Format-agnostic parser for Illumina SampleSheet.csv files.
Supports both the classic IEM V1 format (bcl2fastq era) and the modern BCLConvert V2 format (NovaSeq X series) — plus non-Illumina Element AVITI run manifests — with automatic format detection, bidirectional conversion, index validation, Hamming distance checking, per-cycle color-balance validation against the instrument's optical chemistry, diff comparison, multi-sheet merging, programmatic sheet creation, and a full-featured CLI.

![]()
Docs: https://illumina-samplesheet.readthedocs.io/ | PyPI: https://pypi.org/project/samplesheet-parser/
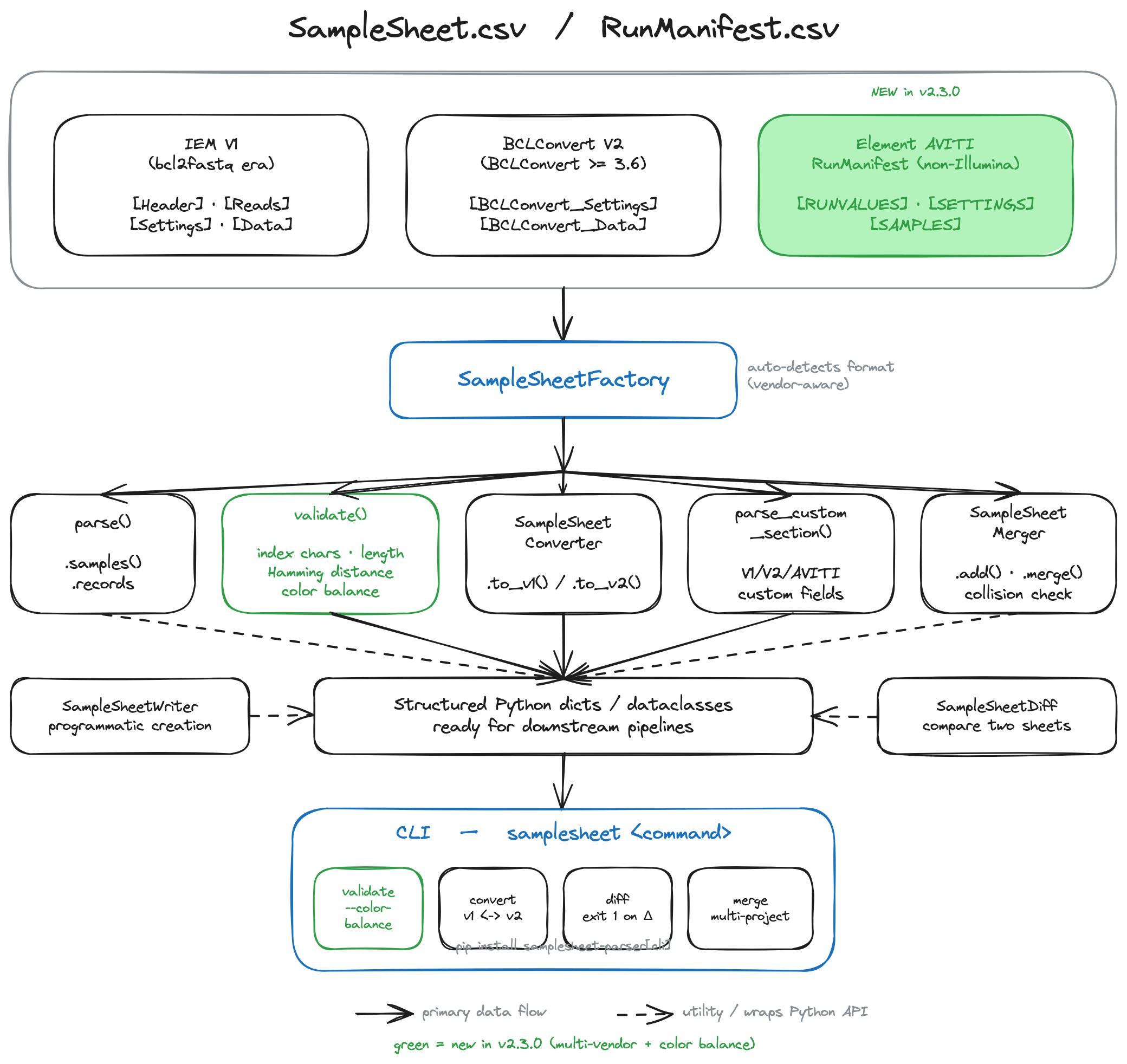
SampleSheetFactory auto-detects the format — Illumina V1/V2 or an Element AVITI run manifest — and routes to the correct parser. All formats share a common interface — SampleSheetConverter handles bidirectional conversion between the Illumina formats, SampleSheetValidator catches index, adapter, and color-balance issues, SampleSheetDiff compares two sheets across any combination of formats, SampleSheetMerger combines multiple per-project sheets into one, and SampleSheetWriter builds or edits sheets programmatically. The samplesheet CLI exposes all of this from the shell.
Labs running mixed instrument fleets — older NovaSeq 6000 alongside newer NovaSeq X series, and increasingly non-Illumina platforms like the Element AVITI — produce several incompatible sample-sheet formats. BCLConvert V2 sheets use [BCLConvert_Settings] / [BCLConvert_Data] sections, OverrideCycles for UMI encoding, and FileFormatVersion in the header. IEM V1 sheets use IEMFileVersion and a flat [Data] section. Element AVITI ships a RunManifest.csv with an entirely different layout.
Existing tools either hard-code one vendor's format or require the caller to know which format they have. samplesheet-parser auto-detects the format across vendors, exposes a consistent interface for all of them, converts between the Illumina formats, validates index integrity (including Hamming distance and per-cycle color balance against each instrument's optical chemistry), diffs sheets to catch accidental changes before a run starts, and writes new sheets programmatically — so you never have to hand-edit a CSV again.
# Core library only
pip install samplesheet-parser
# With the CLI (adds typer)
pip install "samplesheet-parser[cli]"Requires Python 3.10+. No mandatory runtime dependencies.
from samplesheet_parser import SampleSheetFactory
factory = SampleSheetFactory()
sheet = factory.create_parser("SampleSheet.csv", parse=True)
print(factory.version) # SampleSheetVersion.V1, .V2, or .ELEMENT_AVITI
print(sheet.index_type()) # "dual", "single", or "none"
for sample in sheet.samples():
print(sample["sample_id"], sample["index"])from samplesheet_parser import SampleSheetV1
sheet = SampleSheetV1("SampleSheet.csv")
sheet.parse()
print(sheet.experiment_name) # "MyRun_20240115"
print(sheet.read_lengths) # [151, 151]
print(sheet.adapters) # ["CTGTCTCTTATACACATCT"]
print(sheet.index_type()) # "dual"
for sample in sheet.samples():
print(sample["sample_id"], sample["index"], sample["index2"])from samplesheet_parser import SampleSheetV2
sheet = SampleSheetV2("SampleSheet.csv")
sheet.parse()
# OverrideCycles: Y151;I10U9;I10;Y151 → 9 bp UMI in Index1
print(sheet.get_umi_length()) # 9
rs = sheet.get_read_structure()
print(rs.umi_location) # "index2"
print(rs.read_structure) # {"read1_template": 151, "index2_length": 10, "index2_umi": 9, ...}from samplesheet_parser import SampleSheetConverter
# V1 → V2
SampleSheetConverter("SampleSheet_v1.csv").to_v2("SampleSheet_v2.csv")
# V2 → V1 (lossy — V2-only fields are dropped with a warning)
SampleSheetConverter("SampleSheet_v2.csv").to_v1("SampleSheet_v1.csv")from samplesheet_parser import SampleSheetFactory, SampleSheetValidator
sheet = SampleSheetFactory().create_parser("SampleSheet.csv", parse=True)
result = SampleSheetValidator().validate(sheet)
print(result.summary())
# PASS — 0 error(s), 2 warning(s)
for w in result.warnings:
print(w)
# [WARNING] INDEX_DISTANCE_TOO_LOW: Indexes for 'S1' and 'S2' in lane '1'
# have a Hamming distance of 1 (minimum recommended: 3).
# This may cause demultiplexing bleed-through.
for err in result.errors:
print(err)
# [ERROR] DUPLICATE_INDEX: Index 'ATTACTCG+TATAGCCT' appears more than once in lane 1from samplesheet_parser import SampleSheetDiff
diff = SampleSheetDiff("old/SampleSheet.csv", "new/SampleSheet.csv")
result = diff.compare()
print(result.summary())
# Diff (V1 → V2):
# 2 header/settings change(s)
# 1 sample(s) added: SAMPLE_009
# 1 sample(s) with field changes
if result.has_changes:
for change in result.sample_changes:
print(change)
# Sample 'SAMPLE_002' (lane 1):
# Index: 'TCCGGAGA' → 'GGGGGGGG'
for s in result.samples_added:
print(f"Added: {s['Sample_ID']}")Works across any combination of V1 and V2 — field names are normalised before
comparison so V1-only columns (I7_Index_ID, Sample_Name, etc.) do not
generate spurious diffs.
from samplesheet_parser import SampleSheetWriter
from samplesheet_parser.enums import SampleSheetVersion
# Build a V2 sheet from scratch
writer = SampleSheetWriter(version=SampleSheetVersion.V2)
writer.set_header(run_name="MyRun_20240115", platform="NovaSeqXSeries")
writer.set_reads(read1=151, read2=151, index1=10, index2=10)
writer.set_adapter("CTGTCTCTTATACACATCT")
writer.set_override_cycles("Y151;I10;I10;Y151")
writer.add_sample("SAMPLE_001", index="ATTACTCGAT", index2="TATAGCCTGT", project="Proj")
writer.add_sample("SAMPLE_002", index="TCCGGAGACC", index2="ATAGAGGCAC", project="Proj")
writer.write("SampleSheet.csv") # validates before writing by default
# Load an existing sheet, edit it, write back
from samplesheet_parser import SampleSheetFactory
sheet = SampleSheetFactory().create_parser("SampleSheet.csv", parse=True)
editor = SampleSheetWriter.from_sheet(sheet)
editor.remove_sample("SAMPLE_005")
editor.update_sample("SAMPLE_002", index="GGGGGGGGGG")
editor.write("SampleSheet_updated.csv")write() runs SampleSheetValidator before writing by default — pass
validate=False to skip. from_sheet(sheet, version=SampleSheetVersion.V1)
converts format while editing.
Combine per-project sheets from a single run into one merged sheet. Conflicts (index collisions, read-length mismatches, adapter disagreements) are surfaced as structured results rather than silent failures.
from samplesheet_parser import SampleSheetMerger
from samplesheet_parser.enums import SampleSheetVersion
result = (
SampleSheetMerger(target_version=SampleSheetVersion.V2)
.add("ProjectA.csv")
.add("ProjectB.csv")
.add("ProjectC.csv")
.merge("SampleSheet_combined.csv")
)
print(result.summary())
# Merged 3 sheet(s) → SampleSheet_combined.csv (12 samples) — 0 conflict(s), 0 warning(s)
if result.has_conflicts:
for c in result.conflicts:
print(c)
# [CONFLICT] INDEX_COLLISION: Index 'ATTACTCG+TATAGCCT' in lane 1
# appears in both ProjectA.csv and ProjectB.csv
for w in result.warnings:
print(w)
# [WARNING] MIXED_FORMAT: Input sheets are a mix of V1 and V2 formats.
# All will be converted to V2 for output.Mixed V1/V2 inputs are automatically converted to the target format.
Pass abort_on_conflicts=False to write output even when conflicts exist.
Install the CLI extra and use the samplesheet command directly from the shell:
pip install "samplesheet-parser[cli]"# Text output — exit 0 if clean, exit 1 if errors
samplesheet validate SampleSheet.csv
# JSON output for CI pipelines
samplesheet validate SampleSheet.csv --format jsonsamplesheet convert SampleSheet_v1.csv --to v2 --output SampleSheet_v2.csv
samplesheet convert SampleSheet_v2.csv --to v1 --output SampleSheet_v1.csv# Exit 0 if identical, exit 1 if any differences detected
samplesheet diff old/SampleSheet.csv new/SampleSheet.csv
# JSON output for scripting
samplesheet diff old/SampleSheet.csv new/SampleSheet.csv --format json# Clean merge — exit 0
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv
# Merge three sheets to V1 format
samplesheet merge ProjectA.csv ProjectB.csv ProjectC.csv --to v1 --output combined.csv
# Write output even if conflicts are found
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv --force
# JSON output
samplesheet merge ProjectA.csv ProjectB.csv --output combined.csv --format jsonExit codes (all commands):
| Code | Meaning |
|---|---|
0 |
Success / no issues |
1 |
Errors found (invalid sheet, conflicts, differences detected) |
2 |
Usage error (missing file, bad argument) |
The factory uses a three-step detection strategy — no format hints required from the caller:
- Header discriminator — scan
[Header]forFileFormatVersion(→ V2) orIEMFileVersion(→ V1) - Section name scan — if no header key found, look for
[BCLConvert_Settings]/[BCLConvert_Data]in the full file (→ V2) - Default — fall back to V1 (broadest compatibility with legacy files)
The detector reads only as much of the file as needed — stopping after [Header] in the common case.
| Code | Level | Description |
|---|---|---|
EMPTY_SAMPLES |
error | No samples in Data section |
INVALID_INDEX_CHARS |
error | Index contains non-ACGTN characters |
INDEX_TOO_LONG |
error | Index longer than 24 bp |
DUPLICATE_INDEX |
error | Two samples share an index in the same lane |
DUPLICATE_SAMPLE_ID |
error | Same Sample_ID appears twice in one lane |
INDEX_TOO_SHORT |
warning | Index shorter than 6 bp |
INDEX_DISTANCE_TOO_LOW |
warning | Two indexes in the same lane have Hamming distance < 3, risking demultiplexing bleed-through |
NO_ADAPTERS |
warning | No adapter sequences configured |
ADAPTER_MISMATCH |
warning | Adapter is non-standard |
COLOR_BALANCE_NO_SIGNAL |
error | An index cycle has no signal in an optical channel (2-/1-channel chemistry) — the index read will fail. Opt-in. |
COLOR_BALANCE_LOW |
warning | An index cycle has weak signal in a channel, or no base diversity (4-channel) — degraded base calls. Opt-in. |
Indexes that are too similar cause read bleed-through between samples during demultiplexing, a common cause of low-quality runs that a simple duplicate check does not catch. For every pair of samples within a lane the validator computes a combined distance and warns when it falls below the recommended minimum of 3.
For dual-index sheets the combined distance is the sum of the per-index mismatch counts: the I7 distance plus the I5 distance. This equals the minimum number of sequencing errors needed to read one sample's barcodes as another's across both index reads, and summing per index (rather than concatenating the two indexes into one string) keeps the I7 and I5 positions aligned even when samples use different index lengths. So a pair that is close on I7 but well-separated on I5, as most dual-index kits are designed, is not flagged.
Each per-index distance treats an N cycle as a wildcard that matches any
base, so two indexes that differ only at an N are reported as colliding.
# Custom threshold: stricter than the default of 3
from samplesheet_parser.validators import SampleSheetValidator, ValidationResult
samples = sheet.samples()
result = ValidationResult()
SampleSheetValidator()._check_index_distances(samples, result, min_distance=4)On 2-channel instruments (NextSeq, NovaSeq, NovaSeq X) and 1-channel
instruments (iSeq), bases are called from optical signal: A lights
both channels, C only red, T only green, and G is a dark base with no
signal at all. A cycle where the whole index pool reads G produces no
signal, so the instrument cannot register the tile and the index read fails —
a real, common cause of wrecked runs that a Hamming-distance check cannot see.
Because the sample sheet already contains every sample's index, this can be predicted before the run starts with no sequencing data. The validator scores the pool cycle-by-cycle: it transposes the indexes into columns and checks that each column produces signal in both channels.
from samplesheet_parser import SampleSheetFactory, SampleSheetValidator
sheet = SampleSheetFactory().create_parser("SampleSheet.csv", parse=True)
# Opt in; the instrument is read from the sheet header (or pass instrument=...)
result = SampleSheetValidator().validate(sheet, check_color_balance=True)
for err in result.errors:
print(err)
# [ERROR] COLOR_BALANCE_NO_SIGNAL: On 2-channel chemistry (NovaSeqXSeries),
# index1 cycle 4 has no red or green signal across the pool: no sample
# carries a red or green base (A/C/T) at this cycle ... the index read will fail.The chemistry is resolved from the instrument name; the check is off by default (it can legitimately fail a low-plex pool) and is skipped silently for unknown instruments. The same analysis is available standalone:
from samplesheet_parser import analyze_color_balance, chemistry_for_instrument
chem = chemistry_for_instrument("NovaSeqXSeries") # Chemistry.TWO_CHANNEL
report = analyze_color_balance(["ATGGCTAC", "CAGGTACG", "TCGGACGT", "GATGGCTA"],
chemistry=chem)
for cb in report.dark_cycles:
print(cb.read, cb.cycle, cb.base_counts) # index1 4 {'G': 4}From the CLI:
samplesheet validate SampleSheet.csv --color-balance
samplesheet validate SampleSheet.csv --color-balance --instrument NovaSeqXSeries| Chemistry | Instruments | What is flagged |
|---|---|---|
| 4-channel | MiSeq, HiSeq 2000/2500/3000/4000, Element AVITI | Zero-diversity cycles (warning) |
| 2-channel | NextSeq, NovaSeq 6000, NovaSeq X, MiniSeq | Dark cycles / weak channels |
| 1-channel | iSeq 100 | Dark cycles / weak channels |
Element AVITI uses four-channel avidity chemistry (four images per cycle, one per avidite dye — Arslan et al., Nat. Biotechnol. 2023), so it has no dark base; color-balance checking flags low-diversity index cycles rather than dark cycles.
The factory is not limited to Illumina. Any parser that implements the
SampleSheetParser protocol can be auto-detected, and Element Biosciences
AVITI RunManifest.csv files are supported out of the box — the same
SampleSheetFactory recognises them and returns a parser with the identical
interface:
from samplesheet_parser import SampleSheetFactory
factory = SampleSheetFactory()
sheet = factory.create_parser("RunManifest.csv", parse=True)
print(factory.version) # SampleSheetVersion.ELEMENT_AVITI
print(sheet.index_type()) # "dual"
for s in sheet.samples(): # same schema as Illumina: sample_id, index, index2, ...
print(s["sample_id"], s["index"], s["index2"])AVITI is a four-channel avidity platform, so color-balance validation applies
to it too (flagging low-diversity index cycles). Manifest columns
(SampleName, Index1, Index2, Lane, Project, ExternalID) are mapped
to the shared sample schema, so the validator, diff, and filter tooling work
across vendors without special-casing.
| Code | Level | Description |
|---|---|---|
PARSE_ERROR |
conflict | An input sheet could not be parsed |
INDEX_COLLISION |
conflict | The same index appears in the same lane across two sheets |
READ_LENGTH_CONFLICT |
conflict | Sheets specify different read lengths or cycle counts |
MERGE_VALIDATION_ERROR |
conflict | Post-merge validation of the combined sheet failed |
MIXED_FORMAT |
warning | Input sheets are a mix of V1 and V2 formats |
INDEX_DISTANCE_TOO_LOW |
warning | Cross-sheet index pair has Hamming distance below threshold |
ADAPTER_CONFLICT |
warning | Adapter sequences differ between sheets (primary sheet adapters are used) |
INCOMPLETE_SAMPLE_RECORD |
warning | A sample row is missing Sample_ID or index and was skipped |
SampleSheetDiff compares two sheets — any combination of V1 and V2 — and
returns a structured DiffResult across four dimensions:
| Dimension | What is compared |
|---|---|
| Header | Key/value changes in [Header] / [BCLConvert_Settings] |
| Reads | Read length or cycle count changes |
| Samples added / removed | Keyed on Sample_ID + Lane |
| Sample field changes | Per-sample field-level diffs (index, project, etc.) |
result = SampleSheetDiff("before.csv", "after.csv").compare()
result.has_changes # bool
result.summary() # one-paragraph human-readable summary
result.header_changes # list[HeaderChange]
result.samples_added # list[dict]
result.samples_removed # list[dict]
result.sample_changes # list[SampleChange]
# Inspect per-sample changes
for sc in result.sample_changes:
print(sc.sample_id, sc.lane)
for field, (old, new) in sc.changes.items():
print(f" {field}: {old!r} → {new!r}")V1-only metadata columns (I7_Index_ID, I5_Index_ID, Sample_Name,
Description) are suppressed when comparing V1 against V2 so that format
differences do not generate noise.
The V2 OverrideCycles field encodes read structure including UMI positions:
| OverrideCycles | UMI length | UMI location |
|---|---|---|
Y151;I10;I10;Y151 |
0 | — |
Y151;I10U9;I10;Y151 |
9 | index2 |
U5Y146;I8;I8;U5Y146 |
5 | read1 |
sheet.get_umi_length() # → int
sheet.get_read_structure() # → ReadStructure dataclass| Method / attribute | Returns | Description |
|---|---|---|
create_parser(path, *, clean, experiment_id, parse) |
SampleSheetParser |
Auto-detect format and return appropriate parser |
register(detector, parser_class, version) |
None |
Register a custom format detector (class method, LIFO) |
clear_registry() |
None |
Remove all custom registrations (class method) |
get_umi_length() |
int |
UMI length from the current parser |
.version |
SampleSheetVersion |
Detected format version |
A runtime_checkable structural protocol satisfied by both SampleSheetV1 and SampleSheetV2. Third-party parsers that implement the same methods and attributes can be registered with SampleSheetFactory.register() without inheriting from any base class.
from samplesheet_parser import SampleSheetParser, SampleSheetV1
assert isinstance(SampleSheetV1("sheet.csv"), SampleSheetParser)| Method / attribute | Returns | Description |
|---|---|---|
parse(do_clean=True) |
None |
Parse all sections |
samples() |
list[dict] |
One record per unique sample |
index_type() |
str |
"dual", "single", or "none" |
.adapters |
list[str] |
Adapter sequences |
.experiment_name |
str | None |
Run/experiment name |
| Method | Returns |
|---|---|
get_umi_length() |
int |
get_read_structure() |
ReadStructure |
| Method | Returns | Notes |
|---|---|---|
to_v2(output_path) |
Path |
Converts IEM V1 → BCLConvert V2 |
to_v1(output_path) |
Path |
Converts BCLConvert V2 → IEM V1 (lossy) |
.source_version |
SampleSheetVersion |
Auto-detected format of input |
| Method | Returns | Description |
|---|---|---|
validate(sheet) |
ValidationResult |
Run all checks; returns structured result |
_check_index_distances(samples, result, min_distance=3) |
None |
Hamming distance check (callable directly for custom thresholds) |
from samplesheet_parser import hamming_distance
hamming_distance("ATTACTCG", "ATTACTCA") # → 1
hamming_distance("ATTACTCG", "GCTAGCTA") # → 6Public helper for computing the Hamming distance between two index sequences. Sequences of unequal length are compared up to the shorter length.
| Method / attribute | Returns | Description |
|---|---|---|
SampleSheetWriter(version=) |
— | Instantiate for SampleSheetVersion.V1 or .V2 |
from_sheet(sheet, version=) |
SampleSheetWriter |
Load a parsed sheet for editing; optionally change output format |
set_header(*, run_name, platform, ...) |
self |
Set header fields (fluent) |
set_reads(*, read1, read2, index1, index2) |
self |
Set read cycle counts (fluent) |
set_adapter(adapter_read1, adapter_read2) |
self |
Set adapter sequences (fluent) |
set_override_cycles(override) |
self |
Set OverrideCycles string — V2 only (fluent) |
set_software_version(version) |
self |
Set SoftwareVersion — V2 only (fluent) |
set_setting(key, value) |
self |
Set an arbitrary settings key/value (fluent) |
add_sample(sample_id, *, index, ...) |
self |
Append a sample row (fluent) |
remove_sample(sample_id, *, lane=) |
self |
Remove sample(s) by ID, optionally scoped to a lane (fluent) |
update_sample(sample_id, *, lane=, **fields) |
self |
Update fields on an existing sample in-place (fluent) |
write(path, *, validate=True) |
Path |
Serialise to disk; validates first by default |
to_string() |
str |
Serialise to string without writing to disk |
.sample_count |
int |
Number of samples currently in the writer |
.sample_ids |
list[str] |
Sample IDs currently in the writer |
| Method | Returns | Description |
|---|---|---|
compare() |
DiffResult |
Full comparison across header, reads, settings, and samples |
| Attribute / method | Type | Description |
|---|---|---|
has_changes |
bool |
True if any difference was detected |
summary() |
str |
Human-readable one-paragraph summary |
header_changes |
list[HeaderChange] |
Header, reads, and settings diffs |
samples_added |
list[dict] |
Records present in new sheet only |
samples_removed |
list[dict] |
Records present in old sheet only |
sample_changes |
list[SampleChange] |
Per-sample field-level diffs |
source_version |
SampleSheetVersion |
Format of the old sheet |
target_version |
SampleSheetVersion |
Format of the new sheet |
| Method / attribute | Returns | Description |
|---|---|---|
SampleSheetMerger(target_version=) |
— | Instantiate; default target is SampleSheetVersion.V2 |
add(path) |
self |
Register an input sheet path (fluent) |
merge(output_path, *, validate=True, abort_on_conflicts=True) |
MergeResult |
Run the merge and write output |
| Attribute / method | Type | Description |
|---|---|---|
has_conflicts |
bool |
True if any conflict was recorded |
sample_count |
int |
Number of samples in the merged output |
output_path |
Path | None |
Path written; None if write was aborted |
source_versions |
dict[str, str] |
Per-input-file detected format version |
conflicts |
list[MergeConflict] |
Structured conflict records |
warnings |
list[MergeConflict] |
Structured warning records |
summary() |
str |
Human-readable one-line summary |
The CLI exits with meaningful codes (0 = clean, 1 = issues, 2 = error), making it easy to wire into automated pipelines.
Add a validation step to any workflow that touches SampleSheet.csv:
# .github/workflows/validate-samplesheet.yml
name: Validate SampleSheet
on:
push:
paths:
- '**/SampleSheet.csv'
pull_request:
paths:
- '**/SampleSheet.csv'
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: '3.10'
- run: pip install "samplesheet-parser[cli]"
- name: Validate SampleSheet
run: samplesheet validate SampleSheet.csv --format jsonGate commits that touch any SampleSheet.csv in the repository:
# .pre-commit-config.yaml
repos:
- repo: local
hooks:
- id: samplesheet-validate
name: Validate SampleSheet.csv
entry: samplesheet validate
language: python
additional_dependencies: ["samplesheet-parser[cli]"]
files: SampleSheet\.csv$
pass_filenames: trueInstall and run once to verify:
pip install pre-commit
pre-commit install
pre-commit run samplesheet-validate --all-filesIf your lab uses longer indexes (10 bp+), raise the minimum Hamming distance threshold to catch borderline cases earlier:
samplesheet validate SampleSheet.csv --min-hamming 4This is especially useful in CI where you want to prevent runs that will likely fail demultiplexing.
git clone https://github.com/chaitanyakasaraneni/samplesheet-parser
cd samplesheet-parser
pip install -e ".[dev,cli]"
# Run tests
pytest tests/ -v
# Run demo scripts
python scripts/demo_converter.py
python scripts/demo_diff.py
python scripts/demo_writer.pySee CONTRIBUTING.md for the full local testing guide and PR checklist.
@software{kasaraneni2026samplesheetparser,
author = {Kasaraneni, Chaitanya},
title = {samplesheet-parser: Format-agnostic parser for Illumina SampleSheet.csv},
year = {2026},
url = {https://github.com/chaitanyakasaraneni/samplesheet-parser},
version = {1.1.0}
}Apache 2.0 — see LICENSE.