- Parte 1.1 - Introducción
- Parte 1.2 - MNIST
- Parte 1.3 - Tensores de MNIST
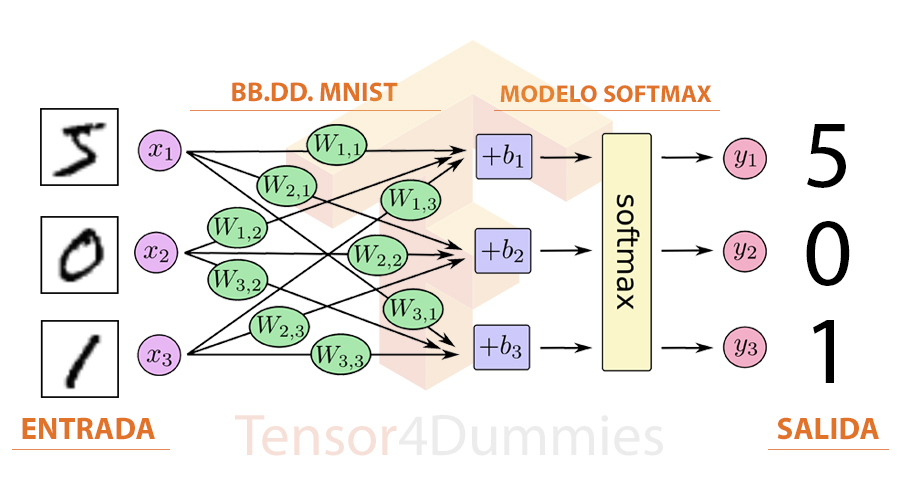
- Parte 1.4 - Funcionamiento del modelo Softmax
- Parte 1.5 - Implementación en TensorFlow
Cada imagen está compuesta de millones de puntos (píxeles). Cada píxel acumula información acerca del color, saturación y otros datos para formar la imagen visible.
Representación de un píxel:
1 1 0 1 0
0 1 0 1 1
0 0 0 0 1
Para trabajar con procesamiento de imágenes se utilizan Redes neuronales convolucionales (CNNs).
Se representa con 3 valores posibles, uno para cada color (rojo, verde o azul). El rango de dichos valores es desde 0 a 255.
- Rojo: 255, 0, 0
- Verde: 0, 255, 0
- Azul: 0, 0, 255
Se representa con 1 único valor posible que almacena la información de intensidad (luminancia o brillo). El rango de dicho valor es desde 0 a 1.
Como podemos ver en la documentación de TensorFlow, cuando alguien aprende un lenguaje de programación nuevo suele aprender a ejecutar un Hello World. En aprendizaje automático el Hello World tiene su equivalencia a MNIST.
MNIST es un conjunto de datos para el uso en visión por computador. Se compone de una serie de dígitos manuscritos como los siguientes:

Para el reconocimiento de imágenes generalmente se utiliza un modelo basado en Softmax Regression (uno de los más simples de la regresión logística multinomial). El modelo Softmax se basa en la regresión logística multinomial que se utiliza cuando la variable dependiente que queremos etiquetar es nominal.
Es decir, dicha variable puede etiquetarse en un conjunto de categorías que se excluyen entre sí y para los cuales hay más de dos categorías.
Imaginemos que tenemos números escritos en papel y queremos desarrollar una aplicación móvil para reconocer dichos números. Cada uno de nosotros tenemos una forma diferente de escribir dichos dígitos y además, nunca los escribimos de la misma forma. Por ello, poder identificar los dígitos con lenguaje de programación regular seria muy difícil y nos inclinamos por un modelo basado en redes neuronales.
Como ya hemos visto en otras partes de los vídeos, un modelo basado en redes neuronales necesita una gran cantidad de ejemplos para enseñar (train) a nuestro programa a reconocer dichos dígitos. El papel principal de MNIST en este caso es proporcionarnos una base de datos de infinidad de formas de representar un mismo dígito, por así decirlo es como si tuviéramos la forma de representar los dígitos de miles de personas diferentes almacenados en una base de datos.
Los datos de la base de datos de MNIST están alojados en un CDN, dichos datos contienen:
- 55.000 puntos de entrenamiento (mnist.train)
- 10.000 puntos de test (mnist.test)
- 5.000 puntos de validación (mnist.validation)
El motivo de tenerlos separados es porque si juntásemos los datos de entrenamiento con los de test o validación provocaría que se generalizase y la máquina no aprendería a etiquetar nuevos elementos ya que contaría con todos de por si.
En este caso práctico de MNIST vamos a emplear el código fuente del ejemplo (src/mnist.py), contiene varias líneas para la descarga de los datos:
from tensorflow.examples.tutorials.mnist import input_data
# Import data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)El modelo Softmax trabaja con varias variables determinadas por el tipo de dato contenido en ellas por ello podemos definir varias:
- X = Imagen
- Y = Etiqueta
Ejemplo:
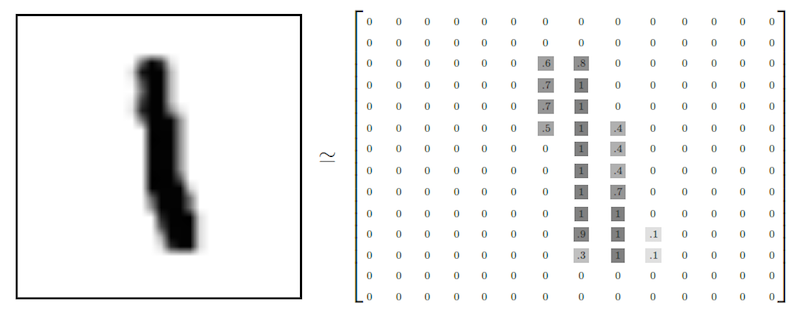
En la imagen podemos observar una matriz de tamaño 28 x 28 en la que se almacenan datos respectivos a la intensidad de color de cada píxel como hemos explicado en el apartado 1.1 de introducción. En este caso, la variable X sería la imagen y la variable Y sería "1" al ser la etiqueta respectiva a dicha imagen.
Tanto el conjunto de entrenamiento como el de testing contienen las dos variables. El resultado de estos datos se compone de un tensor de la forma [55.000, 784], la primera dimensión será un índice de imágenes (la 55.000) y la segunda dimensión será un índice de cada píxel de cada imagen.
Es decir, cada elemento de nuestro tensor es un valor de intensidad (entre 0 y 1) para cada píxel de cada imagen particular, se puede entender mejor en la siguiente imagen:

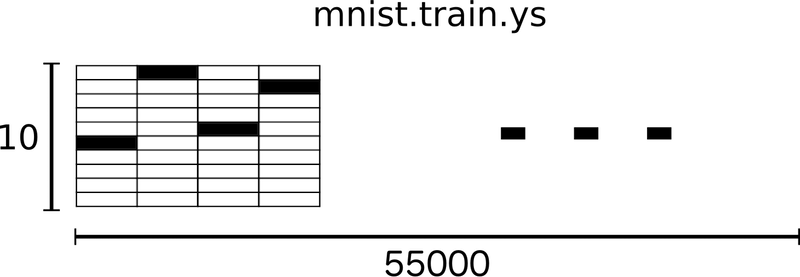
Además, cada imagen de la base de datos MNIST contiene una etiqueta Y respectiva al valor correcto etiquetado sobre dicha imagen (valor de los dígitos de 0 a 9).
En nuestro ejemplo, representamos las etiquetas como vectores posicionales one-hot. En un vector one-hot se almacenan datos en el rango de valores de 0 a 1 y que cada dígito estará representado por "1" en la posición de dicho dígito. Es decir, para representar el dígito "5" tendremos un vector de la forma:
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
Esto produce un tensor de la forma [55.000, 10], podemos entenderlo mejor en la siguiente imagen:
El modelo asigna probabilidades estadísticas de que una imagen pertenezca a un dígito, por lo que podemos encontrarnos ante la posibilidad de que el modelo asigne a una misma imagen varias probabilidades de pertenecer a cierto número. Para este problema es útil la regresión de softmax pues nos devuelve una lista de valores entre 0 y 1.
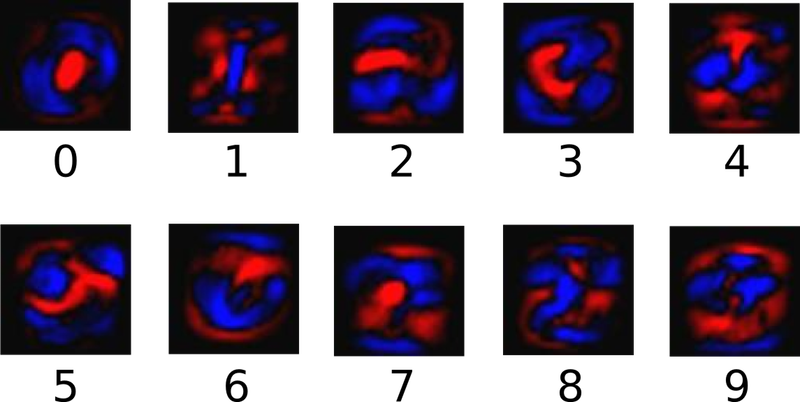
El modelo asigna primero evidencias a una imagen relativas a qué dígito corresponde, para ello realiza una suma ponderada de las intensidades de los píxeles. Dicha suma provoca que se denigren los valores que no coincidan entre la imagen y la etiqueta, es decir, el peso de la suma ponderada será negativa si un pixel no se corresponde con la etiqueta y positiva en caso de que si lo sea.
En el siguiente diagrama podemos entender mejor cómo son las sumas ponderadas para cada dígito. En azul se representa el peso positivo (se corresponde) y en rojo el peso negativo (no se corresponde).
A estas sumadas ponderadas añadimos el sesgo, dicha cantidad es un peso fijo de la red neuronal para compensar que ciertas entradas puedan ser más propensas a una clasificación que a otra (sirve como discriminante o corrección).
Mediante esta afirmación, se construye la siguiente ecuación para obtener la evidencia de que una imagen se corresponda a un tipo determinado de dígito:
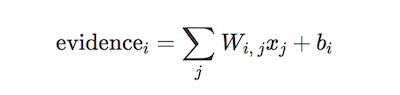
Donde:
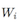 Es el peso de un determinado dígito
Es el peso de un determinado dígito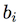 Sesgo de un determinado dígito
Sesgo de un determinado dígito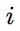 Índice que corresponde con un dígito
Índice que corresponde con un dígito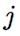 Índice de cada píxel de una imagen
Índice de cada píxel de una imagen
Ahora que tenemos la evidencia, convertimos dicho resultado en una probabilidad y de que una imagen se corresponda a un tipo de erminado (dígito) utilizando el modelo softmax de nuevo. Tras obtener las probabilidades, normalizamos el resultado para pasar de las probabilidades de y a la etiqueta de tipos, es decir, que una imagen se corresponde a un único tipo.
Ahora que tenemos la librería MNIST definida y el modelo Softmax formalizado podemos proceder a la realización del ejemplo de forma real. Para ello utilizaremos Python y librerías avanzadas de cálculo como NumPy que nos ofrecerá la potencia de cálculo necesaria para la multiplicación de las matrices del modelo.
Empezando por lo básico, necesitamos definir varias variables que utilizaremos en el cálculo:
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(x, W) + bLas variables definidas se describen de la siguiente forma:
- X = No es un valor como tal, es un placeholder (referencia) que utilizará TensorFlow en el cálculo del proceso. Necesitamos introducir cualquier número de imágenes de MNIST, por ello necesitaremos un vector de dimensión 784. Como no sabemos el tamaño de imágenes que vamos a utilizar en la entrada lo representamos como "None", o lo que es lo mismo, una dimensión de cualquier longitud.
- W = Variable utilizada para almacenar la evidencia de que una imagen [784 píxeles] se corresponda a uno de los 10 tipos [10] de dígito, por ello la dimensión de dicha variable es [784, 10].
- b = Variable utilizada para almacenar los sesgos de los diferentes tipos (dígitos).
- y = Modelo softmax que multiplica los diferentes pesos por los valores de los píxeles de cada imagen y les suma el sesgo de cada tipo (como hemos definido más arriba).
Como vemos, la definición del modelo (y) únicamente nos lleva una línea pues TensorFlow está diseñado para hacer regresiones de forma muy sencilla.
Definimos dentro de la fase de entrenamiento un concepto básico que es el coste o pérdida para conseguir categorizar una red neuronal como buena o mala. Se denomina coste o pérdida pues representa lo lejos que está nuestro modelo de la red neuronal del resultado esperado. Por ello, tratamos de minimizar el error lo máximo posible.
Una forma de determinar la pérdida del modelo es la entropía cruzada (cross-entropy) que nos permite saber en qué grado se está cometiendo el error. Se define con la siguiente fórmula:
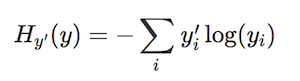
Donde y representa la probabilidad predicha y y' representa la probabilidad real obtenida por el modelo (el vector one-hot de probabilidades para cada dígito). La entropía nos permite fijar un valor al nivel de desajuste de la teoría a la realidad en los resultados.
La implementación de la entropía se realiza definiendo primero un placeholder para almacenar los valores correctos:
y_ = tf.placeholder(tf.float32, [None, 10])Tras dicha definición se implementa la entropía cruzada como:
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))En la implementación tf.log calcula el logaritmo de cada elemento de y, después multiplica cada elemento de y_ con el elemento correspondiente de tf.log(y). tf.reduce_sum suma los elementos de la segunda dimensión de y y tf.reduce_mean realiza la media de cada uno de los elementos de dicha suma.
Ahora que tenemos el modelo definido junto a la implementación de la entropía podemos ejecutarlo mediante TensorFlow de forma que se minimice la entropía utilizando el algoritmo del descenso de gradiente con una tasa de aprendizaje de 0.5.
El descenso de gradiente es un algoritmo utilizado de forma que TensorFlow desplaza con pequeñas modificaciones cada variable en la dirección correcta para reducir su pérdida o coste. Se implementa de la siguiente forma:
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)Tras definir todos las variables implicadas en el proceso de entrenamiento de la red neuronal, procedemos a ejecutar dicho entrenamiento con un bucle de 1000 repeticiones:
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})En cada pasada del bucle obtenemos un conjunto de puntos al azar de nuestro conjunto de test. Realizamos el entrenamiento de dichos datos y reemplazamos los placeholders.
El hecho de usar conjuntos pequeños de datos se llama entrenamiento estocástico, es decir, un descenso de gradiente estocástico. Realmente, lo ideal sería utilizar el conjunto completo de los datos pero no sería eficiente desde el punto de vista computacional, así que lo que hacemos es usar un subconjunto diferente en cada pasada del bucle para ir entrenando la red neuronal por partes.
Este es uno de los pasos más importantes pues realmente es donde evaluamos el nivel de "bien" o "mal" que funciona nuestra red neuronal. Es decir, si clasifica bien o no.
Lo que hacemos es obtener mediante tf.argmax(y,1) el valor más alto de la predicción de probabilidades de cada imagen respectivo a cada tipo (dígito). Es decir, obtenemos el valor más alto que nuestra red neuronal le ha dado a una imagen relativo a cada dígito (seleccionar la probabilidad más alta = qué dígito se ha asignado a la imagen).
Tras ello, seleccionamos el valor real para la misma imagen (ya que estamos tratando con conjuntos de test y sabemos a qué dígito corresponde cada imagen.
Teniendo los dos valores, aplicamos una comprobación que nos devuelve si es igual o no y a ello le aplicamos la media para obtener en qué grado se equivoca nuestra red neuronal. Por ejemplo, teniendo [True, False, True, True] la media que obtenemos es 0,75.
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))Para finalizar con la evaluación, imprimimos por pantalla el porcentaje de precisión obtenida por nuestra red neuronal.
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))El valor obtenido debería ser en torno al 92%, un valor alto pero no bueno precisamente. Como mencionamos al principio de este tutorial, softmax es un modelo de análisis estadístico de redes neuronales pero realmente con demasiada simpleza. Existen otros modelos más avanzados que nos aumentan la precisión a un 99,7% pero que a su vez aumentan la complejidad de implementación y el grado de coste computacional se eleva.