Add performance profiling as a standard zstash test#427
Conversation
|
Action items:
|
|
Results from running on 2026-04-02: 
Notes:
Setupcd ~/ez/zstash
git status
# On branch force-fork-parallel
# nothing to commit, working tree clean
git checkout add-performance-profiling
git log --oneline | head -n 10
# 9d6d15f Fixes made comparing pr402 and pr424
# a6cbc12 Update parameters
# 7467b68 Improve plots
# def78ac Fixes to generate plots
# ee61184 Add ability to configure hpss options
# c3ead41 Add regression testing
# 8662955 Send output to web server
# 8c3c555 Apply changes from Claude
# ee2dda7 Add performance profiling as a standard zstash test
# c14b8ee Add AGENTS.md (#423)
# Good, matches https://github.com/E3SM-Project/zstash/pull/427/commits
nersc_conda
rm -rf build
conda clean --all --y
conda env create -f conda/dev.yml -n zstash-pr427-performance-profile-20260402
conda activate zstash-pr427-performance-profile-20260402
pre-commit run --all-files
python -m pip install .
cd tests/performance
emacs generate_performance_data.bash # Edit parameters
git diff # Check diff
./generate_performance_data.bash
# ~2-3 hours to run, note there is the manual step to paste an auth code
# [SUCCESS] All tests completed. Results saved to: /pscratch/sd/f/forsyth/zstash_performance/performance_20260402/results.csv
# [INFO] Now edit IO paths and run: python visualize_performance.py
emacs visualize_performance.py # Edit parameters
git diff # Check diff
pre-commit run --all-files
git add -A
python visualize_performance.py
# Figure 1 (overview) saved to: /global/cfs/cdirs/e3sm/www/forsyth/zstash_performance/performance__20260402_pr427.png
# Accessible at: https://portal.nersc.gov/cfs/e3sm/forsyth/zstash_performance/performance__20260402_pr427.png |
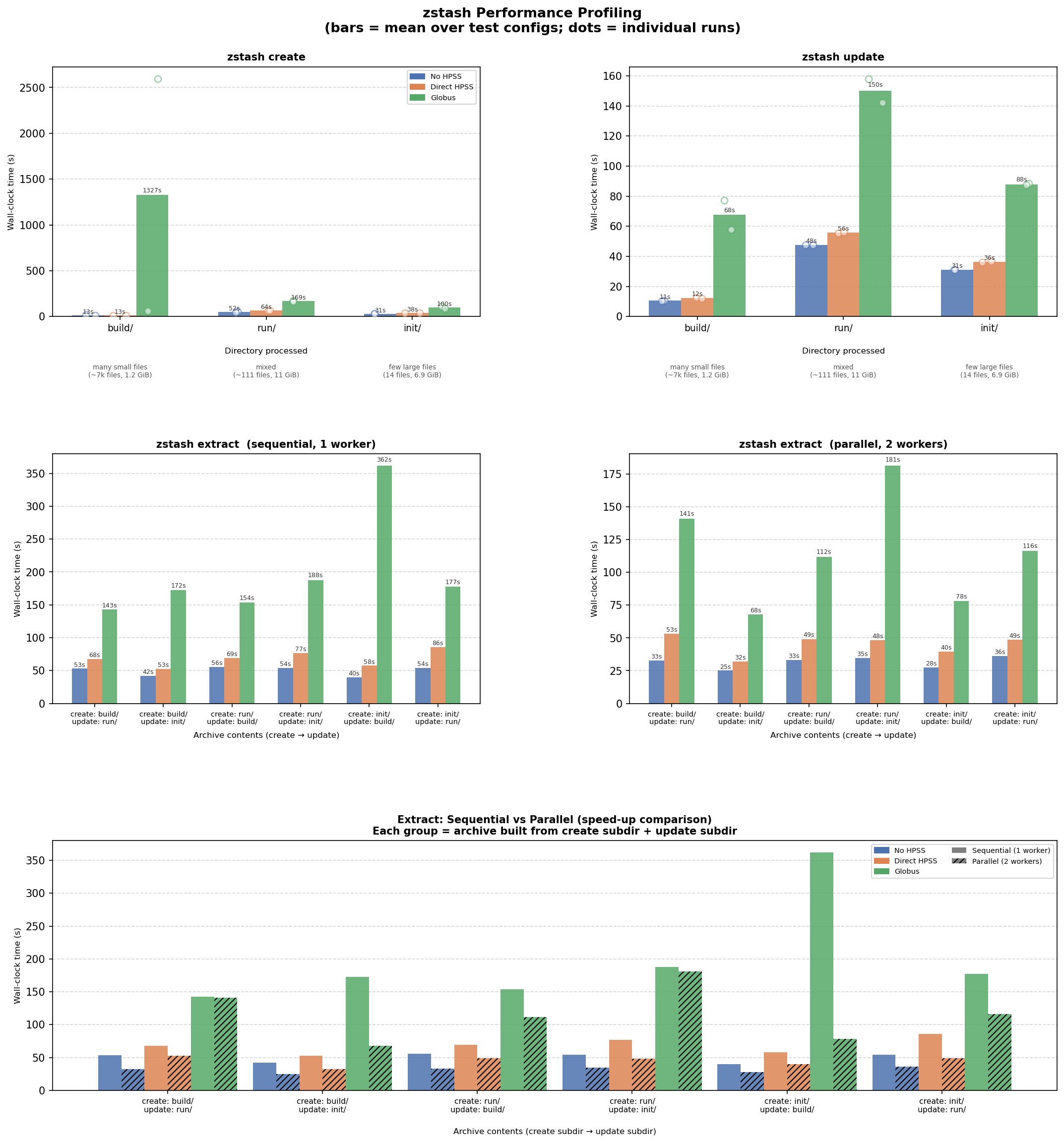{kind=link}
2a3d7dc to
1cb3eb8
Compare
|
Rebased off the latest Latest commit 1cb3eb8 is Claude's resolution of:
For reference, previous plots:
Remaining action items:
|
Setupnersc_conda # Activate conda
rm -rf build
conda clean --all --y
conda env create -f conda/dev.yml -n zstash-pr427-20260603
conda activate zstash-pr427-20260603
pre-commit run --all-files
# Make changes to tests/performance/visualize_performance.py
python -m pip install .
cd tests/performance/
python visualize_performance.py
# Figure 1 (overview) saved to: /global/cfs/cdirs/e3sm/www/forsyth/zstash_performance/performance_pr427_20260603.png
# Accessible at: https://portal.nersc.gov/cfs/e3sm/forsyth/zstash_performance/performance_pr427_20260603.png
# Figure 2 (baseline comparison) saved to: /global/cfs/cdirs/e3sm/www/forsyth/zstash_performance/performance_pr427_20260603_vs_baseline.png
# Accessible at: https://portal.nersc.gov/cfs/e3sm/forsyth/zstash_performance/performance_pr427_20260603_vs_baseline.pngFig1: https://portal.nersc.gov/cfs/e3sm/forsyth/zstash_performance/performance_pr427_20260603.png 

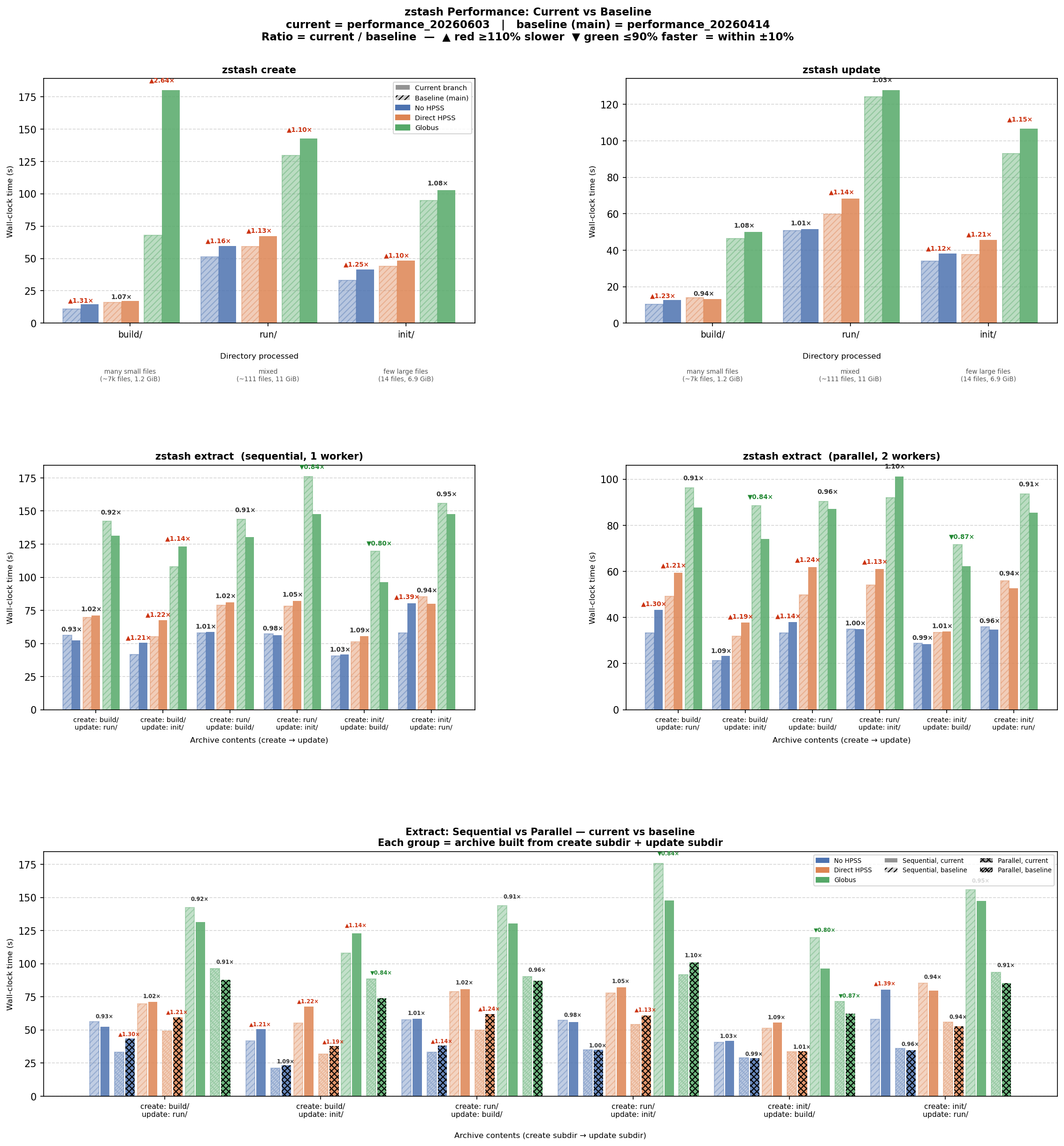
✅ "baseline" bars are now to to the left of the "current" bars |
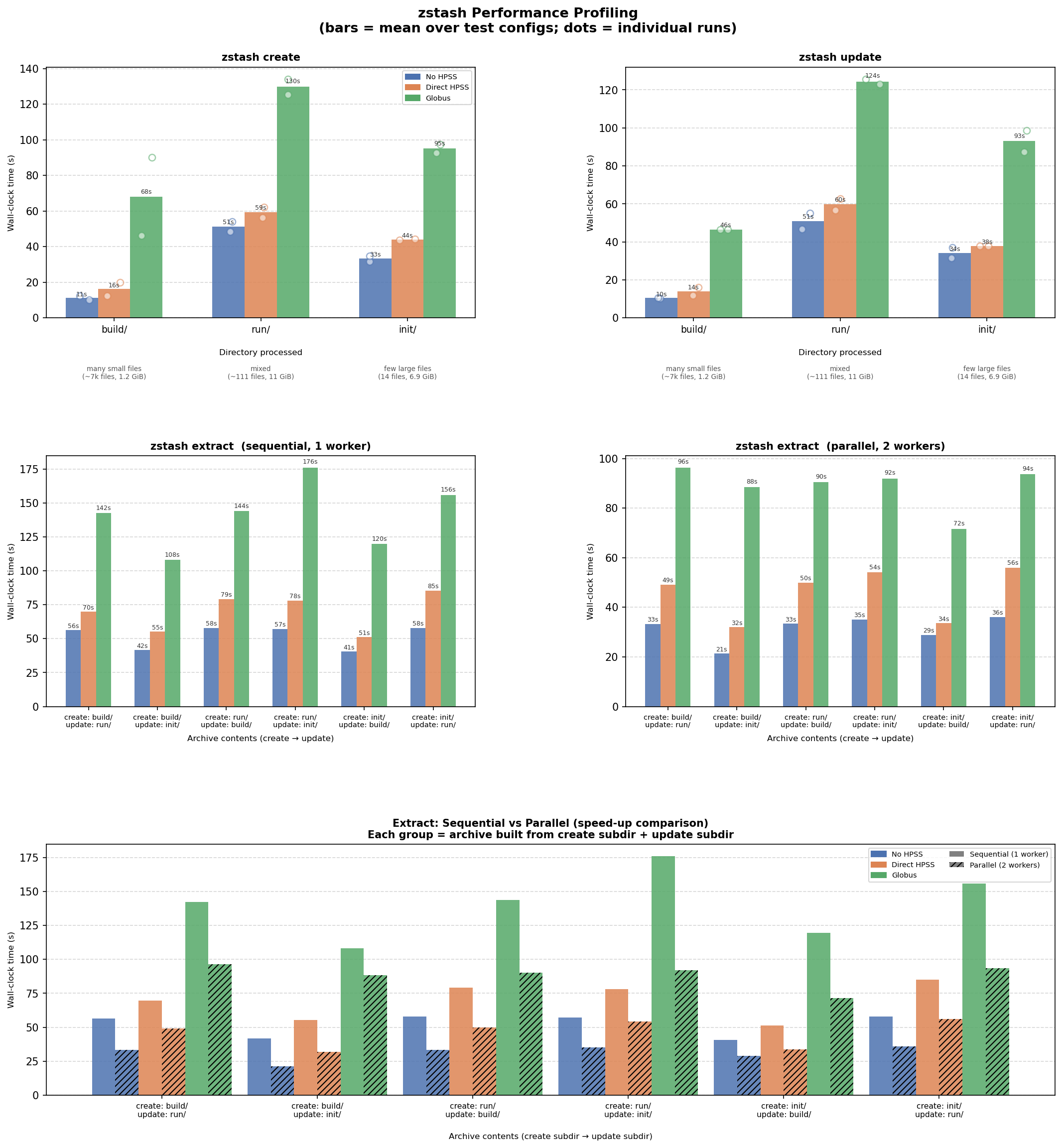{kind=link}
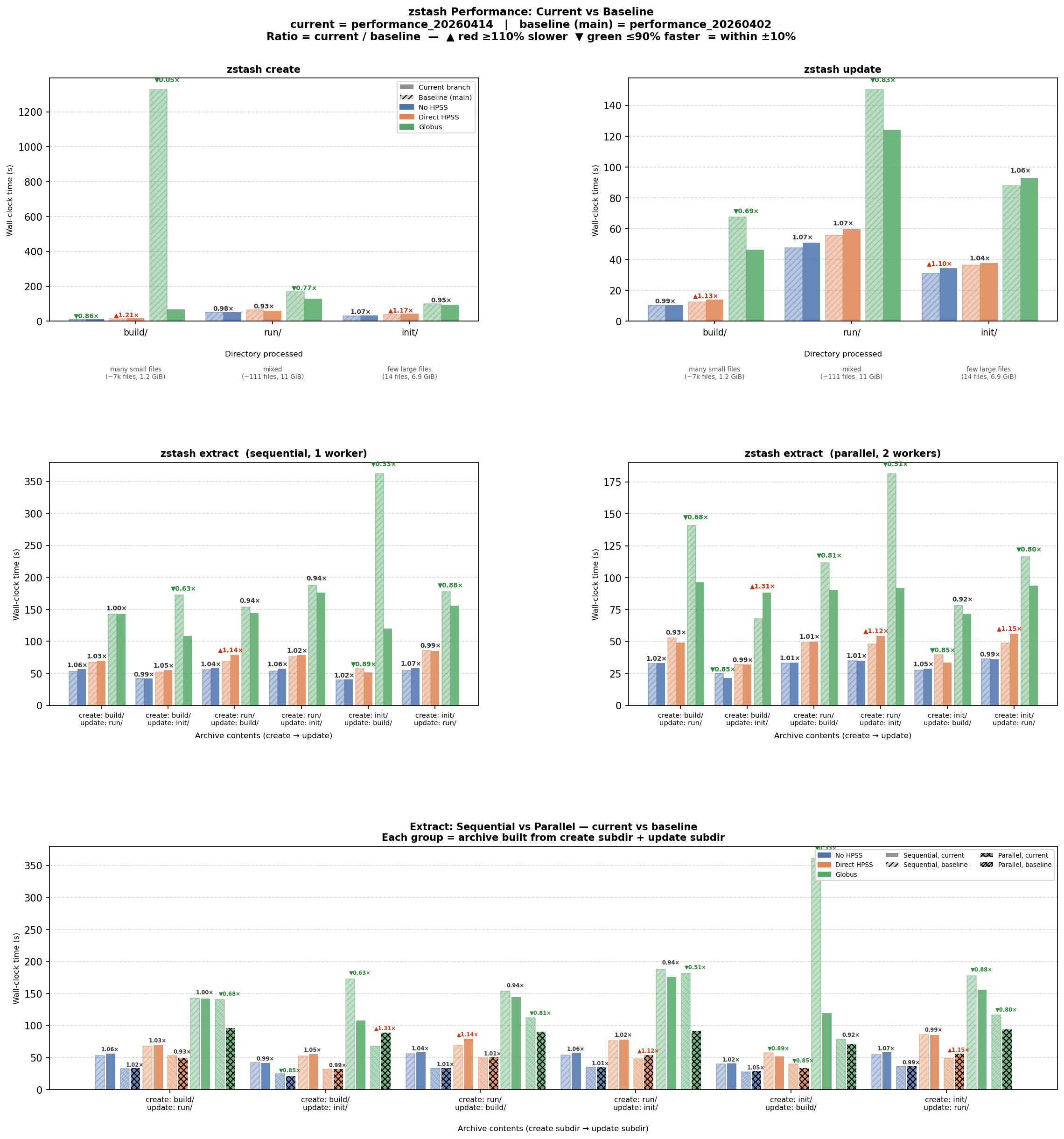{kind=link}
|
@forsyth2 would it possible to do the performance profiling for |
There was a problem hiding this comment.
Pull request overview
Adds a new, documented performance profiling workflow under tests/performance/ to
measure and visualize zstash runtime across operation modes and HPSS settings,
and updates the dev Conda environment to support the visualization tooling.
Changes:
- Add a Perlmutter-oriented performance data generation script that records
zstash create/update/extractruntimes into a CSV. - Add a Python visualization script to plot performance results and optionally
compare against a baseline run. - Document the performance profiling workflow and link it from the main tests
README; add plotting/data dependencies to the dev Conda environment.
Reviewed changes
Copilot reviewed 5 out of 5 changed files in this pull request and generated 8 comments.
Show a summary per file
| File | Description |
|---|---|
tests/README.md |
Adds a pointer to the new performance profiling docs. |
tests/performance/README.md |
Documents how to generate and visualize performance CSVs. |
tests/performance/generate_performance_data.bash |
Generates performance CSV by running a matrix of zstash operations/modes. |
tests/performance/visualize_performance.py |
Plots performance results and optional current-vs-baseline comparisons. |
conda/dev.yml |
Adds matplotlib-base, pandas, and numpy to support visualization. |
💡 Add Copilot custom instructions for smarter, more guided reviews. Learn how to get started.
I'm assuming you mean new/recent reports? I know we resolved the high-res team's issues by making more use of the
I think that's good idea, but can we do it as a separate pull request? I think this PR is pretty close to merging, and I'd like to have something on For what it's worth, Claude's assessment: Looking at the code, adding Arguments for a separate PR:
Arguments for doing it now:
My recommendation: separate PR. The current PR is clean and self-contained. |
|
There's also backwards compatibility concerns with the existing performance records, which is another point in favor of handling |
Yes, correct.
In any case, yes, we should pursue this. I'll plan to get this PR in and then separately look into |
c04a73e to
258c90c
Compare
|
I created #446 to track the work on |
Running latest changesProcessEdit cd tests/performance/
./generate_performance_data.bashThis took between 1 and 2 hours. About 10 minutes in, it asks for the Globus auth code. At the end of its run, it prints: Edit python visualize_performance.pyThis runs very fast. At the end of its run, it prints: Output formatThe output format continues to look as expected: ✅ "baseline" bars are now to to the left of the "current" bars The results themselvesWe're comparing to 2026-04-14, so we're seeing the performance changes of these commits (plus random variation): Fig1: https://portal.nersc.gov/cfs/e3sm/forsyth/zstash_performance/performance_pr427_20260603_run2.png 

|
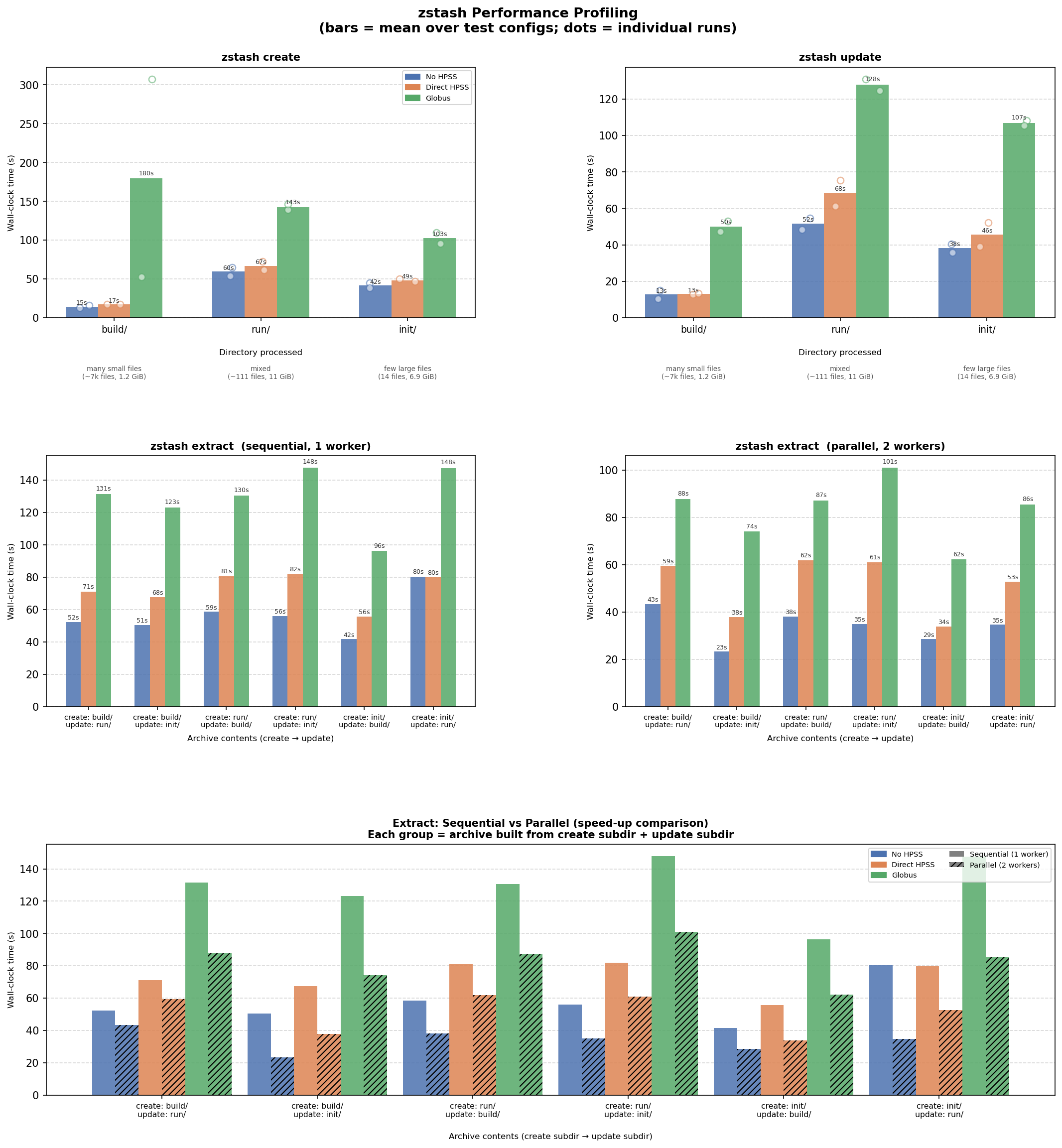{kind=link}
{kind=link}
 forsyth2
left a comment
forsyth2
left a comment
There was a problem hiding this comment.
In addition to my latest test run, I've now done a high-level visual inspection of this largely-AI generated diff.
| # --- EXTRACT (sequential=1 worker, parallel=2 workers) --- | ||
| for num_workers in 1 2; do | ||
| extract_log="${log_dir}extract_${hpss_label}_${num_workers}workers.log" | ||
| extract_dir="${mode_dir}extract_${num_workers}workers/" |
There was a problem hiding this comment.
Just a note for implementing the performance profiling piece of #446
For this PR, we run extract twice on the same create-update sequence. This can be done simply by using a different extraction dir each time. So, for profiling check, we just need a third dir. Certainly no need to rerun the create-update sequence.
(There's still the question of how to fit check into the existing PDF, which is already fairly busy).
forsyth2
left a comment
There was a problem hiding this comment.
I think this is ready to merge. Further additions are planned (notably #446 for zstash check, and maybe also some sort of averages plot built on many records over time).
@chengzhuzhang @TonyB9000 I imagine I'll be the primary user of this for-developers feature, but do either of you want to review it before I merge it?
Created #449 |
|
Hi @forsyth2 The work looks great. I admit to finding it hard to understand certain aspects of the plots (build, run, init). I get the "before" (hashed color) and "after" (latest branch). I think of zstash operations involving disk i/o, (reads, writes), hashing of contents for integrity, and network-transfers. Come to think of it, strong (crypto-strength) hashing (MD5, SHA) is quite slow, as the intent is to thwart deliberate content manipulation (faking signatures in financial transactions, etc). For zstash, (and tarfiles in general), we only "hash" to detect simple corruption (bad bit-reads, etc). For that purpose, one could use a simple CRC (cyclic redundancy check) which is far faster as a "hashing" function. |
|
Thanks Tony!
Those are really just meant to test directories of 3 different types:
That's an interesting suggestion. This is worth considering further! |
@TonyB9000 When I ask Copilot, it says: Based on this codebase, switching MD5 to CRC would likely give only a moderate end-to-end speedup, not a dramatic one.
Implementation difficulty: moderate. Why moderate (not trivial):
So: possible and worthwhile if CPU hashing is a bottleneck, but not a guaranteed large global speedup. |
|
@forsyth2 I concur. Usually, disk i/o swamps CPU considerations. So if hashing currently accounts for 3% of overall processing, reducing it to 1% won;t give you much improvement. And if many related systems expect to see an MD5 hash, it could be a hassle replacing it with something else. |
Summary
#414 introduced some early performance profiling for
zstash, but these changes were not ultimately included inmain. However, performance is becoming an ever more important feature ofzstash, as that work showed. Other issues relating to performance: #402/#424, #249.Objectives:
zstashruntimes on various combinations of variables:create,update,extractextractsequential vs parallel mode (especially relevant for Add Python 3.14 support #402/Fix Python 3.14 compatibility: AbsoluteLinkError, pickling errors, config propagation, HPSS hang, and print_all_contents deadlock in extract.py and parallel.py #424)--hpssas "none", an HPSS path, or a Globus pathSelect one: This pull request is...
Small Change