowledge Indurkhya and Damerau 2010).
Each of these steps brings a computer closer to correctly identifying the intended meaning behind a statement.
The aim of this report is to develop two NLP recommendation systems to suggest reading material to different courses from within a university’s corpus of resources. Two unsupervised methods will be tested:
- First, clustering using cosine similarity.
- Second, clustering using k-means analysis
The dataset provided for this analysis comprised 68,530 records of book titles, their authors, publication date and other data, as well as the course(s) in which they are listed as reading material and the university to which each course belongs. The variables are shown in Table 1.
The data provided were in .xlsx format and were converted to .csv format prior to importing. The dataset was incomplete, with ‘cross-contamination’ of variables throughout. Notably, author data (while sparse) were located in an unnamed column at the far right of the dataset, while the ‘Authors’ column was filled with numbers.
Table 1: List of variables and description for provided dataset.
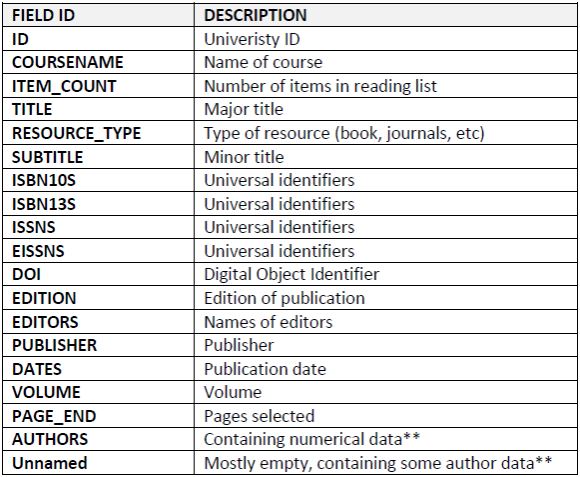
** There was considerable cross-contamination of variables and missing data.
A considerable amount of data cleaning was required, due to the incompleteness of data within the dataset. The first step in the data cleaning process was to remove columns that contained extremely sparse and unreliable information. This reduced the size of the dataset to a more manageable six columns.
Each of the remaining columns (ID, COURSENAME, TITLE, SUBTITLE, AUTHORS and DATES) was evaluated for consistency and quality. Some columns were renamed to improve consistency and to make them more descriptive (e.g. ID became UNI_ID). NaN values were converted to blank fields using df.fillna(). Extraneous quotation marks, apostrophes, commas, colons and other special characters were removed. RESOURCE_TYPE entries were standardised.
Where BOOK_TITLE and SUBTITLE columns did not contain identical information, they were merged to form the new BOOK_TITLE column. Non-alphabetical characters were removed from PUBLISHER data, and non-numeric characters were removed from PUBLICATION_YEAR, as well as invalid data from PUBLICATION_YEAR (values where the length of the value was not equal to 4).
Finally, all data were converted to lower case, all duplicate values in TITLE were dropped from the dataframe and a subset of data based on the number of titles associated with each course was generated, to be used for the analysis. Table 2 shows the remaining variables.
Table 2: Variable retained for analysis (prior to enrichment).
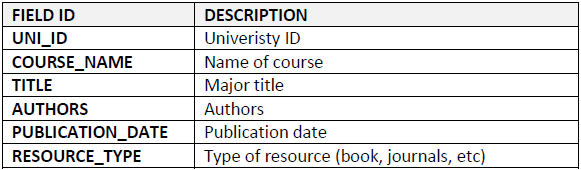
Because the aim of this report is to recommend a title to a different course, it is necessary to remove titles and courses where there is a low number of co-occurrence and therefore not enough data with which to make predictions. This was achieved by subsetting the cleaned dataframe by grouping by COURSE_NAME and sorting by the number of titles associated with each course. Courses with fewer than ten associated titles were excluded from the subset, which reduced the dataframe to 29,933 records.
# Subset titles by course to remove courses that do not have enough data to be helpful and
to minimise dataset size
subset = df.groupby(["COURSE_NAME"]).count().sort_values(["TITLE"], ascending =
False).reset_index()[['COURSE_NAME','TITLE']]
subset_list = list(set(subset[subset['TITLE']>10]['COURSE_NAME']))
ss = df[df['COURSE_NAME'].isin(subset_list)]
The construction of a recommender system and subsequent analysis was performed using Python version 3.9.2. The following packages were used: Pandas Numpy Shutil Tempfile Quote BeautifulSoup Requests
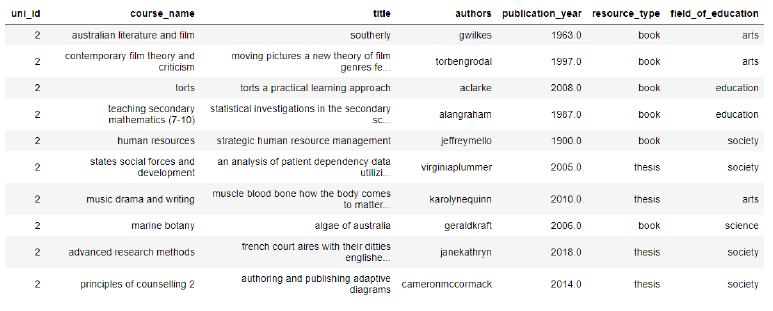
Field of education data were derived from the Australian government’s HEIMSHELP ‘field of education’ webpage (Australian Government, 2021). The data were combined using a combination of web-scraping using BeautifulSoup and manual editing in Microsoft Excel. Some other common field-related keywords were added, which made this process slightly subjective and this is acknowledged in the discussion and recommendation sections of this report. Titles that could not be assigned a field of education were dropped from the dataframe. Table 3 contains a random sample (n=10) of the resource_catalog dataframe, with field of education included.
Table 3: resource_catalog.sample(10)
The data provided were not considered sufficient to allow predictions to be made in accordance with the aim stated above. In order to use it, it was necessary to supplement, or enrich the dataset using an API. Trove API was selected, and it was possible to use the BeautifulSoup Python package to navigate through each query to extract title, author, date resource type data.
Output showing all the unique titles was generated. Each unique title was used as a query to search through the Trove API for data to fill the sparse dataset. A for loop was used to extract the book_title, authors, publication_year and resource_type data from the API, which was then used to cleaned in accordance with the data cleaning methods above, where necessary. The following code shows the process of scraping the API html data.
# Define filename and headers for csv file to contain scraped data
filename = "A2_scrape.csv"
f = open(filename, "w", encoding="utf-8")
headers = "query, book_title, authors, publication_year, resource_type\n"
f.write(headers)
# Loop through titles and use title as search query within API
for title in unique_title:
to_fetch =
"https://api.trove.nla.gov.au/v2/result?key=gb965r233jntfbgl&zone=book&q="+quote(title)
with urllib.request.urlopen(to_fetch) as response:
try:
page = requests.get(to_fetch)
soup = BeautifulSoup(page.content, 'html.parser')
children = list(soup.children)
# Collect data from html page (first match to search query)
query = list(soup.children)[1]
zone = list(query.children)[1]
records = list(zone.children)[0]
workid = list(records.children)[0]
book_data = list(workid.children)
book_title = book_data[1].get_text()
authors = book_data[2].get_text()
publication_year = book_data[3].get_text()
resource_type = book_data[4].get_text()
except:
book_title = 'null'
authors = 'null'
publication_year = 'null'
resource_type = 'null'
# Write extracted data to csv beneath headings
f.write(to_fetch + ',' + book_title.replace(",","") + ',' +
authors.replace(",","") + ',' + publication_year.replace(",","") + ‘,' +
resource_type.replace(",","") + '\n')
f.close()
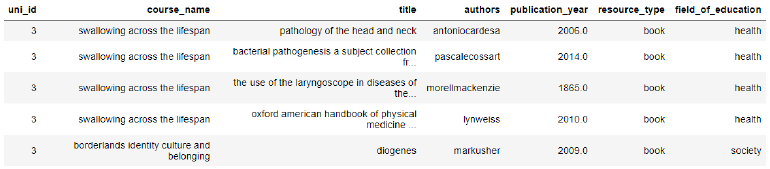
The final dataset includes the scraped data combined with the ‘UNI_ID’ and ‘COURSE_NAME’ data from the subset of the provided dataset. This dataset was named ‘resource_catalog’, containing 24,755 records and 6 variables, and was used for the NLP recommenders. Table 4 shows the first five rows of this dataset.
Table 4: resource_catalog.head(5)
Due to the nature of the dataset, both NLP recommenders generated for this report are content-based, meaning that they rely on the calculation of similarity between items. In this case, the items are course resource titles contained within strings of text in the ‘title’ column.
Unsupervised learning in Natural Language Processing aims to divide a set of objects into clusters, based on their calculated ‘distance’ from one another (Nadkarni et al., 2011). Those data which are closest together form a cluster and are therefore most similar. This kind of learning is ideal for recommender systems, and the following examples both make use of clustering to determine similarity.
Supervised learning, on the other hand, consists of training a using a dataset that already contains the ‘correct’ answer, in order to group objects into known and predetermined categories (Nadkarni et al, 2011). This kind of learning will be used to assess the effectiveness of the NLP recommenders.
Before developing each recommender system, the TfIdf module was imported from the scikit-learn library, and a TF-IDF (Term Frequency – Inverse Document Frequency) matrix of dimensions 24755*15736 was constructed using TfIdfVectorizer, removing English stop words and fitting and transforming the ‘title’ data. This means that there are 15736 distinct vocabularies in the dataset of 24555 titles. TF-IDF weighs the frequency of a term (TF) within a corpus and multiplies the result by the inverse document frequency (IDF) which reduces the weighting of common but less useful terms like ‘the’ within a phrase (Goel, 2018). The TF-IDF is calculated using
𝑇𝐹 − 𝐼𝐷𝐹 = 𝑇𝐹 ∗ 𝐼𝐷𝐹
where
𝑇𝐹 = 𝑛 𝑡𝑖𝑚𝑒𝑠 𝑎 𝑤𝑜𝑟𝑑 𝑜𝑐𝑐𝑢𝑟𝑠 𝑖𝑛 𝑡𝑒𝑥𝑡 / 𝑇𝑜𝑡𝑎𝑙 𝑛 𝑤𝑜𝑟𝑑𝑠 𝑖𝑛 𝑡𝑒𝑥𝑡
and
𝐼𝐷𝐹 = 𝑛 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑠 / 𝑛 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑠 𝑐𝑜𝑛𝑡𝑎𝑖𝑛𝑖𝑛𝑔 𝑤𝑜𝑟𝑑
#Remove all english stop words and assign to tfidf vector
tfidf = TfidfVectorizer(stop_words='english')
# fit/transform data and assign to tfidf matrix
tfidf_matrix = tfidf.fit_transform(resource_catalog['title'])
# Print tfidf_matrix shape
tfidf_matrix.shape
(24755, 15738)
cosine_sim.shape
(24755, 24755)
The first recommender system takes an existing title as input, and makes use of a cosine similarity matrix to find the ten most similar titles and print the corresponding course name for each of these. Cosine similarity calculates the similarity between two items (A and B) and can be written as follows:
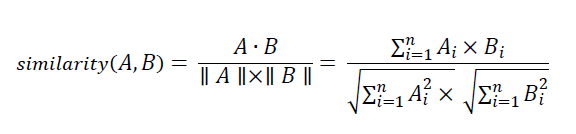
For the resource_catalog dataset, the linear_kernel() function from the sklearn package used the TF-IDF matrix constructed in section 5.3, which gives the cosine similarity score by calculating the scalar product between each vector of that matrix (Sharma, 2020).
In order to allow the system to identify the index of any title, the ‘title’ column was indexed as a series, so that the index of a given title would match its position within the resource_catalog dafatrame. Finally, the function to recommend a title to a course is as follows:
def get_recommendations(input, cosine_sim=cosine_sim):
# Get the index of the title that matches the input
index = indices[input]
# Get the pairwsie similarity scores of each titles with input
similarity = list(enumerate(cosine_sim[index]))
# Sort the titles based on the similarity scores
similarity = sorted(similarity, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar titles and their indices
similarity = similarity[1:11]
title_index = [i[0] for i in similarity]
# Return course names corresponding to the top 10 most similar titles
return resource_catalog['course_name'].iloc[title_index]
str_input = input(">>>")
get_recommendations(str_input)
For comparison, an alternative recommender system was developed. This time, via a kmeans clustering analysis. The k-means analysis works by grouping items by comparing their similarity to a predefined number of centroids; each data point is grouped to the nearest centroid, eventually forming clusters around these centroids (Goel, 2018).
The main problem to solve with regards to k-means clustering is to determine the number of centroids (k) for the analysis. For this analysis, a value of 350 centroids (true_k) was chosen, as a result of a trial-and-error process. The elbow method of determining k was intended, however even using a small sample of the dataframe, it was too time and memory-intensive to produce an elbow plot and in any case there were too many clusters for a distinct elbow to appear on a plot. Therefore, a random sample of 3000 records was used and different k values were input to the model until clusters were objectively uniform. There was considerable overlap between clusters < 300 and too much distinction between clusters > 400. Therefore, a value of 350 was chosen for k.
In order to assist the clustering process, the algorithm was run on words within a combined string of ‘course_name’ and ‘title’, denoted ‘course_id’. It was hypothesised that this would help to keep titles from the same course within the same cluster.
The following code shows the process of fitting the model using the TF-IDF matrix generated in section 5.3, and getting the centroid and feature data:
true_k = 350
# Running model with 15 different centroid initializations, 500 max iterations
model = KMeans(n_clusters=true_k, init='k-means++', max_iter=500, n_init=15,
random_state=100)
model.fit(X)
The code below allows the user to input a title and receive a prediction on the cluster to which it belongs:
def recommend_util(str_input):
# match on the basis of course-id
temp_df = resource_catalog.loc[resource_catalog['title'] == str_input]
# Predict category of input string category
prediction_inp = temp_df.iloc[0][8]
prediction_inp = int(prediction_inp)
# Based on the above prediction recommended 10 random courses
temp_df = resource_catalog.loc[resource_catalog['ClusterPrediction'] ==
prediction_inp]
temp_df = temp_df.drop_duplicates(subset ="course_name",keep = "first", inplace =
False)
rec_courses = temp_df['course_name']
return rec_courses[1:11]
# Call function and enter title
str_input = input(">>>")
res = recommend_util(str_input)
length = len("Suggested courses for: ") + len(str_input)
print("Suggested courses for: ", str_input)
i = 0
while i < length:
print('-', end="")
i = i + 1
print("\n")
print(res)
In order to compare the performance of the two recommenders, a supervised Naïve-Bayes classification was performed. The purpose of this was to see whether the field of education could be predicted and then compare the results of the two recommenders to this. The dataset was split into 80% for training and 20% for testing and run through the scikit.learn naïve_bayes.MultinomialNB() function. The results will be discussed in sections 6.3 and 7.3.
The cosine similarity recommender system appears to have recommended courses reasonably well. The following outputs show lists of courses recommended based on two different inputs: ‘feminist cultural studies’ and ‘computer security and cryptography’.
Title: feminist cultural studies
--------------------------------
The results of the cosine similarity recommender show that recommended courses are
focused around topics like culture, identity, law and communication. On the basis of this
alone, the recommender has made a fair recommendation, but these results will be
elaborated further in section 7 – Discussion.
Suggested courses for feminist cultural studies
-----------------------------------------------
2516 communications and cultures in the global era
599 ideas and identity
351 advanced criminal law
2361 doing cultural studies
284 communication research
2811 the public sphere
9477 food and drink in contemporary society
15634 youth cultures
21424 contemporary media theory
7421 people corporates and globalisation
3316 introduction to sustainable development (oua)
3736 states social forces and development
Title: computer security and cryptography
-----------------------------------------
Likewise, the recommender has made a fair recommendation for ‘computer security and
cryptography’, with course topics concerning computers, IT and the web:
Suggested courses for computer security and cryptography
--------------------------------------------------------
4433 computer security
23258 it professional practice
24140 web and mobile computing
4879 web analytics
6.2 k-means clustering recommender system
The k-means output for the same two title inputs are shown below, with varying results.
The k-means output for the same two title inputs are shown below, with varying results.
Title: feminist cultural studies
The k-means technique has focused on the ‘cultural’ keyword and the focus of the
recommended courses is reasonable but slightly different, tending towards culture and
ethnography, particularly Indigenous Australian culture (in the case of the first two results).
Some results appear that also appeared in the cosine similarity recommender (notably,
communication research and advanced criminal law).
Suggested courses for: feminist cultural studies
-------------------------------------------------
58 aboriginal social realities
125 writing place landscapes memory history
226 overseas aid and international development (o...
269 issues and practices
284 communication research
292 primary curriculum iv (humanities and social ...
302 managing strategic risk and projects
351 advanced criminal law
394 legal writing for lawyers
560 travel and tourism in society
Title: Computer security and cryptography
-----------------------------------------
The k-means recommender has performed well for this title, and has produced similar titles
to the cosine similarity recommender, again with a focus on computers, the web, and IT.
Suggested courses for: computer security and cryptography
----------------------------------------------------------
3057 foundations of computer systems
4433 computer security
4879 web analytics
8860 bioethics and law for health care leadership
9604 video games industry and culture
11465 small medium and large
12605 smart liveable cities
13910 it professional practice
14229 leading organisational decision making
14979 facilitating lifelong learning
The supervised Naïve-Bayes classifier was able to predict field of education 69.5% of the time. The supervised Naïve-Bayes classification was performed as follows:
Naive = naive_bayes.MultinomialNB()
Naive.fit(Train_X_Tfidf,Train_Y)
# predict the labels on validation dataset
predictions_NB = Naive.predict(Test_X_Tfidf)
# Use accuracy_score function to get the accuracy
print("Naive Bayes Accuracy Score: ",accuracy_score(predictions_NB, Test_Y)*100)
[ ] Output:
Naive Bayes Accuracy Score: 69.57656030503713
The results of the cosine similarity recommender can be evaluated in terms of the ability of the recommender to identify similar titles, in terms of field of education. Table 5 shows that the course recommendations for ‘feminist cultural studies’ belong primarily to the ‘society’ field of education.
Table 5: Cosine similarity course recommendations for 'feminist cultural studies'.
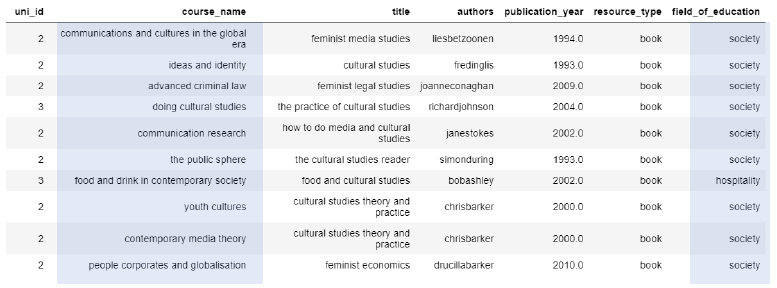
Likewise, Table 6 shows course recommendations for ‘computer security and cryptography’ return results belonging to the IT field of education. Given that the supervised Naïve-Bayes classifier was able to predict field of education 69.5% of the time, this is a reasonable result. The results of the cosine similarity recommender show that, based on the similarity of title text, the recommender can predict courses within a similar field of education.
Table 6: Cosine similarity course recommendations for 'computer security and cryptography'.
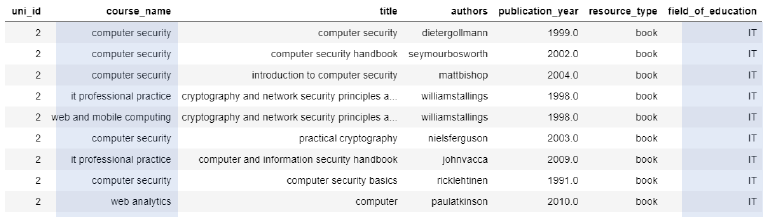
In terms of field of education, the k-means clustering recommender did not perform as well as the cosine similarity recommender, as shown in Table 7. The cluster prediction for ‘feminist cultural studies’ grouped courses in the society and arts categories, and courses relate more strongly to the ‘cultural’ aspect of the title, including Indigenous Australian culture and including results that relate to culture as ethnicity or nationality, rather than the context of ‘feminist culture’.
Table 7: k-means course recommendations for 'feminist cultural studies'.
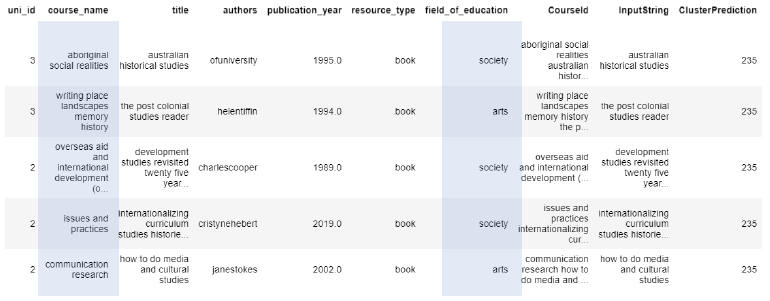
The recommender performed better for ‘computer security and cryptography’. All of the top results relate to the field of information technology (IT), except for the top recommended course. The course name has been allocated to the ‘environment’ field of education , and this is due to the presence of the term in the course name.
Table 8: k-means course recommendations for 'computer security and cryptography'.
The results of the k-means recommender show that this clustering technique may have difficulty distinguishing titles, and this issue may stem from firstly the categorisation of field of education data and secondly the selection of k = 350.
Overall, due to the large size of the dataset, the breadth of the fields of education and the difficulty in ascertaining the number of centroids for the k-means analysis, this recommender, while producing reasonable results, requires more tuning and potentially more language data to provide a more reliable recommendation.
This report has demonstrated two different approaches to recommending existing course material to similar subjects. Of the two recommenders analysed in this report, the cosine similarity recommender produces the better results, since it works by scoring the similarity of each resource title to every other resource title, and recommends a course based on the match. The process is more sound than that of the k-means recommender. For several reasons, including the problematic selection of a k parameter, the k-means cluster recommender is not endorsed as a solution to this topic.
There are, of course, improvements to be made to the cosine similarity recommender. A more standardised approach to ascertaining field of education data would benefit the analysis, as well as improving the number of fields, in order to making each field of education less general. For example, ‘health’ could be further broken down into categories such as ‘pharmacy’, ‘medicine’ and ‘nursing’. Both recommenders could be improved with more metadata, which may have been a viable option if a different API was used.
Australian Government. (2021). HEIMSHELP Field of education types. Retrieved from https://heims help.dese.gov.au/resources/field-of-education-types
Chowdhury, G. (2003). Natural language processing. Annual review of information science and technology, 37(1), 51-89.
Goel, V. (2018) Applying machine learning to classify an unsupervised text document. Retrieved from https://towardsdatascience.com/applying-machine-learning-to-classify-anunsupervised- text-document-e7bb6265f52
Hirschberg, J., & Manning, C. (2015). Advances in natural language processing. Science, 349(6245), 261-266.
Indurkhya, N., & Damerau, F. (2010). Handbook of natural language processing. CRC Press. Nadkarni, P., Ohno-Machado, L., & Chapman, W. (2011). Natural language processing: an introduction. Journal of the American Medical Informatics Association, 18(5), 544-551.
Sharma, A. (2020) Beginner Tutorial: Recommender Systems in Python. Retrieved from https://www.datacamp.com/community/tutorials/recommender-systems-python
Wolff, R. (2020) Semantic analysis: what is it and how does it work? Retrieved from https://monkeylearn.com/blog/semantic-analysis/