This repository is dedicated to a comprehensive exploration of the Transformer architecture, focusing on detailed insights into each component, its requirements, and various applications.
-
Set up the environment by running the following command:
sh scripts/setup_env.sh
-
To add new dependency package to the repo
uv add <package-name>
- Note:
The
apache-beamlibrary is utilized as a large-scale data processing tool in this repository. However, due to dependency conflicts with other packages, it has been intentionally excluded from therequirements-dev.txtfile. It is strongly recommended to install this package separately.
project
│ README.md
│ requirements.txt
│___scripts (contains setup and other script files)
│___core
| |____tokenizer (holds all tokenizer training files and artifacts)
| |____activation (holds all activation implementation and test cases)
| |____configuratioin (hold all model configuration)
| |____layers (hold all custom transformers and other model layers)
| |____utils (hold all helper utils)
| |____training (holds all training related modules)
│___study (contains other experimentation studies and other resources)
|
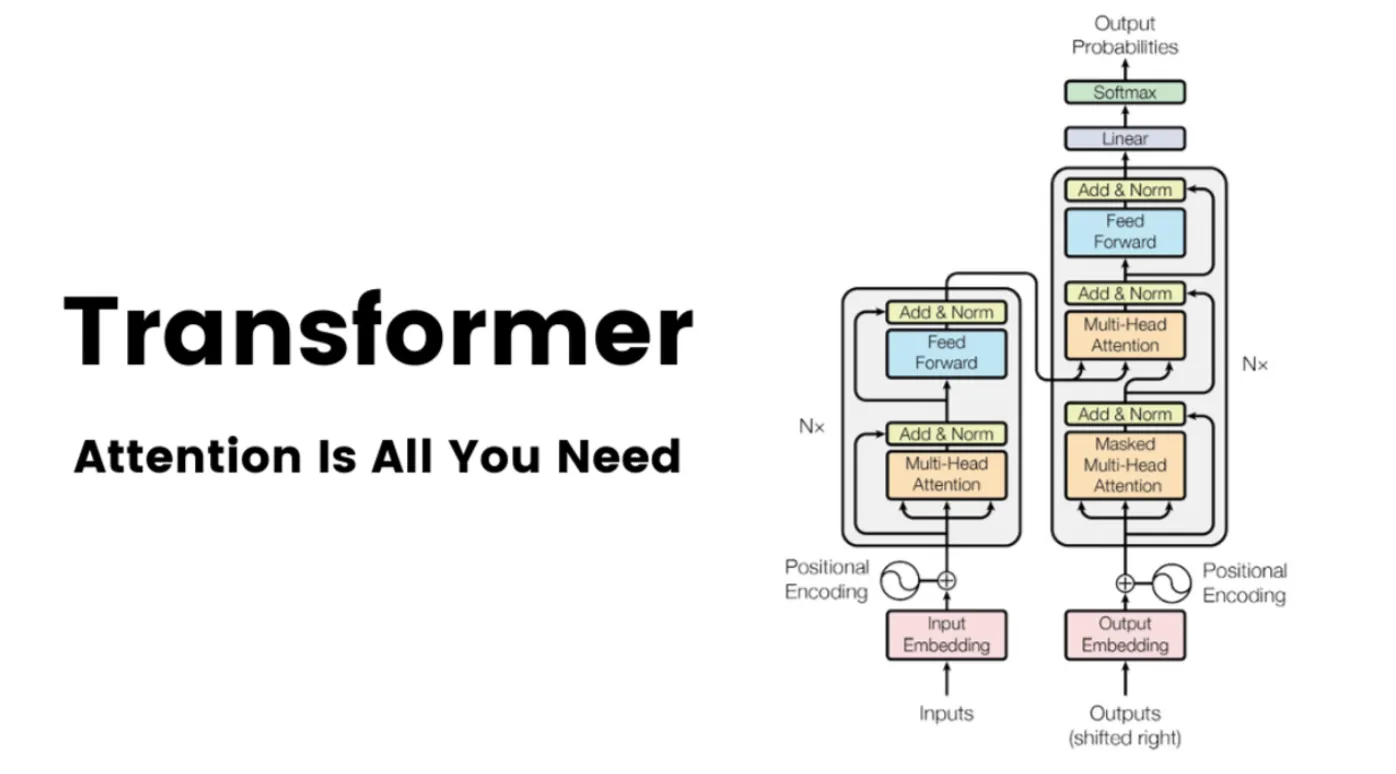
This repository provides an in-depth implementation of the Transformer model's decoder architecture, with components focused on tokenization, training, and customization. The repository serves as a hands-on resource for experimenting with state-of-the-art models, making it suitable for those interested in advanced AI applications.
The following Jupyter notebooks explore various aspects of tokenization:
This repository includes resources for training and customizing Byte Pair Encoding (BPE) tokenizers, essential for handling text input efficiently in Transformer models.
AI-Uncomplicated/study/Tokenizer.ipynb: Overview and insights on tokenization techniques.AI-Uncomplicated/study/tokenizer_training_toy.ipynb: Hands-on guide for training a tokenizer with toy datasets.
For advanced users interested in training and modifying BPE tokenizers:
- Training a BPE Tokenizer: Use
AI-Uncomplicated/tokenizer/bpe/trainer.pyto train a tokenizer from scratch. - Post-Processing (Token Addition & Removal): The
AI-Uncomplicated/tokenizer/bpe/notebooks/post_process_trained_tokenizer.ipynbnotebook provides tools for adding or removing specific tokens from an existing tokenizer.
In Transformer models, position encoding is crucial for providing a sense of word order in sequences since these models lack inherent positional awareness. This section explores both absolute and relative position encoding techniques.
- What is Positional Encoding?
To grasp the fundamentals of positional encoding and sinusoidal encoding, explore the notebook:
AI-Uncomplicated/study/sinisouidal_encoding.ipynb. This provides a detailed explanation of how positional information is encoded mathematically in Transformers. - Relative Positional Encoding
Relative positional encoding introduces flexibility by enabling Transformers to consider relationships between tokens rather than absolute positions. Several new approaches have been proposed to implement this effectively.
Use the notebook
AI-Uncomplicated/study/rope_positional_encoding.ipynbto delve into the Rotary Positional Embedding (ROPE) method, understand its motivation, and see how it works in practice.
References Attention is All You Need
Neural Machine Translation with a Transformer and Keras
Lingua Repo Meta [Training scripts and modified data loader have been used from this repo]