GPU development demands deep expertise across CUDA, parallel computing, and performance optimization. Developers frequently context-switch between documentation, code examples, and best practices scattered across multiple sources. Traditional code assistants lack the specialized knowledge required for high-performance GPU programming.
This blueprint deploys Nsight Copilot on DGX Spark — a self-hosted backend for the Nsight Copilot Visual Studio Code extension that delivers expert-level, contextually aware answers to complex CUDA challenges, generates optimized CUDA snippets and kernels from natural language descriptions, and grounds every response in authoritative CUDA documentation via retrieval-augmented generation. Developers can run the backend locally on DGX Spark and connect the IDE extension without sending prompts or code to an external service. Benchmarked using the ComputeEval framework for assessing CUDA-related task proficiency.
Third-Party Software Notice This project will download and install additional third-party open source software projects. Please review the license terms of these open source projects before use.
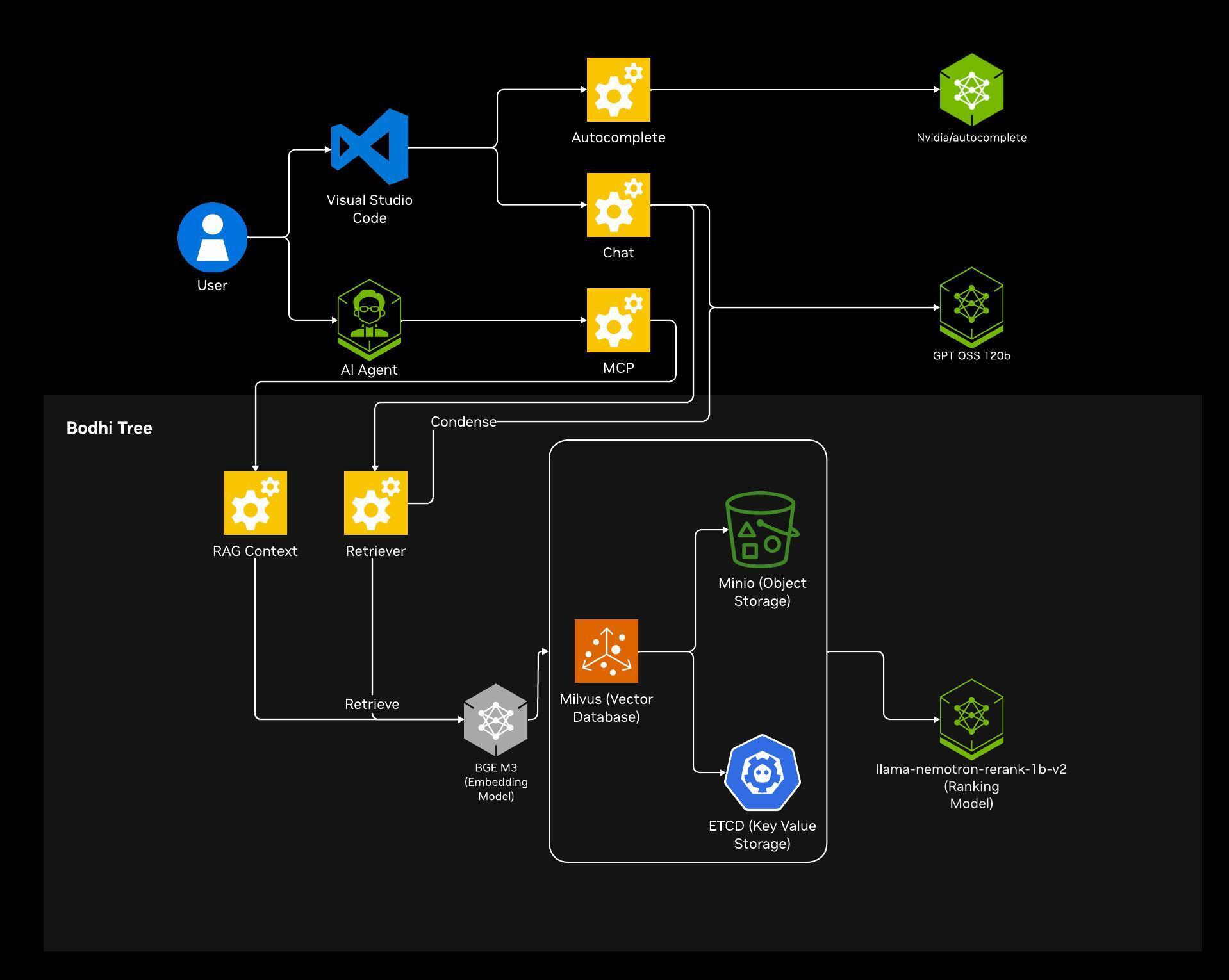
- Expert CUDA-Aware Chat — Multi-turn conversational AI with OpenAI-compatible streaming that delivers expert-level answers to complex CUDA challenges — from architectural best practices to deep-dive conceptual explanations.
- CUDA Code Generation and Autocompletion — Generate complex, optimized CUDA snippets and kernels from natural language descriptions. Real-time inline code completions powered by the
nvidia/CUDA-autocompletemodel provide low-latency suggestions with minimal time-to-first-token. - Interactive Code Transformation — Directly modify and optimize CUDA code in the editor — refactoring for efficiency, converting PyTorch operations into optimized CUDA kernels, and ensuring compatibility with NVIDIA technologies.
- CUDA Knowledge Retrieval (RAG) — Retrieval-augmented generation powered by Bodhi Tree RAG surfaces relevant documentation, code examples, and best practices from an authoritative CUDA knowledge corpus — including CUDA Toolkit documentation, programming guides, and optimization references.
- Supported IDE Clients — Visual Studio Code and compatible forks; see Use the Blueprint for the full list and connection points.
- gpt-oss-120b NIM — LLM for chat and RAG-augmented code generation
- nvidia/CUDA-autocomplete — Specialized model for real-time CUDA code completion
- llama-nemotron-rerank-1b-v2 NIM — Reranking model for retrieval relevance
- BAAI/bge-m3 — Embedding model for CUDA knowledge corpus
- vLLM — High-performance model serving
- LiteLLM — Unified model routing proxy
- FastAPI — Async web framework with SSE streaming
- NVIDIA DGX Spark
- At least 200 GB of free disk space for Docker images, model weights, caches, and vector database data
- Ubuntu 22.04+
- Docker with Compose v2
- NVIDIA Container Toolkit
The recommended way to get started is to deploy the blueprint with Docker Compose on a DGX Spark. For details, refer to Deploy with Docker Compose.
After deployment, connect a client to the local backend running on the DGX Spark. The primary client is the Nsight Copilot Visual Studio Code extension; VS Code-compatible forks may also work. For the supported clients and step-by-step setup, see Connect from IDE.
The default offline Compose deployment serves prompts and code locally through containers on the DGX Spark. NGC access is used for image and model downloads; do not override local model endpoints to external services unless your deployment policy allows code or prompt data to leave the machine.
This project is not currently open to external code contributions. We welcome bug reports, feature requests, and feedback — please file an issue.
NVIDIA believes Trustworthy AI is a shared responsibility, and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their supporting model team to ensure the models meet requirements for the relevant industry and use case and address unforeseen product misuse. For more detailed information on ethical considerations for the models, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards. Please report security vulnerabilities or NVIDIA AI concerns here.
This NVIDIA AI Blueprint is licensed under the Apache License, Version 2.0. This project will download and install additional third-party open source software projects and containers. Review the license terms of these open source projects before use.
Use of the models in this blueprint is governed by the NVIDIA AI Foundation Models Community License.
GOVERNING TERMS: This blueprint uses the following components, which are governed by the terms listed below:
Use of Night Copilot is governed by NVIDIA Technology Access Terms of Use and the CUDA content is governed by the License Agreement for NVIDIA Software Development Kits and CUDA Toolkit Supplement to Software License Agreement for NVIDIA Software Development Kits.
Use of gpt-oss-120b & llama-nemotron-rerank-1b-v2 NIM containers is governed by the NVIDIA Software License Agreement and Product-Specific Terms for NVIDIA AI Products.
Use of gpt-oss-120b, bge-m3, llama-nemotron-rerank-1b-v2 & cuda-autocomplete models is governed by the NVIDIA Open Model License Agreement.
gpt-oss-120b model is licensed under Apache License, Version 2.0.
llama-nemotron-rerank-1b-v2 is licensed under Llama 3.2 Community Model License Agreement. Built with Llama.
CUDA Autocomplete model is based on Qwen2.5-Coder-7B model, which is licensed under Apache License, Version 2.0.