{kind=link}
SDOFMv2: A Multi-Instrument Foundation Model for the Solar Dynamics Observatory with Transferable Downstream Applications
SDOFMv2 is an advanced multi-instrument foundation model for analyzing Solar Dynamics Observatory (SDO) data, designed to drive large-scale, data-driven heliophysics research. Building on the original SDOFM framework, this version improves spatial coherence and global consistency by addressing limitations in temporal coverage and reconstruction artifacts.
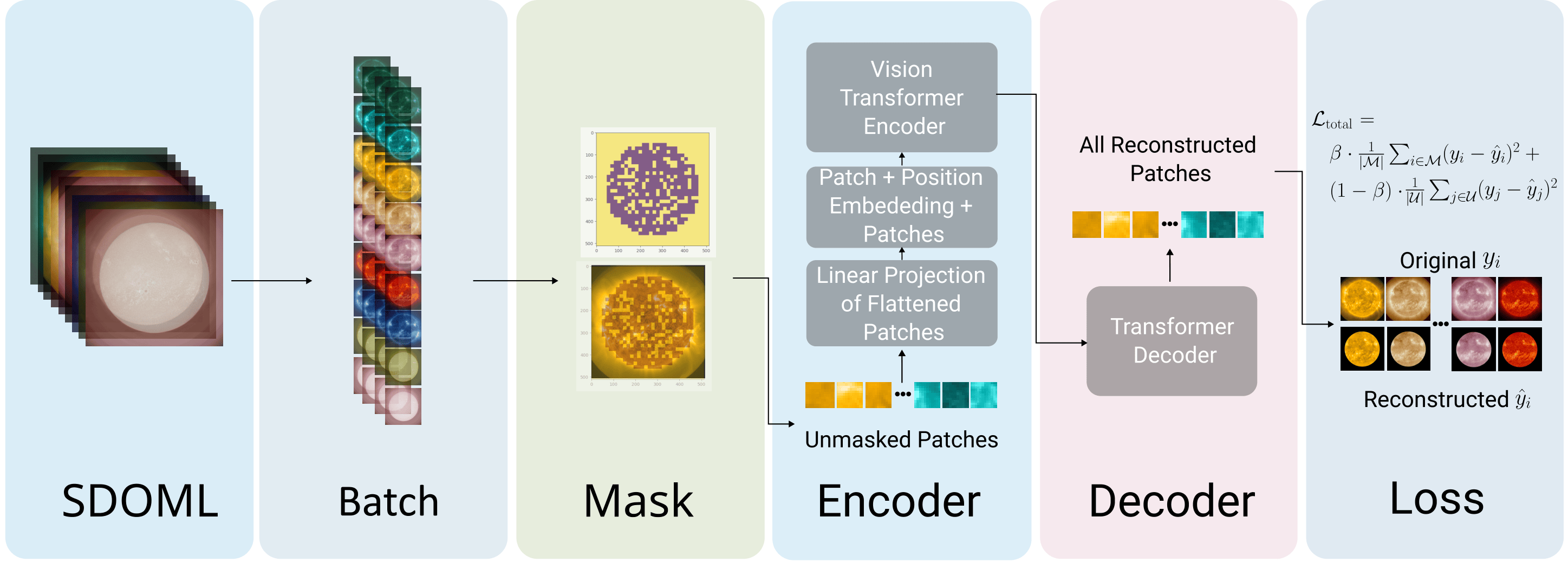
A Masked Autoencoder (MAE) built on a Vision Transformer (ViT) backbone is used for pretraining. During training, a% of image patches are masked; the remaining (100 - a)% are processed by the encoder. The decoder then reconstructs all patches, optimized via a customized loss function.
- Getting Started
- Repository Structure
- Data Preparation
- Training & Evaluation
- Results & Visualizations
- Citation
- Acknowledgments
For full documentation, please visit sdofmv2.readthedocs.io.
- Python 3.11+
- NVIDIA GPU + CUDA toolkit (recommended for training)
We use mamba (or conda) for fast dependency resolution.
Hardware Note:
sdofmv2_environment.ymlis configured for CUDA 12.8 by default. If your system requires a different CUDA version (e.g., 11.8), edit thepipsection insdofmv2_environment.ymlbefore running setup — changecu128to the appropriate tag (e.g.,cu118).
# Clone the repository
git clone https://github.com/Joaggi/sdofmv2.git
cd sdofmv2
# Create and activate the environment
# (installs PyTorch and the local package automatically)
mamba env create -f sdofmv2_environment.yml
mamba activate sdofmv2Pretrained model checkpoints are available on Hugging Face:
# Using the Hugging Face Hub
mamba install huggingface_hub -c conda-forge
huggingface-cli download joseph-gallego/sdofmv2.
├── configs/ # YAML configurations for experiments
│ ├── downstream/ # Configs for downstream tasks (F10.7, solar wind)
│ └── pretrain/ # Configs for MAE pretraining (AIA, HMI)
├── notebooks/ # Jupyter notebooks for analysis and visualization
│ ├── analysis/ # Attention maps, PCA, and masking analysis
│ └── downstream_apps/ # Downstream application demos (F10.7, missing data)
├── scripts/ # Executable training and evaluation scripts
│ ├── pretrain.py # Main pretraining script
│ ├── finetuning_*.py # Downstream finetuning scripts
│ ├── test.py # Checkpoint evaluation script
│ └── download_data.py # Resumable dataset downloader
├── src/
│ └── sdofmv2/
│ ├── core/ # Base model architectures and modules
│ ├── tasks/ # PyTorch Lightning modules for downstream tasks
│ └── utils/ # Helper functions, physical constants, and metrics
├── pyproject.toml # Project metadata and build dependencies
└── sdofmv2_environment.yml # Mamba environment definition
SDOFMv2 uses the SDOMLv2 dataset — a curated, multi-instrument dataset for the Solar Dynamics Observatory, hosted on NASA's HDRL S3 bucket. Data is streamed via s3fs and stored in the Zarr format.
| Component | Instrument | Data Type | Approx. Size | Description |
|---|---|---|---|---|
aia |
AIA | EUV Images | ~7.2 TB | 9 extreme ultraviolet channels capturing the solar atmosphere |
hmi |
HMI | Magnetograms | ~713 GB | 3-component vector magnetic field (Bx, By, Bz) for the solar photosphere |
Storage: Zarr datasets require significant local disk space. Verify your target drive has sufficient capacity before downloading.
The download script is resumable — it checks for existing local files and only fetches what's missing.
# Download AIA only
python scripts/download_data.py --target /path/to/your/storage --component aia
# Download HMI only
python scripts/download_data.py --target /path/to/your/storage --component hmi
# Download the full dataset
python scripts/download_data.py --target /path/to/your/storage --component bothAfter download, the data is organized as follows:
data/
├── sdomlv2.zarr/ # AIA multi-channel dataset
│ ├── .zgroup # Group hierarchy metadata
│ ├── 2010/
│ │ ├── 131A/ # EUV channel (131 Å)
│ │ ├── 1600A/ # EUV channel (1600 Å)
│ │ └── ... # Other AIA channels (193, 211, 304, etc.)
│ └── ...
└── sdomlv2_hmi.zarr/ # HMI magnetic field dataset
├── .zgroup
└── 2010/
├── Bx/ # Magnetic field component
└── By/ # Magnetic field component
Unlike monolithic file formats (e.g., .fits), the chunked Zarr layout enables high-speed random access — data loaders can read specific time slices or channels without loading the full multi-terabyte dataset into memory.
python scripts/pretrain.py --config-name pretrain_mae_AIA.yamlpython scripts/test.py --config-name pretrain_mae_AIA.yaml# Example: solar wind forecasting
python scripts/finetuning_solarwind.py --config-name finetune_solarwind_config.yamlConfiguration files for all tasks are in configs/downstream/. Notebook-based walkthroughs are available in notebooks/downstream_apps/.
Our MAE trained on AIA data successfully reconstructs SDO solar images at high quality.

Row 1: Ground-truth images. Row 2: Reconstructions at 0% masking ratio. Row 3: Reconstructions at 50% masking ratio.
If SDOFMv2 is useful in your research, please cite:
@misc{sdofmv2,
author = {Hong, Jinsu and Martin, Daniela and Gallego, Joseph},
title = {SDOFMv2: A Multi-Instrument Foundation Model for the Solar Dynamics Observatory with Transferable Downstream Applications},
year = {2026},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/Joaggi/sdofmv2}},
note = {Jinsu Hong, Daniela Martin, and Joseph Gallego contributed equally to this work}
}Contributions, bug reports, and feature requests are welcome! Please check the issues page or open a pull request.
This work builds on the SDOFM framework developed by Trillium Technologies Inc. We thank the creators of SDOMLv2 for providing the curated multi-wavelength training data, and the NASA Solar Dynamics Observatory mission for open data access.