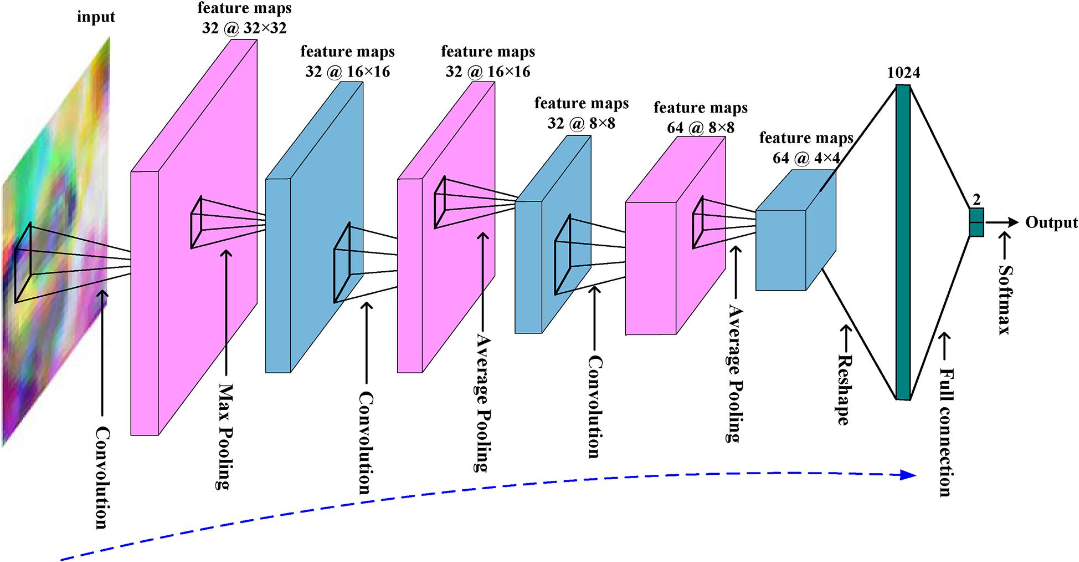
 (Image from the article: https://www.frontiersin.org/articles/10.3389/fnins.2018.00777/full, to represent a 2D-CNN)
(Image from the article: https://www.frontiersin.org/articles/10.3389/fnins.2018.00777/full, to represent a 2D-CNN)
The aim of this project is to apply 2D convolution neural networks (CNNs) to visually perform speaker recognition. The CNNs are applied to "see" audios representations generated from the original audios by an algorithm.
The following libs were used:
- pandas
- numpy
- torch
- matplotlib
- librosa
- sklearn
The versions are the default used on google colab in the ned of 2022, as the project was done using it. I hope the most recent versions installed with pip (whenever you are reading this) might work as well.
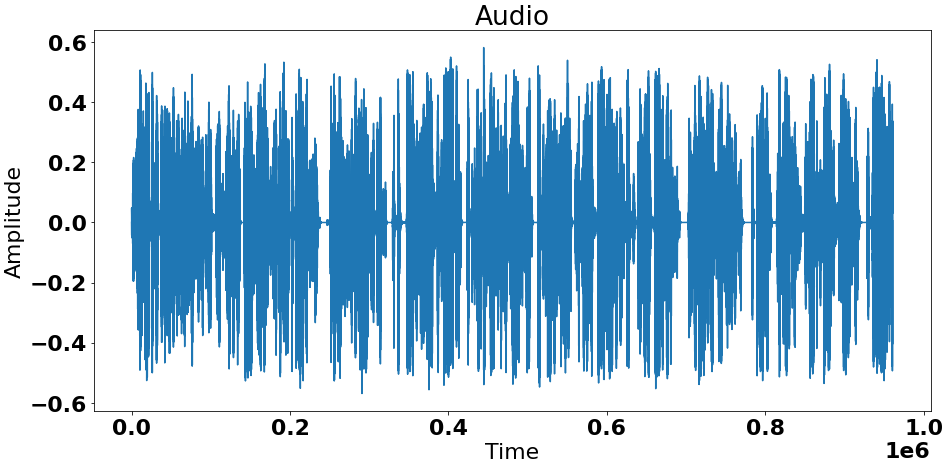
This project uses the dataset: https://www.kaggle.com/datasets/vjcalling/speaker-recognition-audio-dataset, which has 50 different speakers. Only 10 of them were used due to lack of memory resources. All this audios were converted to a single vector with each position being a value related to the volume at some moment of time.
The following image shows an example:
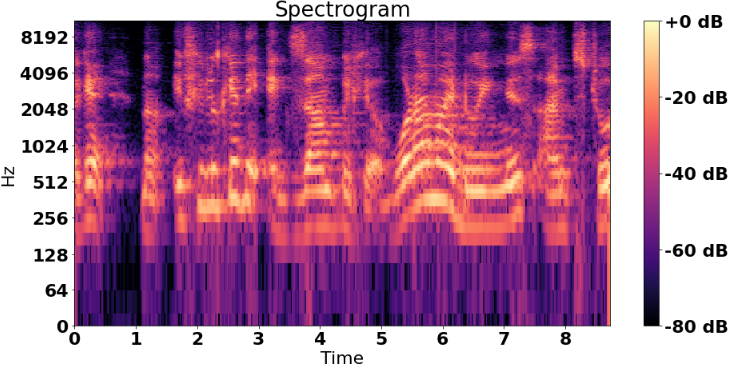
There are 1D convolution neural nets, which might work for this problem. But this project uses 2D CNNs that works on images. To adapt the representation it is necessary to transform the input into a series of images. The algorithm used was a composition of the results of many Fast Fourier Transforms stacked applied to sections of the original audio. Besides this main part of the algorithm, several approchas to split the audios were tried to increase the number of samples of each speaker and decrease the size of the images without compromising their quality.
The following image is an example of the transformation:
3 types of sizes of CNNs were used (gradually increasing the number of parameters), with 3 types of challenges: binary classification, classification of 5 speakers, classification of 10 speakers.