 +
+
+ اللوحة اليسرى تجمع نقاط الحفظ حسب الفرع؛ التفرعات تتداخل تحت أبيها. اختيار نقطة حفظ يفتح لوحة التفاصيل مع بياناتها الوصفية وحالة الكيان وتقدم المهام. **Resume** يكمل التشغيل؛ **Fork** يبدأ فرعا جديدا.
+
+
+
+
+
+ اللوحة اليسرى تجمع نقاط الحفظ حسب الفرع؛ التفرعات تتداخل تحت أبيها. اختيار نقطة حفظ يفتح لوحة التفاصيل مع بياناتها الوصفية وحالة الكيان وتقدم المهام. **Resume** يكمل التشغيل؛ **Fork** يبدأ فرعا جديدا.
+
+
+  +
+
+ لوحة التفاصيل تعرض منطقتين قابلتين للتحرير:
+
+ - **Inputs** — مدخلات الـ kickoff الأصلية، معبأة مسبقا وقابلة للتحرير.
+
+
+
+
+
+ لوحة التفاصيل تعرض منطقتين قابلتين للتحرير:
+
+ - **Inputs** — مدخلات الـ kickoff الأصلية، معبأة مسبقا وقابلة للتحرير.
+
+
+  +
+
+ - **مخرجات المهام** — مخرجات المهام المكتملة. تحرير مخرج والضغط على **Fork** يبطل المهام التابعة لتعاد بالسياق المعدل.
+
+
+
+
+
+ - **مخرجات المهام** — مخرجات المهام المكتملة. تحرير مخرج والضغط على **Fork** يبطل المهام التابعة لتعاد بالسياق المعدل.
+
+
+  +
+
+
+
+
+
+
+  +
+
+
+
+
+ CLI: crewai train -n -f
or Python: crew.train(...)"] --> B["Setup training mode
- task.human_input = true
- disable delegation
- init training_data.pkl + trained file"] + + subgraph "Iterations" + direction LR + C["Iteration i
initial_output"] --> D["User human_feedback"] + D --> E["improved_output"] + E --> F["Append to training_data.pkl
by agent_id and iteration"] + end + + B --> C + F --> G{"More iterations?"} + G -- "Yes" --> C + G -- "No" --> H["Evaluate per agent
aggregate iterations"] + + H --> I["Consolidate
suggestions[] + quality + final_summary"] + I --> J["Save by agent role to trained file
(default: trained_agents_data.pkl)"] + + J --> K["Normal (non-training) runs"] + K --> L["Auto-load suggestions
from trained_agents_data.pkl"] + L --> M["Append to prompt
for consistent improvements"] +``` + +### أثناء تشغيلات التدريب + +- في كل تكرار، يسجل النظام لكل وكيل: + - `initial_output`: الإجابة الأولى للوكيل + - `human_feedback`: ملاحظاتك المضمّنة عند الطلب + - `improved_output`: إجابة المتابعة للوكيل بعد الملاحظات +- تُخزن هذه البيانات في ملف عمل باسم `training_data.pkl` مفهرس بمعرّف الوكيل الداخلي والتكرار. +- أثناء نشاط التدريب، يُلحق الوكيل تلقائيًا ملاحظاتك البشرية السابقة بأمره لتطبيق تلك التعليمات في المحاولات اللاحقة ضمن جلسة التدريب. + التدريب تفاعلي: تُعيّن المهام `human_input = true`، لذا سيتوقف التشغيل في بيئة غير تفاعلية بانتظار مدخلات المستخدم. + +### بعد اكتمال التدريب + +- عند انتهاء `train(...)`، يقيّم CrewAI بيانات التدريب المجمعة لكل وكيل وينتج نتيجة موحدة تحتوي على: + - `suggestions`: تعليمات واضحة وقابلة للتنفيذ مستخلصة من ملاحظاتك والفرق بين المخرجات الأولية/المحسنة + - `quality`: درجة من 0-10 تعكس التحسن + - `final_summary`: مجموعة خطوات عمل تفصيلية للمهام المستقبلية +- تُحفظ هذه النتائج الموحدة في اسم الملف الذي تمرره إلى `train(...)` (الافتراضي عبر CLI هو `trained_agents_data.pkl`). تُفهرس الإدخالات بدور الوكيل `role` لتطبيقها عبر الجلسات. +- أثناء التنفيذ العادي (غير التدريب)، يحمّل كل وكيل تلقائيًا `suggestions` الموحدة ويلحقها بأمر المهمة كتعليمات إلزامية. يمنحك هذا تحسينات متسقة بدون تغيير تعريفات الوكلاء. + +### ملخص الملفات + +- `training_data.pkl` (مؤقت، لكل جلسة): + - الهيكل: `agent_id -> { iteration_number: { initial_output, human_feedback, improved_output } }` + - الغرض: التقاط البيانات الخام والملاحظات البشرية أثناء التدريب + - الموقع: يُحفظ في مجلد العمل الحالي (CWD) +- `trained_agents_data.pkl` (أو اسم ملفك المخصص): + - الهيكل: `agent_role -> { suggestions: string[], quality: number, final_summary: string }` + - الغرض: استمرار التوجيه الموحد للتشغيلات المستقبلية + - الموقع: يُكتب في CWD افتراضيًا؛ استخدم `-f` لتعيين مسار مخصص (بما في ذلك المطلق) + +## اعتبارات نماذج اللغة الصغيرة + +
 +
+
+
+
+
+ +
+
+### إشعارات البريد الإلكتروني
+
+تبديل لتفعيل أو تعطيل إشعارات البريد الإلكتروني لطلبات HITL.
+
+| الإعداد | الافتراضي | الوصف |
+|---------|---------|-------------|
+| إشعارات البريد الإلكتروني | مفعّل | إرسال رسائل عند طلب الملاحظات |
+
+
+
+
+### إشعارات البريد الإلكتروني
+
+تبديل لتفعيل أو تعطيل إشعارات البريد الإلكتروني لطلبات HITL.
+
+| الإعداد | الافتراضي | الوصف |
+|---------|---------|-------------|
+| إشعارات البريد الإلكتروني | مفعّل | إرسال رسائل عند طلب الملاحظات |
+
+ +
+
+### هيكل القاعدة
+
+```json
+{
+ "name": "Approvals to Finance",
+ "match": {
+ "method_name": "approve_*"
+ },
+ "assign_to_email": "finance@company.com",
+ "assign_from_input": "manager_email"
+}
+```
+
+### أنماط المطابقة
+
+| النمط | الوصف | مثال المطابقة |
+|---------|-------------|---------------|
+| `approve_*` | حرف بدل (أي أحرف) | `approve_payment`، `approve_vendor` |
+| `review_?` | حرف واحد | `review_a`، `review_1` |
+| `validate_payment` | مطابقة تامة | `validate_payment` فقط |
+
+### أولوية التعيين
+
+1. **تعيين ديناميكي** (`assign_from_input`): إذا تم تهيئته، يسحب البريد من حالة التدفق
+2. **بريد ثابت** (`assign_to_email`): يرجع إلى البريد المهيأ
+3. **منشئ النشر**: إذا لم تتطابق أي قاعدة، يُستخدم بريد منشئ النشر
+
+### مثال التعيين الديناميكي
+
+إذا كانت حالة تدفقك تحتوي على `{"sales_rep_email": "alice@company.com"}`، هيّئ:
+
+```json
+{
+ "name": "Route to Sales Rep",
+ "match": {
+ "method_name": "review_*"
+ },
+ "assign_from_input": "sales_rep_email"
+}
+```
+
+سيتم تعيين الطلب إلى `alice@company.com` تلقائيًا.
+
+
+
+
+### هيكل القاعدة
+
+```json
+{
+ "name": "Approvals to Finance",
+ "match": {
+ "method_name": "approve_*"
+ },
+ "assign_to_email": "finance@company.com",
+ "assign_from_input": "manager_email"
+}
+```
+
+### أنماط المطابقة
+
+| النمط | الوصف | مثال المطابقة |
+|---------|-------------|---------------|
+| `approve_*` | حرف بدل (أي أحرف) | `approve_payment`، `approve_vendor` |
+| `review_?` | حرف واحد | `review_a`، `review_1` |
+| `validate_payment` | مطابقة تامة | `validate_payment` فقط |
+
+### أولوية التعيين
+
+1. **تعيين ديناميكي** (`assign_from_input`): إذا تم تهيئته، يسحب البريد من حالة التدفق
+2. **بريد ثابت** (`assign_to_email`): يرجع إلى البريد المهيأ
+3. **منشئ النشر**: إذا لم تتطابق أي قاعدة، يُستخدم بريد منشئ النشر
+
+### مثال التعيين الديناميكي
+
+إذا كانت حالة تدفقك تحتوي على `{"sales_rep_email": "alice@company.com"}`، هيّئ:
+
+```json
+{
+ "name": "Route to Sales Rep",
+ "match": {
+ "method_name": "review_*"
+ },
+ "assign_from_input": "sales_rep_email"
+}
+```
+
+سيتم تعيين الطلب إلى `alice@company.com` تلقائيًا.
+
+ +
+
+### حالات الاستخدام
+
+- **الامتثال لـ SLA**: ضمان عدم تعليق التدفقات إلى أجل غير مسمى
+- **الموافقة الافتراضية**: الموافقة التلقائية على الطلبات منخفضة المخاطر بعد انتهاء المهلة
+- **التراجع السلس**: المتابعة بافتراضي آمن عندما يكون المراجعون غير متاحين
+
+
+
+
+### حالات الاستخدام
+
+- **الامتثال لـ SLA**: ضمان عدم تعليق التدفقات إلى أجل غير مسمى
+- **الموافقة الافتراضية**: الموافقة التلقائية على الطلبات منخفضة المخاطر بعد انتهاء المهلة
+- **التراجع السلس**: المتابعة بافتراضي آمن عندما يكون المراجعون غير متاحين
+
+ +
+
+### طرق الاستجابة
+
+يمكن للمراجعين الاستجابة عبر ثلاث قنوات:
+
+| الطريقة | الوصف |
+|--------|-------------|
+| **الرد عبر البريد** | الرد مباشرة على رسالة الإشعار |
+| **لوحة التحكم** | استخدام واجهة لوحة تحكم المؤسسة |
+| **API/Webhook** | استجابة برمجية عبر API |
+
+### السجل ومسار التدقيق
+
+يتم تتبع كل تفاعل HITL بجدول زمني كامل:
+
+- سجل القرارات (موافقة/رفض/مراجعة)
+- هوية المراجع والطابع الزمني
+- الملاحظات والتعليقات المقدمة
+- طريقة الاستجابة (بريد/لوحة تحكم/API)
+- مقاييس وقت الاستجابة
+
+## التحليلات والمراقبة
+
+تتبع أداء HITL مع تحليلات شاملة.
+
+### لوحة تحكم الأداء
+
+
+
+
+
+### طرق الاستجابة
+
+يمكن للمراجعين الاستجابة عبر ثلاث قنوات:
+
+| الطريقة | الوصف |
+|--------|-------------|
+| **الرد عبر البريد** | الرد مباشرة على رسالة الإشعار |
+| **لوحة التحكم** | استخدام واجهة لوحة تحكم المؤسسة |
+| **API/Webhook** | استجابة برمجية عبر API |
+
+### السجل ومسار التدقيق
+
+يتم تتبع كل تفاعل HITL بجدول زمني كامل:
+
+- سجل القرارات (موافقة/رفض/مراجعة)
+- هوية المراجع والطابع الزمني
+- الملاحظات والتعليقات المقدمة
+- طريقة الاستجابة (بريد/لوحة تحكم/API)
+- مقاييس وقت الاستجابة
+
+## التحليلات والمراقبة
+
+تتبع أداء HITL مع تحليلات شاملة.
+
+### لوحة تحكم الأداء
+
+
+  +
+
+
+
+
+ +
+
+### تهيئة Webhooks
+
+
+
+
+### تهيئة Webhooks
+
+ +
+
+## المستخدمون والأدوار
+
+يُعيَّن لكل عضو في مساحة عمل CrewAI دور يحدد صلاحيات الوصول عبر الميزات المختلفة.
+
+يمكنك:
+
+- استخدام الأدوار المحددة مسبقاً (Owner، Member)
+- إنشاء أدوار مخصصة مصممة لصلاحيات محددة
+- تعيين الأدوار في أي وقت عبر لوحة الإعدادات
+
+يمكنك تهيئة المستخدمين والأدوار في Settings → Roles.
+
+
+
+
+## المستخدمون والأدوار
+
+يُعيَّن لكل عضو في مساحة عمل CrewAI دور يحدد صلاحيات الوصول عبر الميزات المختلفة.
+
+يمكنك:
+
+- استخدام الأدوار المحددة مسبقاً (Owner، Member)
+- إنشاء أدوار مخصصة مصممة لصلاحيات محددة
+- تعيين الأدوار في أي وقت عبر لوحة الإعدادات
+
+يمكنك تهيئة المستخدمين والأدوار في Settings → Roles.
+
+ +
+
+### أنواع صلاحيات النشر
+
+عند منح وصول على مستوى الكيان لأتمتة محددة، يمكنك تعيين أنواع الصلاحيات التالية:
+
+| الصلاحية | ما تسمح به |
+| :------------------- | :-------------------------------------------------- |
+| `run` | تنفيذ الأتمتة واستخدام API الخاص بها |
+| `traces` | عرض تتبعات التنفيذ والسجلات |
+| `manage_settings` | تعديل، إعادة نشر، استرجاع، أو حذف الأتمتة |
+| `human_in_the_loop` | الرد على طلبات الإنسان في الحلقة (HITL) |
+| `full_access` | جميع ما سبق |
+
+### RBAC على مستوى الكيان لموارد أخرى
+
+عند تفعيل RBAC على مستوى الكيان، يمكن أيضاً التحكم في الوصول لهذه الموارد حسب المستخدم أو الدور:
+
+| المورد | يتم التحكم فيه بواسطة | الوصف |
+| :-------------------- | :--------------------------------- | :------------------------------------------------------------- |
+| متغيرات البيئة | علامة ميزة RBAC الكيان | تقييد أي الأدوار/المستخدمين يمكنهم عرض أو إدارة متغيرات بيئة محددة |
+| اتصالات LLM | علامة ميزة RBAC الكيان | تقييد الوصول لتهيئات مزودي LLM محددة |
+| مستودعات Git | إعداد RBAC لمستودعات Git بالمؤسسة | تقييد أي الأدوار/المستخدمين يمكنهم الوصول لمستودعات متصلة محددة |
+
+---
+
+## أنماط الأدوار الشائعة
+
+بينما يأتي CrewAI بدوري Owner وMember، تستفيد معظم الفرق من إنشاء أدوار مخصصة. إليك الأنماط الشائعة:
+
+### دور المطور
+
+دور لأعضاء الفريق الذين يبنون وينشرون الأتمتات لكن لا يديرون إعدادات المؤسسة.
+
+| الميزة | الصلاحية |
+| :------------------------ | :---------- |
+| `usage_dashboards` | Read |
+| `crews_dashboards` | Manage |
+| `invitations` | Read |
+| `training_ui` | Read |
+| `tools` | Manage |
+| `agents` | Manage |
+| `environment_variables` | Manage |
+| `llm_connections` | Manage |
+| `default_settings` | No access |
+| `organization_settings` | No access |
+| `studio_projects` | Manage |
+
+### دور المشاهد / أصحاب المصلحة
+
+دور للمعنيين غير التقنيين الذين يحتاجون لمراقبة الأتمتات وعرض النتائج.
+
+| الميزة | الصلاحية |
+| :------------------------ | :---------- |
+| `usage_dashboards` | Read |
+| `crews_dashboards` | Read |
+| `invitations` | No access |
+| `training_ui` | Read |
+| `tools` | Read |
+| `agents` | Read |
+| `environment_variables` | No access |
+| `llm_connections` | No access |
+| `default_settings` | No access |
+| `organization_settings` | No access |
+| `studio_projects` | No access |
+
+### دور مسؤول العمليات / المنصة
+
+دور لمشغلي المنصة الذين يديرون إعدادات البنية التحتية لكن قد لا يبنون الوكلاء.
+
+| الميزة | الصلاحية |
+| :------------------------ | :---------- |
+| `usage_dashboards` | Manage |
+| `crews_dashboards` | Manage |
+| `invitations` | Manage |
+| `training_ui` | Read |
+| `tools` | Read |
+| `agents` | Read |
+| `environment_variables` | Manage |
+| `llm_connections` | Manage |
+| `default_settings` | Manage |
+| `organization_settings` | Read |
+| `studio_projects` | No access |
+
+---
+
+
+
+
+### أنواع صلاحيات النشر
+
+عند منح وصول على مستوى الكيان لأتمتة محددة، يمكنك تعيين أنواع الصلاحيات التالية:
+
+| الصلاحية | ما تسمح به |
+| :------------------- | :-------------------------------------------------- |
+| `run` | تنفيذ الأتمتة واستخدام API الخاص بها |
+| `traces` | عرض تتبعات التنفيذ والسجلات |
+| `manage_settings` | تعديل، إعادة نشر، استرجاع، أو حذف الأتمتة |
+| `human_in_the_loop` | الرد على طلبات الإنسان في الحلقة (HITL) |
+| `full_access` | جميع ما سبق |
+
+### RBAC على مستوى الكيان لموارد أخرى
+
+عند تفعيل RBAC على مستوى الكيان، يمكن أيضاً التحكم في الوصول لهذه الموارد حسب المستخدم أو الدور:
+
+| المورد | يتم التحكم فيه بواسطة | الوصف |
+| :-------------------- | :--------------------------------- | :------------------------------------------------------------- |
+| متغيرات البيئة | علامة ميزة RBAC الكيان | تقييد أي الأدوار/المستخدمين يمكنهم عرض أو إدارة متغيرات بيئة محددة |
+| اتصالات LLM | علامة ميزة RBAC الكيان | تقييد الوصول لتهيئات مزودي LLM محددة |
+| مستودعات Git | إعداد RBAC لمستودعات Git بالمؤسسة | تقييد أي الأدوار/المستخدمين يمكنهم الوصول لمستودعات متصلة محددة |
+
+---
+
+## أنماط الأدوار الشائعة
+
+بينما يأتي CrewAI بدوري Owner وMember، تستفيد معظم الفرق من إنشاء أدوار مخصصة. إليك الأنماط الشائعة:
+
+### دور المطور
+
+دور لأعضاء الفريق الذين يبنون وينشرون الأتمتات لكن لا يديرون إعدادات المؤسسة.
+
+| الميزة | الصلاحية |
+| :------------------------ | :---------- |
+| `usage_dashboards` | Read |
+| `crews_dashboards` | Manage |
+| `invitations` | Read |
+| `training_ui` | Read |
+| `tools` | Manage |
+| `agents` | Manage |
+| `environment_variables` | Manage |
+| `llm_connections` | Manage |
+| `default_settings` | No access |
+| `organization_settings` | No access |
+| `studio_projects` | Manage |
+
+### دور المشاهد / أصحاب المصلحة
+
+دور للمعنيين غير التقنيين الذين يحتاجون لمراقبة الأتمتات وعرض النتائج.
+
+| الميزة | الصلاحية |
+| :------------------------ | :---------- |
+| `usage_dashboards` | Read |
+| `crews_dashboards` | Read |
+| `invitations` | No access |
+| `training_ui` | Read |
+| `tools` | Read |
+| `agents` | Read |
+| `environment_variables` | No access |
+| `llm_connections` | No access |
+| `default_settings` | No access |
+| `organization_settings` | No access |
+| `studio_projects` | No access |
+
+### دور مسؤول العمليات / المنصة
+
+دور لمشغلي المنصة الذين يديرون إعدادات البنية التحتية لكن قد لا يبنون الوكلاء.
+
+| الميزة | الصلاحية |
+| :------------------------ | :---------- |
+| `usage_dashboards` | Manage |
+| `crews_dashboards` | Manage |
+| `invitations` | Manage |
+| `training_ui` | Read |
+| `tools` | Read |
+| `agents` | Read |
+| `environment_variables` | Manage |
+| `llm_connections` | Manage |
+| `default_settings` | Manage |
+| `organization_settings` | Read |
+| `studio_projects` | No access |
+
+---
+
+ +
+
+يعرض هذا العرض جميع تكاملات المشغلات المتاحة لعملية النشر، مع حالة الاتصال الحالية.
+
+### تفعيل وتعطيل المشغلات
+
+يمكن تفعيل أو تعطيل كل مشغل بسهولة باستخدام مفتاح التبديل:
+
+
+
+
+
+يعرض هذا العرض جميع تكاملات المشغلات المتاحة لعملية النشر، مع حالة الاتصال الحالية.
+
+### تفعيل وتعطيل المشغلات
+
+يمكن تفعيل أو تعطيل كل مشغل بسهولة باستخدام مفتاح التبديل:
+
+
+  +
+
+- **مُفعّل (تبديل أزرق)**: المشغل نشط وسينفذ عملية النشر تلقائياً عند حدوث الأحداث المحددة
+- **مُعطّل (تبديل رمادي)**: المشغل غير نشط ولن يستجيب للأحداث
+
+انقر ببساطة على التبديل لتغيير حالة المشغل. تسري التغييرات فوراً.
+
+### مراقبة عمليات تنفيذ المشغلات
+
+تتبع أداء وسجل عمليات التنفيذ المُشغّلة:
+
+
+
+
+
+- **مُفعّل (تبديل أزرق)**: المشغل نشط وسينفذ عملية النشر تلقائياً عند حدوث الأحداث المحددة
+- **مُعطّل (تبديل رمادي)**: المشغل غير نشط ولن يستجيب للأحداث
+
+انقر ببساطة على التبديل لتغيير حالة المشغل. تسري التغييرات فوراً.
+
+### مراقبة عمليات تنفيذ المشغلات
+
+تتبع أداء وسجل عمليات التنفيذ المُشغّلة:
+
+
+  +
+
+## بناء أتمتات مدفوعة بالمشغلات
+
+قبل بناء أتمتتك، من المفيد فهم هيكل حمولات المشغلات التي ستتلقاها طواقمك وتدفقاتك.
+
+### قائمة فحص إعداد المشغل
+
+قبل ربط مشغل بالإنتاج، تأكد من:
+
+- ربط التكامل تحت **Tools & Integrations** وإكمال خطوات OAuth أو مفتاح API
+- تفعيل تبديل المشغل في عملية النشر التي يجب أن تستجيب للأحداث
+- توفير متغيرات البيئة المطلوبة (رموز API، معرّفات المستأجر، الأسرار المشتركة)
+- إنشاء أو تحديث المهام التي يمكنها تحليل الحمولة الواردة في أول مهمة طاقم أو خطوة تدفق
+- تحديد ما إذا كنت ستمرر سياق المشغل تلقائياً باستخدام `allow_crewai_trigger_context`
+- إعداد المراقبة — سجلات webhook وسجل تنفيذ CrewAI والتنبيهات الخارجية الاختيارية
+
+### اختبار المشغلات محلياً باستخدام CLI
+
+يوفر CrewAI CLI أوامر قوية لمساعدتك في تطوير واختبار الأتمتات المدفوعة بالمشغلات دون النشر في الإنتاج.
+
+#### عرض المشغلات المتاحة
+
+اعرض جميع المشغلات المتاحة للتكاملات المتصلة:
+
+```bash
+crewai triggers list
+```
+
+يعرض هذا الأمر جميع المشغلات المتاحة بناءً على تكاملاتك المتصلة، ويظهر:
+
+- اسم التكامل وحالة الاتصال
+- أنواع المشغلات المتاحة
+- أسماء وأوصاف المشغلات
+
+#### محاكاة تنفيذ المشغل
+
+اختبر طاقمك بحمولات مشغل واقعية قبل النشر:
+
+```bash
+crewai triggers run
+
+
+## بناء أتمتات مدفوعة بالمشغلات
+
+قبل بناء أتمتتك، من المفيد فهم هيكل حمولات المشغلات التي ستتلقاها طواقمك وتدفقاتك.
+
+### قائمة فحص إعداد المشغل
+
+قبل ربط مشغل بالإنتاج، تأكد من:
+
+- ربط التكامل تحت **Tools & Integrations** وإكمال خطوات OAuth أو مفتاح API
+- تفعيل تبديل المشغل في عملية النشر التي يجب أن تستجيب للأحداث
+- توفير متغيرات البيئة المطلوبة (رموز API، معرّفات المستأجر، الأسرار المشتركة)
+- إنشاء أو تحديث المهام التي يمكنها تحليل الحمولة الواردة في أول مهمة طاقم أو خطوة تدفق
+- تحديد ما إذا كنت ستمرر سياق المشغل تلقائياً باستخدام `allow_crewai_trigger_context`
+- إعداد المراقبة — سجلات webhook وسجل تنفيذ CrewAI والتنبيهات الخارجية الاختيارية
+
+### اختبار المشغلات محلياً باستخدام CLI
+
+يوفر CrewAI CLI أوامر قوية لمساعدتك في تطوير واختبار الأتمتات المدفوعة بالمشغلات دون النشر في الإنتاج.
+
+#### عرض المشغلات المتاحة
+
+اعرض جميع المشغلات المتاحة للتكاملات المتصلة:
+
+```bash
+crewai triggers list
+```
+
+يعرض هذا الأمر جميع المشغلات المتاحة بناءً على تكاملاتك المتصلة، ويظهر:
+
+- اسم التكامل وحالة الاتصال
+- أنواع المشغلات المتاحة
+- أسماء وأوصاف المشغلات
+
+#### محاكاة تنفيذ المشغل
+
+اختبر طاقمك بحمولات مشغل واقعية قبل النشر:
+
+```bash
+crewai triggers run  +
+
+
+  +
+
+| الحقل | مطلوب | الوصف |
+|-------|-------|-------|
+| **Header Name** | نعم | اسم رأس HTTP الذي يحمل الرمز (مثل `X-API-Key`، `Authorization`). |
+| **Value** | نعم | مفتاح API أو رمز الحامل الخاص بك. |
+| **Add to** | لا | أين يتم إرفاق بيانات الاعتماد — **Header** (افتراضي) أو **Query parameter**. |
+
+
+
+
+| الحقل | مطلوب | الوصف |
+|-------|-------|-------|
+| **Header Name** | نعم | اسم رأس HTTP الذي يحمل الرمز (مثل `X-API-Key`، `Authorization`). |
+| **Value** | نعم | مفتاح API أو رمز الحامل الخاص بك. |
+| **Add to** | لا | أين يتم إرفاق بيانات الاعتماد — **Header** (افتراضي) أو **Query parameter**. |
+
+ +
+
+| الحقل | مطلوب | الوصف |
+|-------|-------|-------|
+| **Redirect URI** | — | مُعبأ مسبقاً وللقراءة فقط. انسخ هذا الرابط وسجّله كرابط إعادة توجيه مصرّح به في مزود OAuth. |
+| **Authorization Endpoint** | نعم | الرابط الذي يُوجَّه إليه المستخدمون لتفويض الوصول (مثل `https://auth.example.com/oauth/authorize`). |
+| **Token Endpoint** | نعم | الرابط المستخدم لتبادل رمز التفويض برمز وصول (مثل `https://auth.example.com/oauth/token`). |
+| **Client ID** | نعم | معرّف عميل OAuth الصادر من مزودك. |
+| **Client Secret** | لا | سر عميل OAuth. غير مطلوب للعملاء العامين باستخدام PKCE. |
+| **Scopes** | لا | قائمة نطاقات مفصولة بمسافات للطلب (مثل `read write`). |
+| **Token Auth Method** | لا | كيفية إرسال بيانات اعتماد العميل عند تبادل الرموز — **Standard (POST body)** أو **Basic Auth (header)**. الافتراضي هو Standard. |
+| **PKCE Supported** | لا | فعّل إذا كان مزود OAuth يدعم Proof Key for Code Exchange. موصى به لتحسين الأمان. |
+
+
+
+
+## مثال: معالجة الرسائل الجديدة
+
+عند وصول رسالة بريد إلكتروني جديدة، سيرسل مشغل Gmail الحمولة إلى طاقمك أو تدفقك. فيما يلي مثال على طاقم يحلل ويعالج حمولة المشغل.
+
+```python
+@CrewBase
+class GmailProcessingCrew:
+ @agent
+ def parser(self) -> Agent:
+ return Agent(
+ config=self.agents_config['parser'],
+ )
+
+ @task
+ def parse_gmail_payload(self) -> Task:
+ return Task(
+ config=self.tasks_config['parse_gmail_payload'],
+ agent=self.parser(),
+ )
+
+ @task
+ def act_on_email(self) -> Task:
+ return Task(
+ config=self.tasks_config['act_on_email'],
+ agent=self.parser(),
+ )
+```
+
+ستكون حمولة Gmail متاحة عبر آليات السياق القياسية.
+
+### الاختبار المحلي
+
+اختبر تكامل مشغل Gmail محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Gmail بحمولة واقعية
+crewai triggers run gmail/new_email_received
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Gmail كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## استكشاف الأخطاء وإصلاحها
+
+- تأكد من ربط Gmail في Tools & Integrations
+- تحقق من تفعيل مشغل Gmail في علامة تبويب Triggers
+- اختبر محلياً بـ `crewai triggers run gmail/new_email_received` لرؤية هيكل الحمولة بالضبط
+- تحقق من سجلات التنفيذ وتأكد من تمرير الحمولة كـ `crewai_trigger_payload`
+- تذكر: استخدم `crewai triggers run` (وليس `crewai run`) لمحاكاة تنفيذ المشغل
diff --git a/docs/v1.15.0/ar/enterprise/guides/google-calendar-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/google-calendar-trigger.mdx
new file mode 100644
index 0000000000..542df5b18c
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/google-calendar-trigger.mdx
@@ -0,0 +1,83 @@
+---
+title: "مشغل Google Calendar"
+description: "تشغيل الطواقم عند إنشاء أو تحديث أو إلغاء أحداث Google Calendar"
+icon: "calendar"
+mode: "wide"
+---
+
+## نظرة عامة
+
+استخدم مشغل Google Calendar لإطلاق الأتمتات كلما تغيرت أحداث التقويم. تشمل حالات الاستخدام الشائعة إحاطة الفريق قبل اجتماع، وإخطار أصحاب المصلحة عند إلغاء حدث هام، أو تلخيص الجداول اليومية.
+
+
+
+
+| الحقل | مطلوب | الوصف |
+|-------|-------|-------|
+| **Redirect URI** | — | مُعبأ مسبقاً وللقراءة فقط. انسخ هذا الرابط وسجّله كرابط إعادة توجيه مصرّح به في مزود OAuth. |
+| **Authorization Endpoint** | نعم | الرابط الذي يُوجَّه إليه المستخدمون لتفويض الوصول (مثل `https://auth.example.com/oauth/authorize`). |
+| **Token Endpoint** | نعم | الرابط المستخدم لتبادل رمز التفويض برمز وصول (مثل `https://auth.example.com/oauth/token`). |
+| **Client ID** | نعم | معرّف عميل OAuth الصادر من مزودك. |
+| **Client Secret** | لا | سر عميل OAuth. غير مطلوب للعملاء العامين باستخدام PKCE. |
+| **Scopes** | لا | قائمة نطاقات مفصولة بمسافات للطلب (مثل `read write`). |
+| **Token Auth Method** | لا | كيفية إرسال بيانات اعتماد العميل عند تبادل الرموز — **Standard (POST body)** أو **Basic Auth (header)**. الافتراضي هو Standard. |
+| **PKCE Supported** | لا | فعّل إذا كان مزود OAuth يدعم Proof Key for Code Exchange. موصى به لتحسين الأمان. |
+
+
+
+
+## مثال: معالجة الرسائل الجديدة
+
+عند وصول رسالة بريد إلكتروني جديدة، سيرسل مشغل Gmail الحمولة إلى طاقمك أو تدفقك. فيما يلي مثال على طاقم يحلل ويعالج حمولة المشغل.
+
+```python
+@CrewBase
+class GmailProcessingCrew:
+ @agent
+ def parser(self) -> Agent:
+ return Agent(
+ config=self.agents_config['parser'],
+ )
+
+ @task
+ def parse_gmail_payload(self) -> Task:
+ return Task(
+ config=self.tasks_config['parse_gmail_payload'],
+ agent=self.parser(),
+ )
+
+ @task
+ def act_on_email(self) -> Task:
+ return Task(
+ config=self.tasks_config['act_on_email'],
+ agent=self.parser(),
+ )
+```
+
+ستكون حمولة Gmail متاحة عبر آليات السياق القياسية.
+
+### الاختبار المحلي
+
+اختبر تكامل مشغل Gmail محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Gmail بحمولة واقعية
+crewai triggers run gmail/new_email_received
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Gmail كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## استكشاف الأخطاء وإصلاحها
+
+- تأكد من ربط Gmail في Tools & Integrations
+- تحقق من تفعيل مشغل Gmail في علامة تبويب Triggers
+- اختبر محلياً بـ `crewai triggers run gmail/new_email_received` لرؤية هيكل الحمولة بالضبط
+- تحقق من سجلات التنفيذ وتأكد من تمرير الحمولة كـ `crewai_trigger_payload`
+- تذكر: استخدم `crewai triggers run` (وليس `crewai run`) لمحاكاة تنفيذ المشغل
diff --git a/docs/v1.15.0/ar/enterprise/guides/google-calendar-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/google-calendar-trigger.mdx
new file mode 100644
index 0000000000..542df5b18c
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/google-calendar-trigger.mdx
@@ -0,0 +1,83 @@
+---
+title: "مشغل Google Calendar"
+description: "تشغيل الطواقم عند إنشاء أو تحديث أو إلغاء أحداث Google Calendar"
+icon: "calendar"
+mode: "wide"
+---
+
+## نظرة عامة
+
+استخدم مشغل Google Calendar لإطلاق الأتمتات كلما تغيرت أحداث التقويم. تشمل حالات الاستخدام الشائعة إحاطة الفريق قبل اجتماع، وإخطار أصحاب المصلحة عند إلغاء حدث هام، أو تلخيص الجداول اليومية.
+
+ +
+
+## مثال: تلخيص تفاصيل الاجتماع
+
+المقتطف أدناه يعكس مثال `calendar-event-crew.py` في مستودع المشغلات. يحلل الحمولة، ويحلل الحاضرين والتوقيت، وينتج ملخصاً للاجتماع للأدوات اللاحقة.
+
+```python
+from calendar_event_crew import GoogleCalendarEventTrigger
+
+crew = GoogleCalendarEventTrigger().crew()
+result = crew.kickoff({
+ "crewai_trigger_payload": calendar_payload,
+})
+print(result.raw)
+```
+
+استخدم `crewai_trigger_payload` تماماً كما يتم تسليمه من المشغل حتى يتمكن الطاقم من استخراج الحقول المناسبة.
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل Google Calendar محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Google Calendar بحمولة واقعية
+crewai triggers run google_calendar/event_changed
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Calendar كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## استكشاف الأخطاء وإصلاحها
+
+- تأكد من ربط حساب Google الصحيح وتفعيل المشغل
+- اختبر محلياً بـ `crewai triggers run google_calendar/event_changed` لرؤية هيكل الحمولة بالضبط
+- تأكد من أن سير عملك يتعامل مع أحداث اليوم الكامل (الحمولات تستخدم `start.date` و`end.date` بدلاً من الطوابع الزمنية)
+- تحقق من سجلات التنفيذ إذا كانت التذكيرات أو مصفوفات الحاضرين مفقودة — قد تحد صلاحيات التقويم من الحقول في الحمولة
+- تذكر: استخدم `crewai triggers run` (وليس `crewai run`) لمحاكاة تنفيذ المشغل
diff --git a/docs/v1.15.0/ar/enterprise/guides/google-drive-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/google-drive-trigger.mdx
new file mode 100644
index 0000000000..0f4c05ec45
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/google-drive-trigger.mdx
@@ -0,0 +1,80 @@
+---
+title: "مشغل Google Drive"
+description: "الاستجابة لأحداث ملفات Google Drive بطواقم آلية"
+icon: "folder"
+mode: "wide"
+---
+
+## نظرة عامة
+
+شغّل أتمتاتك عند إنشاء أو تحديث أو حذف ملفات في Google Drive. تشمل سير العمل النموذجية تلخيص المحتوى المُحمّل حديثاً، وتطبيق سياسات المشاركة، أو إخطار المالكين عند تغيير ملفات هامة.
+
+
+
+
+## مثال: تلخيص تفاصيل الاجتماع
+
+المقتطف أدناه يعكس مثال `calendar-event-crew.py` في مستودع المشغلات. يحلل الحمولة، ويحلل الحاضرين والتوقيت، وينتج ملخصاً للاجتماع للأدوات اللاحقة.
+
+```python
+from calendar_event_crew import GoogleCalendarEventTrigger
+
+crew = GoogleCalendarEventTrigger().crew()
+result = crew.kickoff({
+ "crewai_trigger_payload": calendar_payload,
+})
+print(result.raw)
+```
+
+استخدم `crewai_trigger_payload` تماماً كما يتم تسليمه من المشغل حتى يتمكن الطاقم من استخراج الحقول المناسبة.
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل Google Calendar محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Google Calendar بحمولة واقعية
+crewai triggers run google_calendar/event_changed
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Calendar كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## استكشاف الأخطاء وإصلاحها
+
+- تأكد من ربط حساب Google الصحيح وتفعيل المشغل
+- اختبر محلياً بـ `crewai triggers run google_calendar/event_changed` لرؤية هيكل الحمولة بالضبط
+- تأكد من أن سير عملك يتعامل مع أحداث اليوم الكامل (الحمولات تستخدم `start.date` و`end.date` بدلاً من الطوابع الزمنية)
+- تحقق من سجلات التنفيذ إذا كانت التذكيرات أو مصفوفات الحاضرين مفقودة — قد تحد صلاحيات التقويم من الحقول في الحمولة
+- تذكر: استخدم `crewai triggers run` (وليس `crewai run`) لمحاكاة تنفيذ المشغل
diff --git a/docs/v1.15.0/ar/enterprise/guides/google-drive-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/google-drive-trigger.mdx
new file mode 100644
index 0000000000..0f4c05ec45
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/google-drive-trigger.mdx
@@ -0,0 +1,80 @@
+---
+title: "مشغل Google Drive"
+description: "الاستجابة لأحداث ملفات Google Drive بطواقم آلية"
+icon: "folder"
+mode: "wide"
+---
+
+## نظرة عامة
+
+شغّل أتمتاتك عند إنشاء أو تحديث أو حذف ملفات في Google Drive. تشمل سير العمل النموذجية تلخيص المحتوى المُحمّل حديثاً، وتطبيق سياسات المشاركة، أو إخطار المالكين عند تغيير ملفات هامة.
+
+ +
+
+## مثال: تلخيص نشاط الملفات
+
+تحلل طواقم Drive النموذجية الحمولة لاستخراج بيانات الملف الوصفية وتقييم الصلاحيات ونشر ملخص.
+
+```python
+from drive_file_crew import GoogleDriveFileTrigger
+
+crew = GoogleDriveFileTrigger().crew()
+crew.kickoff({
+ "crewai_trigger_payload": drive_payload,
+})
+```
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل Google Drive محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Google Drive بحمولة واقعية
+crewai triggers run google_drive/file_changed
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Drive كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## استكشاف الأخطاء وإصلاحها
+
+- تحقق من ربط Google Drive وتفعيل مفتاح التبديل للمشغل
+- اختبر محلياً بـ `crewai triggers run google_drive/file_changed` لرؤية هيكل الحمولة بالضبط
+- إذا كانت الحمولة تفتقد بيانات الصلاحيات، تأكد من أن الحساب المتصل لديه صلاحية الوصول إلى الملف أو المجلد
+- يرسل المشغل معرّفات الملفات فقط؛ استخدم Drive API إذا كنت تحتاج جلب المحتوى الثنائي أثناء تشغيل الطاقم
+- تذكر: استخدم `crewai triggers run` (وليس `crewai run`) لمحاكاة تنفيذ المشغل
diff --git a/docs/v1.15.0/ar/enterprise/guides/hubspot-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/hubspot-trigger.mdx
new file mode 100644
index 0000000000..20c31aef60
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/hubspot-trigger.mdx
@@ -0,0 +1,61 @@
+---
+title: "مشغل HubSpot"
+description: "تشغيل طواقم CrewAI مباشرة من سير عمل HubSpot"
+icon: "hubspot"
+mode: "wide"
+---
+
+يقدم هذا الدليل عملية خطوة بخطوة لإعداد مشغلات HubSpot لـ CrewAI AMP، مما يتيح لك بدء الطواقم مباشرة من سير عمل HubSpot.
+
+## المتطلبات المسبقة
+
+- حساب CrewAI AMP
+- حساب HubSpot مع ميزة [HubSpot Workflows](https://knowledge.hubspot.com/workflows/create-workflows)
+
+## خطوات الإعداد
+
+
+
+
+## مثال: تلخيص نشاط الملفات
+
+تحلل طواقم Drive النموذجية الحمولة لاستخراج بيانات الملف الوصفية وتقييم الصلاحيات ونشر ملخص.
+
+```python
+from drive_file_crew import GoogleDriveFileTrigger
+
+crew = GoogleDriveFileTrigger().crew()
+crew.kickoff({
+ "crewai_trigger_payload": drive_payload,
+})
+```
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل Google Drive محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Google Drive بحمولة واقعية
+crewai triggers run google_drive/file_changed
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Drive كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## استكشاف الأخطاء وإصلاحها
+
+- تحقق من ربط Google Drive وتفعيل مفتاح التبديل للمشغل
+- اختبر محلياً بـ `crewai triggers run google_drive/file_changed` لرؤية هيكل الحمولة بالضبط
+- إذا كانت الحمولة تفتقد بيانات الصلاحيات، تأكد من أن الحساب المتصل لديه صلاحية الوصول إلى الملف أو المجلد
+- يرسل المشغل معرّفات الملفات فقط؛ استخدم Drive API إذا كنت تحتاج جلب المحتوى الثنائي أثناء تشغيل الطاقم
+- تذكر: استخدم `crewai triggers run` (وليس `crewai run`) لمحاكاة تنفيذ المشغل
diff --git a/docs/v1.15.0/ar/enterprise/guides/hubspot-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/hubspot-trigger.mdx
new file mode 100644
index 0000000000..20c31aef60
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/hubspot-trigger.mdx
@@ -0,0 +1,61 @@
+---
+title: "مشغل HubSpot"
+description: "تشغيل طواقم CrewAI مباشرة من سير عمل HubSpot"
+icon: "hubspot"
+mode: "wide"
+---
+
+يقدم هذا الدليل عملية خطوة بخطوة لإعداد مشغلات HubSpot لـ CrewAI AMP، مما يتيح لك بدء الطواقم مباشرة من سير عمل HubSpot.
+
+## المتطلبات المسبقة
+
+- حساب CrewAI AMP
+- حساب HubSpot مع ميزة [HubSpot Workflows](https://knowledge.hubspot.com/workflows/create-workflows)
+
+## خطوات الإعداد
+
+ +
+
+
+  +
+ - هيّئ أي إجراءات إضافية حسب الحاجة - راجع خطوات
+ سير عملك للتأكد من إعداد كل شيء بشكل صحيح - فعّل سير العمل
+
+
+
+ - هيّئ أي إجراءات إضافية حسب الحاجة - راجع خطوات
+ سير عملك للتأكد من إعداد كل شيء بشكل صحيح - فعّل سير العمل
+
+  +
+
+
+  +
+
+
+  +
+
+
+  +
+
+
+
+
+  +
+
+## مثال: تلخيص سلسلة محادثة جديدة
+
+```python
+from teams_chat_created_crew import MicrosoftTeamsChatTrigger
+
+crew = MicrosoftTeamsChatTrigger().crew()
+result = crew.kickoff({
+ "crewai_trigger_payload": teams_payload,
+})
+print(result.raw)
+```
+
+يحلل الطاقم بيانات المحادثة الوصفية (الموضوع، وقت الإنشاء، قائمة الأعضاء) وينشئ خطة عمل للفريق المستقبل.
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل Microsoft Teams محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Microsoft Teams بحمولة واقعية
+crewai triggers run microsoft_teams/teams_message_created
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Teams كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## مثال: تلخيص سلسلة محادثة جديدة
+
+```python
+from teams_chat_created_crew import MicrosoftTeamsChatTrigger
+
+crew = MicrosoftTeamsChatTrigger().crew()
+result = crew.kickoff({
+ "crewai_trigger_payload": teams_payload,
+})
+print(result.raw)
+```
+
+يحلل الطاقم بيانات المحادثة الوصفية (الموضوع، وقت الإنشاء، قائمة الأعضاء) وينشئ خطة عمل للفريق المستقبل.
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل Microsoft Teams محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Microsoft Teams بحمولة واقعية
+crewai triggers run microsoft_teams/teams_message_created
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Teams كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+ +
+
+## مثال: تدقيق صلاحيات الملفات
+
+```python
+from onedrive_file_crew import OneDriveFileTrigger
+
+crew = OneDriveFileTrigger().crew()
+crew.kickoff({
+ "crewai_trigger_payload": onedrive_payload,
+})
+```
+
+يفحص الطاقم بيانات الملف الوصفية ونشاط المستخدم وتغييرات الصلاحيات لإنتاج ملخص متوافق مع متطلبات الامتثال.
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل OneDrive محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل OneDrive بحمولة واقعية
+crewai triggers run microsoft_onedrive/file_changed
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة OneDrive كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## مثال: تدقيق صلاحيات الملفات
+
+```python
+from onedrive_file_crew import OneDriveFileTrigger
+
+crew = OneDriveFileTrigger().crew()
+crew.kickoff({
+ "crewai_trigger_payload": onedrive_payload,
+})
+```
+
+يفحص الطاقم بيانات الملف الوصفية ونشاط المستخدم وتغييرات الصلاحيات لإنتاج ملخص متوافق مع متطلبات الامتثال.
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل OneDrive محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل OneDrive بحمولة واقعية
+crewai triggers run microsoft_onedrive/file_changed
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة OneDrive كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+ +
+
+## مثال: تلخيص رسالة بريد إلكتروني جديدة
+
+```python
+from outlook_message_crew import OutlookMessageTrigger
+
+crew = OutlookMessageTrigger().crew()
+crew.kickoff({
+ "crewai_trigger_payload": outlook_payload,
+})
+```
+
+يستخرج الطاقم تفاصيل المرسل والموضوع ومعاينة النص والمرفقات قبل إنشاء استجابة منظمة.
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل Outlook محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Outlook بحمولة واقعية
+crewai triggers run microsoft_outlook/email_received
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Outlook كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+
+
+
+## مثال: تلخيص رسالة بريد إلكتروني جديدة
+
+```python
+from outlook_message_crew import OutlookMessageTrigger
+
+crew = OutlookMessageTrigger().crew()
+crew.kickoff({
+ "crewai_trigger_payload": outlook_payload,
+})
+```
+
+يستخرج الطاقم تفاصيل المرسل والموضوع ومعاينة النص والمرفقات قبل إنشاء استجابة منظمة.
+
+## الاختبار المحلي
+
+اختبر تكامل مشغل Outlook محلياً باستخدام CrewAI CLI:
+
+```bash
+# عرض جميع المشغلات المتاحة
+crewai triggers list
+
+# محاكاة مشغل Outlook بحمولة واقعية
+crewai triggers run microsoft_outlook/email_received
+```
+
+سينفذ أمر `crewai triggers run` طاقمك بحمولة Outlook كاملة، مما يتيح لك اختبار منطق التحليل قبل النشر.
+
+ +
+
+
+
+
+ );
+ }
+
+ export default App;
+ ```
+ - استبدل `YOUR_API_BASE_URL` و`YOUR_BEARER_TOKEN` بالقيم الفعلية لـ API.
+  +
+
+
+
+
+  +
+
+## الخطوات التالية
+
+- خصّص تنسيق المكون ليتوافق مع تصميم تطبيقك
+- أضف خصائص إضافية للتهيئة
+- ادمج مع إدارة حالة تطبيقك
+- أضف معالجة الأخطاء وحالات التحميل
diff --git a/docs/v1.15.0/ar/enterprise/guides/salesforce-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/salesforce-trigger.mdx
new file mode 100644
index 0000000000..8cd16c0266
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/salesforce-trigger.mdx
@@ -0,0 +1,50 @@
+---
+title: "مشغل Salesforce"
+description: "تشغيل طواقم CrewAI من سير عمل Salesforce لأتمتة CRM"
+icon: "salesforce"
+mode: "wide"
+---
+
+يمكن تشغيل CrewAI AMP من Salesforce لأتمتة سير عمل إدارة علاقات العملاء وتعزيز عمليات المبيعات.
+
+## نظرة عامة
+
+Salesforce هي منصة رائدة لإدارة علاقات العملاء (CRM) تساعد الشركات على تبسيط عمليات المبيعات والخدمة والتسويق. من خلال إعداد مشغلات CrewAI من Salesforce، يمكنك:
+
+- أتمتة تسجيل وتأهيل العملاء المحتملين
+- إنشاء مواد مبيعات مخصصة
+- تعزيز خدمة العملاء بردود مدعومة بالذكاء الاصطناعي
+- تبسيط تحليل البيانات وإعداد التقارير
+
+## عرض توضيحي
+
+
+
+## البدء
+
+لإعداد مشغلات Salesforce:
+
+1. **تواصل مع الدعم**: تواصل مع دعم CrewAI AMP للمساعدة في إعداد مشغل Salesforce
+2. **مراجعة المتطلبات**: تأكد من أن لديك صلاحيات Salesforce اللازمة والوصول إلى API
+3. **تهيئة الاتصال**: اعمل مع فريق الدعم لإنشاء الاتصال بين CrewAI ومثيل Salesforce الخاص بك
+4. **اختبار المشغلات**: تحقق من عمل المشغلات بشكل صحيح مع حالات الاستخدام المحددة
+
+## حالات الاستخدام
+
+سيناريوهات Salesforce + CrewAI الشائعة تشمل:
+
+- **معالجة العملاء المحتملين**: تحليل وتسجيل العملاء المحتملين الوافدين تلقائياً
+- **إنشاء العروض**: إنشاء عروض مخصصة بناءً على بيانات الفرص
+- **رؤى العملاء**: إنشاء تقارير تحليلية من سجل تفاعلات العملاء
+- **أتمتة المتابعة**: إنشاء رسائل متابعة وتوصيات مخصصة
+
+## الخطوات التالية
+
+للحصول على تعليمات الإعداد المفصلة وخيارات التهيئة المتقدمة، يرجى التواصل مع دعم CrewAI AMP الذي يمكنه تقديم إرشادات مخصصة لبيئة Salesforce واحتياجات عملك المحددة.
diff --git a/docs/v1.15.0/ar/enterprise/guides/slack-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/slack-trigger.mdx
new file mode 100644
index 0000000000..28aed7b6eb
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/slack-trigger.mdx
@@ -0,0 +1,62 @@
+---
+title: "مشغل Slack"
+description: "تشغيل طواقم CrewAI مباشرة من Slack باستخدام أوامر الشرطة المائلة"
+icon: "slack"
+mode: "wide"
+---
+
+يشرح هذا الدليل كيفية بدء طاقم مباشرة من Slack باستخدام مشغلات CrewAI.
+
+## المتطلبات المسبقة
+
+- مشغل CrewAI لـ Slack مُثبّت ومتصل بمساحة عمل Slack
+- طاقم واحد على الأقل مُهيأ في CrewAI
+
+## خطوات الإعداد
+
+
+
+
+## الخطوات التالية
+
+- خصّص تنسيق المكون ليتوافق مع تصميم تطبيقك
+- أضف خصائص إضافية للتهيئة
+- ادمج مع إدارة حالة تطبيقك
+- أضف معالجة الأخطاء وحالات التحميل
diff --git a/docs/v1.15.0/ar/enterprise/guides/salesforce-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/salesforce-trigger.mdx
new file mode 100644
index 0000000000..8cd16c0266
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/salesforce-trigger.mdx
@@ -0,0 +1,50 @@
+---
+title: "مشغل Salesforce"
+description: "تشغيل طواقم CrewAI من سير عمل Salesforce لأتمتة CRM"
+icon: "salesforce"
+mode: "wide"
+---
+
+يمكن تشغيل CrewAI AMP من Salesforce لأتمتة سير عمل إدارة علاقات العملاء وتعزيز عمليات المبيعات.
+
+## نظرة عامة
+
+Salesforce هي منصة رائدة لإدارة علاقات العملاء (CRM) تساعد الشركات على تبسيط عمليات المبيعات والخدمة والتسويق. من خلال إعداد مشغلات CrewAI من Salesforce، يمكنك:
+
+- أتمتة تسجيل وتأهيل العملاء المحتملين
+- إنشاء مواد مبيعات مخصصة
+- تعزيز خدمة العملاء بردود مدعومة بالذكاء الاصطناعي
+- تبسيط تحليل البيانات وإعداد التقارير
+
+## عرض توضيحي
+
+
+
+## البدء
+
+لإعداد مشغلات Salesforce:
+
+1. **تواصل مع الدعم**: تواصل مع دعم CrewAI AMP للمساعدة في إعداد مشغل Salesforce
+2. **مراجعة المتطلبات**: تأكد من أن لديك صلاحيات Salesforce اللازمة والوصول إلى API
+3. **تهيئة الاتصال**: اعمل مع فريق الدعم لإنشاء الاتصال بين CrewAI ومثيل Salesforce الخاص بك
+4. **اختبار المشغلات**: تحقق من عمل المشغلات بشكل صحيح مع حالات الاستخدام المحددة
+
+## حالات الاستخدام
+
+سيناريوهات Salesforce + CrewAI الشائعة تشمل:
+
+- **معالجة العملاء المحتملين**: تحليل وتسجيل العملاء المحتملين الوافدين تلقائياً
+- **إنشاء العروض**: إنشاء عروض مخصصة بناءً على بيانات الفرص
+- **رؤى العملاء**: إنشاء تقارير تحليلية من سجل تفاعلات العملاء
+- **أتمتة المتابعة**: إنشاء رسائل متابعة وتوصيات مخصصة
+
+## الخطوات التالية
+
+للحصول على تعليمات الإعداد المفصلة وخيارات التهيئة المتقدمة، يرجى التواصل مع دعم CrewAI AMP الذي يمكنه تقديم إرشادات مخصصة لبيئة Salesforce واحتياجات عملك المحددة.
diff --git a/docs/v1.15.0/ar/enterprise/guides/slack-trigger.mdx b/docs/v1.15.0/ar/enterprise/guides/slack-trigger.mdx
new file mode 100644
index 0000000000..28aed7b6eb
--- /dev/null
+++ b/docs/v1.15.0/ar/enterprise/guides/slack-trigger.mdx
@@ -0,0 +1,62 @@
+---
+title: "مشغل Slack"
+description: "تشغيل طواقم CrewAI مباشرة من Slack باستخدام أوامر الشرطة المائلة"
+icon: "slack"
+mode: "wide"
+---
+
+يشرح هذا الدليل كيفية بدء طاقم مباشرة من Slack باستخدام مشغلات CrewAI.
+
+## المتطلبات المسبقة
+
+- مشغل CrewAI لـ Slack مُثبّت ومتصل بمساحة عمل Slack
+- طاقم واحد على الأقل مُهيأ في CrewAI
+
+## خطوات الإعداد
+
+ +
+
+ تحقق من أن Slack مدرج ومتصل.
+
+
+
+ تحقق من أن Slack مدرج ومتصل.
+  +
+ - اضغط Enter أو اختر خيار "**Kickoff crew**". سيظهر مربع حوار بعنوان "**Kickoff an AI Crew**".
+
+
+ - اضغط Enter أو اختر خيار "**Kickoff crew**". سيظهر مربع حوار بعنوان "**Kickoff an AI Crew**".
+  +
+ - إذا كان طاقمك يتطلب أي مدخلات، انقر على زر "**Add Inputs**" لتقديمها.
+
+
+ - إذا كان طاقمك يتطلب أي مدخلات، انقر على زر "**Add Inputs**" لتقديمها.
+  +
+ - سيبدأ الطاقم بالتنفيذ وسترى النتائج في قناة Slack.
+
+
+
+ - سيبدأ الطاقم بالتنفيذ وسترى النتائج في قناة Slack.
+
+  +
+
+
+  +
+
+
+  +
+
+
+
+
+
+
+  +
+ - انقر على زر `Add Role` لإضافة دور جديد. - أدخل
+ تفاصيل وصلاحيات الدور وانقر على زر `Create Role` لإنشاء
+ الدور.
+
+
+
+ - انقر على زر `Add Role` لإضافة دور جديد. - أدخل
+ تفاصيل وصلاحيات الدور وانقر على زر `Create Role` لإنشاء
+ الدور.
+
+  +
+
+
+  +
+ - بمجرد قبول العضو للدعوة، يمكنك إضافة دور
+ له. - عد إلى علامة تبويب `Roles` - انتقل إلى العضو الذي تريد إضافة
+ دور له وتحت عمود `Role`، انقر على القائمة المنسدلة - اختر الدور
+ الذي تريد إضافته للعضو - انقر على زر `Update` لحفظ الدور
+
+
+
+ - بمجرد قبول العضو للدعوة، يمكنك إضافة دور
+ له. - عد إلى علامة تبويب `Roles` - انتقل إلى العضو الذي تريد إضافة
+ دور له وتحت عمود `Role`، انقر على القائمة المنسدلة - اختر الدور
+ الذي تريد إضافته للعضو - انقر على زر `Update` لحفظ الدور
+
+  +
+
+
+  +
+
+
+  +
+
+ 3. أضف خطوة إجراء HTTP
+ - عيّن الإجراء إلى `Send HTTP request`
+ - استخدم `POST` كطريقة
+ - عيّن عنوان URL إلى نقطة نهاية بدء CrewAI AMP
+ - أضف الترويسات اللازمة (مثال: `Bearer Token`)
+
+
+
+
+ 3. أضف خطوة إجراء HTTP
+ - عيّن الإجراء إلى `Send HTTP request`
+ - استخدم `POST` كطريقة
+ - عيّن عنوان URL إلى نقطة نهاية بدء CrewAI AMP
+ - أضف الترويسات اللازمة (مثال: `Bearer Token`)
+
+  +
+
+ - في النص، ضمّن محتوى JSON كما تم تكوينه في الخطوة 2
+
+
+
+
+ - في النص، ضمّن محتوى JSON كما تم تكوينه في الخطوة 2
+
+  +
+
+ - سيبدأ الطاقم بعد ذلك في الوقت المحدد مسبقًا.
+
+
+
+ - سيبدأ الطاقم بعد ذلك في الوقت المحدد مسبقًا.
+  +
+
+ 2. أضف خطوة webhook كمشغل:
+ - اختر `Catch Webhook` كنوع المشغل
+ - سيولّد هذا عنوان URL فريدًا سيستقبل طلبات HTTP ويشغل تدفقك
+
+
+
+
+ 2. أضف خطوة webhook كمشغل:
+ - اختر `Catch Webhook` كنوع المشغل
+ - سيولّد هذا عنوان URL فريدًا سيستقبل طلبات HTTP ويشغل تدفقك
+
+  +
+
+ - كوّن البريد الإلكتروني لاستخدام نص جسم webhook الخاص بالطاقم
+
+
+
+
+ - كوّن البريد الإلكتروني لاستخدام نص جسم webhook الخاص بالطاقم
+
+  +
+
+
+  +
+
+
+  +
+ - اختر `New Pushed Message` كحدث المشغل.
+ - اربط حساب Slack الخاص بك إذا لم تفعل ذلك بالفعل.
+
+
+ - اختر `New Pushed Message` كحدث المشغل.
+ - اربط حساب Slack الخاص بك إذا لم تفعل ذلك بالفعل.
+  +
+
+
+  +
+ - كوّن مدخلات الطاقم باستخدام البيانات من رسالة Slack.
+
+
+ - كوّن مدخلات الطاقم باستخدام البيانات من رسالة Slack.
+  +
+
+
+
+
+  +
+
+
+  +
+
+
+  +
+
+ - اختر زر النقاط الثلاث ثم اختر Push to Zapier
+
+
+
+
+
+ - اختر زر النقاط الثلاث ثم اختر Push to Zapier
+
+
+  +
+
+
+  +
+
+
+  +
+
+تظهر كل قدرة من قدرات Databricks — **Databricks Genie** و**Databricks SQL** و**Databricks Unity Catalog Functions** و**Databricks Vector Search** — كخادم MCP خاص بها ضمن مجموعة Databricks في صفحة **Tools & Integrations**. هيّئ ما تحتاجه:
+
+
+
+
+تظهر كل قدرة من قدرات Databricks — **Databricks Genie** و**Databricks SQL** و**Databricks Unity Catalog Functions** و**Databricks Vector Search** — كخادم MCP خاص بها ضمن مجموعة Databricks في صفحة **Tools & Integrations**. هيّئ ما تحتاجه:
+
+ +
+
+
+
+
+ +
+
+تعمل منصة CrewAI AMP على توسيع قوة إطار العمل مفتوح المصدر بميزات مصممة لعمليات النشر الإنتاجية والتعاون وقابلية التوسع. انشر أطقمك على بنية تحتية مُدارة وراقب تنفيذها في الوقت الفعلي.
+
+## الميزات الرئيسية
+
+
+
+
+تعمل منصة CrewAI AMP على توسيع قوة إطار العمل مفتوح المصدر بميزات مصممة لعمليات النشر الإنتاجية والتعاون وقابلية التوسع. انشر أطقمك على بنية تحتية مُدارة وراقب تنفيذها في الوقت الفعلي.
+
+## الميزات الرئيسية
+
+ +
+
+تساعد هذه المصفوفة في تصور كيف تتوافق النهج المختلفة مع متطلبات متفاوتة للتعقيد والدقة. لنستكشف ما يعنيه كل ربع وكيف يوجه خياراتك المعمارية.
+
+## شرح مصفوفة التعقيد-الدقة
+
+### ما هو التعقيد؟
+
+في سياق تطبيقات CrewAI، يشير **التعقيد** إلى:
+
+- عدد الخطوات أو العمليات المميزة المطلوبة
+- تنوع المهام التي يجب تنفيذها
+- التبعيات المتبادلة بين المكونات المختلفة
+- الحاجة للمنطق الشرطي والتفرع
+- تطور سير العمل الكلي
+
+### ما هي الدقة؟
+
+**الدقة** في هذا السياق تشير إلى:
+
+- الدقة المطلوبة في المخرجات النهائية
+- الحاجة لنتائج منظمة وقابلة للتنبؤ
+- أهمية إمكانية التكرار
+- مستوى التحكم المطلوب في كل خطوة
+- تحمّل التباين في المخرجات
+
+### الأرباع الأربعة
+
+#### 1. تعقيد منخفض، دقة منخفضة
+
+**الخصائص:**
+- مهام بسيطة ومباشرة
+- تحمّل بعض التباين في المخرجات
+- عدد محدود من الخطوات
+- تطبيقات إبداعية أو استكشافية
+
+**النهج الموصى به:** Crews بسيطة مع عدد قليل من الـ Agents
+
+**أمثلة على حالات الاستخدام:**
+- إنشاء محتوى أساسي
+- العصف الذهني
+- مهام التلخيص البسيطة
+- مساعدة الكتابة الإبداعية
+
+#### 2. تعقيد منخفض، دقة عالية
+
+**الخصائص:**
+- سير عمل بسيطة تتطلب مخرجات دقيقة ومنظمة
+- حاجة لنتائج قابلة للتكرار
+- خطوات محدودة مع متطلبات دقة عالية
+- غالبًا تتضمن معالجة أو تحويل بيانات
+
+**النهج الموصى به:** Flows مع استدعاءات LLM مباشرة أو Crews بسيطة مع مخرجات منظمة
+
+**أمثلة على حالات الاستخدام:**
+- استخراج البيانات وتحويلها
+- ملء النماذج والتحقق منها
+- إنشاء محتوى منظم (JSON، XML)
+- مهام التصنيف البسيطة
+
+#### 3. تعقيد عالٍ، دقة منخفضة
+
+**الخصائص:**
+- عمليات متعددة المراحل بخطوات كثيرة
+- مخرجات إبداعية أو استكشافية
+- تفاعلات معقدة بين المكونات
+- تحمّل التباين في النتائج النهائية
+
+**النهج الموصى به:** Crews معقدة مع عدة Agents متخصصة
+
+**أمثلة على حالات الاستخدام:**
+- البحث والتحليل
+- خطوط إنتاج المحتوى
+- تحليل البيانات الاستكشافي
+- حل المشكلات الإبداعي
+
+#### 4. تعقيد عالٍ، دقة عالية
+
+**الخصائص:**
+- سير عمل معقدة تتطلب مخرجات منظمة
+- خطوات مترابطة متعددة مع متطلبات دقة صارمة
+- حاجة لمعالجة متطورة ونتائج دقيقة معًا
+- غالبًا تطبيقات حرجة المهمة
+
+**النهج الموصى به:** Flows تنسّق عدة Crews مع خطوات تحقق
+
+**أمثلة على حالات الاستخدام:**
+- أنظمة دعم القرار المؤسسية
+- خطوط معالجة بيانات معقدة
+- معالجة مستندات متعددة المراحل
+- تطبيقات الصناعات المنظمة
+
+## الاختيار بين Crews وFlows
+
+### متى تختار Crews
+
+الـ Crews مثالية عندما:
+
+1. **تحتاج ذكاء تعاوني** - عدة Agents بتخصصات مختلفة تحتاج للعمل معًا
+2. **المشكلة تتطلب تفكيرًا ناشئًا** - الحل يستفيد من منظورات ونُهج مختلفة
+3. **المهمة إبداعية أو تحليلية بالأساس** - العمل يتضمن بحثًا أو إنشاء محتوى أو تحليل
+4. **تقدّر القدرة على التكيف على الهيكل الصارم** - سير العمل يمكن أن يستفيد من استقلالية الـ Agent
+5. **تنسيق المخرجات يمكن أن يكون مرنًا نوعًا ما** - بعض التباين في هيكل المخرجات مقبول
+
+```python
+# Example: Research Crew for market analysis
+from crewai import Agent, Crew, Process, Task
+
+# Create specialized agents
+researcher = Agent(
+ role="Market Research Specialist",
+ goal="Find comprehensive market data on emerging technologies",
+ backstory="You are an expert at discovering market trends and gathering data."
+)
+
+analyst = Agent(
+ role="Market Analyst",
+ goal="Analyze market data and identify key opportunities",
+ backstory="You excel at interpreting market data and spotting valuable insights."
+)
+
+# Define their tasks
+research_task = Task(
+ description="Research the current market landscape for AI-powered healthcare solutions",
+ expected_output="Comprehensive market data including key players, market size, and growth trends",
+ agent=researcher
+)
+
+analysis_task = Task(
+ description="Analyze the market data and identify the top 3 investment opportunities",
+ expected_output="Analysis report with 3 recommended investment opportunities and rationale",
+ agent=analyst,
+ context=[research_task]
+)
+
+# Create the crew
+market_analysis_crew = Crew(
+ agents=[researcher, analyst],
+ tasks=[research_task, analysis_task],
+ process=Process.sequential,
+ verbose=True
+)
+
+# Run the crew
+result = market_analysis_crew.kickoff()
+```
+
+### متى تختار Flows
+
+الـ Flows مثالية عندما:
+
+1. **تحتاج تحكمًا دقيقًا في التنفيذ** - سير العمل يتطلب تسلسلًا دقيقًا وإدارة حالة
+2. **التطبيق له متطلبات حالة معقدة** - تحتاج لصيانة وتحويل الحالة عبر خطوات متعددة
+3. **تحتاج مخرجات منظمة وقابلة للتنبؤ** - التطبيق يتطلب نتائج متسقة ومنسّقة
+4. **سير العمل يتضمن منطقًا شرطيًا** - مسارات مختلفة يجب اتخاذها بناءً على نتائج وسيطة
+5. **تحتاج الجمع بين AI وكود إجرائي** - الحل يتطلب قدرات AI وبرمجة تقليدية معًا
+
+```python
+# Example: Customer Support Flow with structured processing
+from crewai.flow.flow import Flow, listen, router, start
+from pydantic import BaseModel
+from typing import List, Dict
+
+# Define structured state
+class SupportTicketState(BaseModel):
+ ticket_id: str = ""
+ customer_name: str = ""
+ issue_description: str = ""
+ category: str = ""
+ priority: str = "medium"
+ resolution: str = ""
+ satisfaction_score: int = 0
+
+class CustomerSupportFlow(Flow[SupportTicketState]):
+ @start()
+ def receive_ticket(self):
+ self.state.ticket_id = "TKT-12345"
+ self.state.customer_name = "Alex Johnson"
+ self.state.issue_description = "Unable to access premium features after payment"
+ return "Ticket received"
+
+ @listen(receive_ticket)
+ def categorize_ticket(self, _):
+ from crewai import LLM
+ llm = LLM(model="openai/gpt-4o-mini")
+
+ prompt = f"""
+ Categorize the following customer support issue into one of these categories:
+ - Billing
+ - Account Access
+ - Technical Issue
+ - Feature Request
+ - Other
+
+ Issue: {self.state.issue_description}
+
+ Return only the category name.
+ """
+
+ self.state.category = llm.call(prompt).strip()
+ return self.state.category
+
+ @router(categorize_ticket)
+ def route_by_category(self, category):
+ return category.lower().replace(" ", "_")
+
+ @listen("billing")
+ def handle_billing_issue(self):
+ self.state.priority = "high"
+ return "Billing issue handled"
+
+ @listen("account_access")
+ def handle_access_issue(self):
+ self.state.priority = "high"
+ return "Access issue handled"
+
+ @listen("billing", "account_access", "technical_issue", "feature_request", "other")
+ def resolve_ticket(self, resolution_info):
+ self.state.resolution = f"Issue resolved: {resolution_info}"
+ return self.state.resolution
+
+# Run the flow
+support_flow = CustomerSupportFlow()
+result = support_flow.kickoff()
+```
+
+### متى تجمع بين Crews وFlows
+
+أكثر التطبيقات تطورًا غالبًا تستفيد من الجمع بين Crews وFlows:
+
+1. **عمليات معقدة متعددة المراحل** - استخدم Flows لتنسيق العملية الكلية وCrews للمهام الفرعية المعقدة
+2. **تطبيقات تتطلب إبداعًا وهيكلاً معًا** - استخدم Crews للمهام الإبداعية وFlows للمعالجة المنظمة
+3. **تطبيقات AI مؤسسية** - استخدم Flows لإدارة الحالة وتدفق العمليات مع الاستفادة من Crews للعمل المتخصص
+
+```python
+# Example: Content Production Pipeline combining Crews and Flows
+from crewai.flow.flow import Flow, listen, start
+from crewai import Agent, Crew, Process, Task
+from pydantic import BaseModel
+from typing import List, Dict
+
+class ContentState(BaseModel):
+ topic: str = ""
+ target_audience: str = ""
+ content_type: str = ""
+ outline: Dict = {}
+ draft_content: str = ""
+ final_content: str = ""
+ seo_score: int = 0
+
+class ContentProductionFlow(Flow[ContentState]):
+ @start()
+ def initialize_project(self):
+ self.state.topic = "Sustainable Investing"
+ self.state.target_audience = "Millennial Investors"
+ self.state.content_type = "Blog Post"
+ return "Project initialized"
+
+ @listen(initialize_project)
+ def create_outline(self, _):
+ researcher = Agent(
+ role="Content Researcher",
+ goal=f"Research {self.state.topic} for {self.state.target_audience}",
+ backstory="You are an expert researcher with deep knowledge of content creation."
+ )
+
+ outliner = Agent(
+ role="Content Strategist",
+ goal=f"Create an engaging outline for a {self.state.content_type}",
+ backstory="You excel at structuring content for maximum engagement."
+ )
+
+ research_task = Task(
+ description=f"Research {self.state.topic} focusing on what would interest {self.state.target_audience}",
+ expected_output="Comprehensive research notes with key points and statistics",
+ agent=researcher
+ )
+
+ outline_task = Task(
+ description=f"Create an outline for a {self.state.content_type} about {self.state.topic}",
+ expected_output="Detailed content outline with sections and key points",
+ agent=outliner,
+ context=[research_task]
+ )
+
+ outline_crew = Crew(
+ agents=[researcher, outliner],
+ tasks=[research_task, outline_task],
+ process=Process.sequential,
+ verbose=True
+ )
+
+ result = outline_crew.kickoff()
+
+ import json
+ try:
+ self.state.outline = json.loads(result.raw)
+ except:
+ self.state.outline = {"sections": result.raw}
+
+ return "Outline created"
+
+ @listen(create_outline)
+ def write_content(self, _):
+ writer = Agent(
+ role="Content Writer",
+ goal=f"Write engaging content for {self.state.target_audience}",
+ backstory="You are a skilled writer who creates compelling content."
+ )
+
+ editor = Agent(
+ role="Content Editor",
+ goal="Ensure content is polished, accurate, and engaging",
+ backstory="You have a keen eye for detail and a talent for improving content."
+ )
+
+ writing_task = Task(
+ description=f"Write a {self.state.content_type} about {self.state.topic} following this outline: {self.state.outline}",
+ expected_output="Complete draft content in markdown format",
+ agent=writer
+ )
+
+ editing_task = Task(
+ description="Edit and improve the draft content for clarity, engagement, and accuracy",
+ expected_output="Polished final content in markdown format",
+ agent=editor,
+ context=[writing_task]
+ )
+
+ writing_crew = Crew(
+ agents=[writer, editor],
+ tasks=[writing_task, editing_task],
+ process=Process.sequential,
+ verbose=True
+ )
+
+ result = writing_crew.kickoff()
+ self.state.final_content = result.raw
+
+ return "Content created"
+
+ @listen(write_content)
+ def optimize_for_seo(self, _):
+ from crewai import LLM
+ llm = LLM(model="openai/gpt-4o-mini")
+
+ prompt = f"""
+ Analyze this content for SEO effectiveness for the keyword "{self.state.topic}".
+ Rate it on a scale of 1-100 and provide 3 specific recommendations for improvement.
+
+ Content: {self.state.final_content[:1000]}... (truncated for brevity)
+
+ Format your response as JSON with the following structure:
+ {{
+ "score": 85,
+ "recommendations": [
+ "Recommendation 1",
+ "Recommendation 2",
+ "Recommendation 3"
+ ]
+ }}
+ """
+
+ seo_analysis = llm.call(prompt)
+
+ import json
+ try:
+ analysis = json.loads(seo_analysis)
+ self.state.seo_score = analysis.get("score", 0)
+ return analysis
+ except:
+ self.state.seo_score = 50
+ return {"score": 50, "recommendations": ["Unable to parse SEO analysis"]}
+
+# Run the flow
+content_flow = ContentProductionFlow()
+result = content_flow.kickoff()
+```
+
+## إطار التقييم العملي
+
+لتحديد النهج الصحيح لحالة استخدامك المحددة، اتبع إطار التقييم التدريجي هذا:
+
+### الخطوة 1: تقييم التعقيد
+
+قيّم تعقيد تطبيقك على مقياس من 1-10 من خلال النظر في:
+
+1. **عدد الخطوات**: كم عدد العمليات المميزة المطلوبة؟
+ - 1-3 خطوات: تعقيد منخفض (1-3)
+ - 4-7 خطوات: تعقيد متوسط (4-7)
+ - 8+ خطوات: تعقيد عالٍ (8-10)
+
+2. **التبعيات المتبادلة**: ما مدى ترابط الأجزاء المختلفة؟
+ - تبعيات قليلة: تعقيد منخفض (1-3)
+ - بعض التبعيات: تعقيد متوسط (4-7)
+ - تبعيات معقدة كثيرة: تعقيد عالٍ (8-10)
+
+3. **المنطق الشرطي**: ما مقدار التفرع وصنع القرار المطلوب؟
+ - عملية خطية: تعقيد منخفض (1-3)
+ - بعض التفرع: تعقيد متوسط (4-7)
+ - أشجار قرار معقدة: تعقيد عالٍ (8-10)
+
+4. **المعرفة التخصصية**: ما مدى تخصص المعرفة المطلوبة؟
+ - معرفة عامة: تعقيد منخفض (1-3)
+ - بعض المعرفة المتخصصة: تعقيد متوسط (4-7)
+ - خبرة عميقة في مجالات متعددة: تعقيد عالٍ (8-10)
+
+احسب متوسط درجتك لتحديد التعقيد الكلي.
+
+### الخطوة 2: تقييم متطلبات الدقة
+
+قيّم متطلبات الدقة على مقياس من 1-10 من خلال النظر في:
+
+1. **هيكل المخرجات**: ما مدى التنظيم المطلوب في المخرجات؟
+ - نص حر: دقة منخفضة (1-3)
+ - شبه منظم: دقة متوسطة (4-7)
+ - منسّق بشكل صارم (JSON، XML): دقة عالية (8-10)
+
+2. **احتياجات الدقة**: ما أهمية الدقة الواقعية؟
+ - محتوى إبداعي: دقة منخفضة (1-3)
+ - محتوى معلوماتي: دقة متوسطة (4-7)
+ - معلومات حرجة: دقة عالية (8-10)
+
+3. **إمكانية التكرار**: ما مدى اتساق النتائج عبر التشغيلات؟
+ - التباين مقبول: دقة منخفضة (1-3)
+ - بعض الاتساق مطلوب: دقة متوسطة (4-7)
+ - تكرار دقيق مطلوب: دقة عالية (8-10)
+
+4. **تحمّل الأخطاء**: ما تأثير الأخطاء؟
+ - تأثير منخفض: دقة منخفضة (1-3)
+ - تأثير معتدل: دقة متوسطة (4-7)
+ - تأثير عالٍ: دقة عالية (8-10)
+
+احسب متوسط درجتك لتحديد متطلبات الدقة الكلية.
+
+### الخطوة 3: التعيين على المصفوفة
+
+ارسم درجات التعقيد والدقة على المصفوفة:
+
+- **تعقيد منخفض (1-4)، دقة منخفضة (1-4)**: Crews بسيطة
+- **تعقيد منخفض (1-4)، دقة عالية (5-10)**: Flows مع استدعاءات LLM مباشرة
+- **تعقيد عالٍ (5-10)، دقة منخفضة (1-4)**: Crews معقدة
+- **تعقيد عالٍ (5-10)، دقة عالية (5-10)**: Flows تنسّق Crews
+
+### الخطوة 4: مراعاة عوامل إضافية
+
+بالإضافة إلى التعقيد والدقة، ضع في اعتبارك:
+
+1. **وقت التطوير**: غالبًا ما تكون Crews أسرع في النماذج الأولية
+2. **احتياجات الصيانة**: توفر Flows قابلية صيانة أفضل على المدى الطويل
+3. **خبرة الفريق**: ضع في اعتبارك ألفة فريقك مع النُهج المختلفة
+4. **متطلبات التوسع**: عادةً ما تتوسع Flows بشكل أفضل للتطبيقات المعقدة
+5. **احتياجات التكامل**: ضع في اعتبارك كيف سيتكامل الحل مع الأنظمة الحالية
+
+## الخلاصة
+
+الاختيار بين Crews وFlows — أو الجمع بينهما — قرار معماري حاسم يؤثر على فعالية وقابلية صيانة وتوسع تطبيق CrewAI. من خلال تقييم حالة الاستخدام على أبعاد التعقيد والدقة، يمكنك اتخاذ قرارات مدروسة تتماشى مع متطلباتك المحددة.
+
+تذكر أن أفضل نهج غالبًا يتطور مع نضج تطبيقك. ابدأ بأبسط حل يلبي احتياجاتك، وكن مستعدًا لصقل بنيتك مع اكتساب الخبرة ووضوح المتطلبات.
+
+
+
+
+تساعد هذه المصفوفة في تصور كيف تتوافق النهج المختلفة مع متطلبات متفاوتة للتعقيد والدقة. لنستكشف ما يعنيه كل ربع وكيف يوجه خياراتك المعمارية.
+
+## شرح مصفوفة التعقيد-الدقة
+
+### ما هو التعقيد؟
+
+في سياق تطبيقات CrewAI، يشير **التعقيد** إلى:
+
+- عدد الخطوات أو العمليات المميزة المطلوبة
+- تنوع المهام التي يجب تنفيذها
+- التبعيات المتبادلة بين المكونات المختلفة
+- الحاجة للمنطق الشرطي والتفرع
+- تطور سير العمل الكلي
+
+### ما هي الدقة؟
+
+**الدقة** في هذا السياق تشير إلى:
+
+- الدقة المطلوبة في المخرجات النهائية
+- الحاجة لنتائج منظمة وقابلة للتنبؤ
+- أهمية إمكانية التكرار
+- مستوى التحكم المطلوب في كل خطوة
+- تحمّل التباين في المخرجات
+
+### الأرباع الأربعة
+
+#### 1. تعقيد منخفض، دقة منخفضة
+
+**الخصائص:**
+- مهام بسيطة ومباشرة
+- تحمّل بعض التباين في المخرجات
+- عدد محدود من الخطوات
+- تطبيقات إبداعية أو استكشافية
+
+**النهج الموصى به:** Crews بسيطة مع عدد قليل من الـ Agents
+
+**أمثلة على حالات الاستخدام:**
+- إنشاء محتوى أساسي
+- العصف الذهني
+- مهام التلخيص البسيطة
+- مساعدة الكتابة الإبداعية
+
+#### 2. تعقيد منخفض، دقة عالية
+
+**الخصائص:**
+- سير عمل بسيطة تتطلب مخرجات دقيقة ومنظمة
+- حاجة لنتائج قابلة للتكرار
+- خطوات محدودة مع متطلبات دقة عالية
+- غالبًا تتضمن معالجة أو تحويل بيانات
+
+**النهج الموصى به:** Flows مع استدعاءات LLM مباشرة أو Crews بسيطة مع مخرجات منظمة
+
+**أمثلة على حالات الاستخدام:**
+- استخراج البيانات وتحويلها
+- ملء النماذج والتحقق منها
+- إنشاء محتوى منظم (JSON، XML)
+- مهام التصنيف البسيطة
+
+#### 3. تعقيد عالٍ، دقة منخفضة
+
+**الخصائص:**
+- عمليات متعددة المراحل بخطوات كثيرة
+- مخرجات إبداعية أو استكشافية
+- تفاعلات معقدة بين المكونات
+- تحمّل التباين في النتائج النهائية
+
+**النهج الموصى به:** Crews معقدة مع عدة Agents متخصصة
+
+**أمثلة على حالات الاستخدام:**
+- البحث والتحليل
+- خطوط إنتاج المحتوى
+- تحليل البيانات الاستكشافي
+- حل المشكلات الإبداعي
+
+#### 4. تعقيد عالٍ، دقة عالية
+
+**الخصائص:**
+- سير عمل معقدة تتطلب مخرجات منظمة
+- خطوات مترابطة متعددة مع متطلبات دقة صارمة
+- حاجة لمعالجة متطورة ونتائج دقيقة معًا
+- غالبًا تطبيقات حرجة المهمة
+
+**النهج الموصى به:** Flows تنسّق عدة Crews مع خطوات تحقق
+
+**أمثلة على حالات الاستخدام:**
+- أنظمة دعم القرار المؤسسية
+- خطوط معالجة بيانات معقدة
+- معالجة مستندات متعددة المراحل
+- تطبيقات الصناعات المنظمة
+
+## الاختيار بين Crews وFlows
+
+### متى تختار Crews
+
+الـ Crews مثالية عندما:
+
+1. **تحتاج ذكاء تعاوني** - عدة Agents بتخصصات مختلفة تحتاج للعمل معًا
+2. **المشكلة تتطلب تفكيرًا ناشئًا** - الحل يستفيد من منظورات ونُهج مختلفة
+3. **المهمة إبداعية أو تحليلية بالأساس** - العمل يتضمن بحثًا أو إنشاء محتوى أو تحليل
+4. **تقدّر القدرة على التكيف على الهيكل الصارم** - سير العمل يمكن أن يستفيد من استقلالية الـ Agent
+5. **تنسيق المخرجات يمكن أن يكون مرنًا نوعًا ما** - بعض التباين في هيكل المخرجات مقبول
+
+```python
+# Example: Research Crew for market analysis
+from crewai import Agent, Crew, Process, Task
+
+# Create specialized agents
+researcher = Agent(
+ role="Market Research Specialist",
+ goal="Find comprehensive market data on emerging technologies",
+ backstory="You are an expert at discovering market trends and gathering data."
+)
+
+analyst = Agent(
+ role="Market Analyst",
+ goal="Analyze market data and identify key opportunities",
+ backstory="You excel at interpreting market data and spotting valuable insights."
+)
+
+# Define their tasks
+research_task = Task(
+ description="Research the current market landscape for AI-powered healthcare solutions",
+ expected_output="Comprehensive market data including key players, market size, and growth trends",
+ agent=researcher
+)
+
+analysis_task = Task(
+ description="Analyze the market data and identify the top 3 investment opportunities",
+ expected_output="Analysis report with 3 recommended investment opportunities and rationale",
+ agent=analyst,
+ context=[research_task]
+)
+
+# Create the crew
+market_analysis_crew = Crew(
+ agents=[researcher, analyst],
+ tasks=[research_task, analysis_task],
+ process=Process.sequential,
+ verbose=True
+)
+
+# Run the crew
+result = market_analysis_crew.kickoff()
+```
+
+### متى تختار Flows
+
+الـ Flows مثالية عندما:
+
+1. **تحتاج تحكمًا دقيقًا في التنفيذ** - سير العمل يتطلب تسلسلًا دقيقًا وإدارة حالة
+2. **التطبيق له متطلبات حالة معقدة** - تحتاج لصيانة وتحويل الحالة عبر خطوات متعددة
+3. **تحتاج مخرجات منظمة وقابلة للتنبؤ** - التطبيق يتطلب نتائج متسقة ومنسّقة
+4. **سير العمل يتضمن منطقًا شرطيًا** - مسارات مختلفة يجب اتخاذها بناءً على نتائج وسيطة
+5. **تحتاج الجمع بين AI وكود إجرائي** - الحل يتطلب قدرات AI وبرمجة تقليدية معًا
+
+```python
+# Example: Customer Support Flow with structured processing
+from crewai.flow.flow import Flow, listen, router, start
+from pydantic import BaseModel
+from typing import List, Dict
+
+# Define structured state
+class SupportTicketState(BaseModel):
+ ticket_id: str = ""
+ customer_name: str = ""
+ issue_description: str = ""
+ category: str = ""
+ priority: str = "medium"
+ resolution: str = ""
+ satisfaction_score: int = 0
+
+class CustomerSupportFlow(Flow[SupportTicketState]):
+ @start()
+ def receive_ticket(self):
+ self.state.ticket_id = "TKT-12345"
+ self.state.customer_name = "Alex Johnson"
+ self.state.issue_description = "Unable to access premium features after payment"
+ return "Ticket received"
+
+ @listen(receive_ticket)
+ def categorize_ticket(self, _):
+ from crewai import LLM
+ llm = LLM(model="openai/gpt-4o-mini")
+
+ prompt = f"""
+ Categorize the following customer support issue into one of these categories:
+ - Billing
+ - Account Access
+ - Technical Issue
+ - Feature Request
+ - Other
+
+ Issue: {self.state.issue_description}
+
+ Return only the category name.
+ """
+
+ self.state.category = llm.call(prompt).strip()
+ return self.state.category
+
+ @router(categorize_ticket)
+ def route_by_category(self, category):
+ return category.lower().replace(" ", "_")
+
+ @listen("billing")
+ def handle_billing_issue(self):
+ self.state.priority = "high"
+ return "Billing issue handled"
+
+ @listen("account_access")
+ def handle_access_issue(self):
+ self.state.priority = "high"
+ return "Access issue handled"
+
+ @listen("billing", "account_access", "technical_issue", "feature_request", "other")
+ def resolve_ticket(self, resolution_info):
+ self.state.resolution = f"Issue resolved: {resolution_info}"
+ return self.state.resolution
+
+# Run the flow
+support_flow = CustomerSupportFlow()
+result = support_flow.kickoff()
+```
+
+### متى تجمع بين Crews وFlows
+
+أكثر التطبيقات تطورًا غالبًا تستفيد من الجمع بين Crews وFlows:
+
+1. **عمليات معقدة متعددة المراحل** - استخدم Flows لتنسيق العملية الكلية وCrews للمهام الفرعية المعقدة
+2. **تطبيقات تتطلب إبداعًا وهيكلاً معًا** - استخدم Crews للمهام الإبداعية وFlows للمعالجة المنظمة
+3. **تطبيقات AI مؤسسية** - استخدم Flows لإدارة الحالة وتدفق العمليات مع الاستفادة من Crews للعمل المتخصص
+
+```python
+# Example: Content Production Pipeline combining Crews and Flows
+from crewai.flow.flow import Flow, listen, start
+from crewai import Agent, Crew, Process, Task
+from pydantic import BaseModel
+from typing import List, Dict
+
+class ContentState(BaseModel):
+ topic: str = ""
+ target_audience: str = ""
+ content_type: str = ""
+ outline: Dict = {}
+ draft_content: str = ""
+ final_content: str = ""
+ seo_score: int = 0
+
+class ContentProductionFlow(Flow[ContentState]):
+ @start()
+ def initialize_project(self):
+ self.state.topic = "Sustainable Investing"
+ self.state.target_audience = "Millennial Investors"
+ self.state.content_type = "Blog Post"
+ return "Project initialized"
+
+ @listen(initialize_project)
+ def create_outline(self, _):
+ researcher = Agent(
+ role="Content Researcher",
+ goal=f"Research {self.state.topic} for {self.state.target_audience}",
+ backstory="You are an expert researcher with deep knowledge of content creation."
+ )
+
+ outliner = Agent(
+ role="Content Strategist",
+ goal=f"Create an engaging outline for a {self.state.content_type}",
+ backstory="You excel at structuring content for maximum engagement."
+ )
+
+ research_task = Task(
+ description=f"Research {self.state.topic} focusing on what would interest {self.state.target_audience}",
+ expected_output="Comprehensive research notes with key points and statistics",
+ agent=researcher
+ )
+
+ outline_task = Task(
+ description=f"Create an outline for a {self.state.content_type} about {self.state.topic}",
+ expected_output="Detailed content outline with sections and key points",
+ agent=outliner,
+ context=[research_task]
+ )
+
+ outline_crew = Crew(
+ agents=[researcher, outliner],
+ tasks=[research_task, outline_task],
+ process=Process.sequential,
+ verbose=True
+ )
+
+ result = outline_crew.kickoff()
+
+ import json
+ try:
+ self.state.outline = json.loads(result.raw)
+ except:
+ self.state.outline = {"sections": result.raw}
+
+ return "Outline created"
+
+ @listen(create_outline)
+ def write_content(self, _):
+ writer = Agent(
+ role="Content Writer",
+ goal=f"Write engaging content for {self.state.target_audience}",
+ backstory="You are a skilled writer who creates compelling content."
+ )
+
+ editor = Agent(
+ role="Content Editor",
+ goal="Ensure content is polished, accurate, and engaging",
+ backstory="You have a keen eye for detail and a talent for improving content."
+ )
+
+ writing_task = Task(
+ description=f"Write a {self.state.content_type} about {self.state.topic} following this outline: {self.state.outline}",
+ expected_output="Complete draft content in markdown format",
+ agent=writer
+ )
+
+ editing_task = Task(
+ description="Edit and improve the draft content for clarity, engagement, and accuracy",
+ expected_output="Polished final content in markdown format",
+ agent=editor,
+ context=[writing_task]
+ )
+
+ writing_crew = Crew(
+ agents=[writer, editor],
+ tasks=[writing_task, editing_task],
+ process=Process.sequential,
+ verbose=True
+ )
+
+ result = writing_crew.kickoff()
+ self.state.final_content = result.raw
+
+ return "Content created"
+
+ @listen(write_content)
+ def optimize_for_seo(self, _):
+ from crewai import LLM
+ llm = LLM(model="openai/gpt-4o-mini")
+
+ prompt = f"""
+ Analyze this content for SEO effectiveness for the keyword "{self.state.topic}".
+ Rate it on a scale of 1-100 and provide 3 specific recommendations for improvement.
+
+ Content: {self.state.final_content[:1000]}... (truncated for brevity)
+
+ Format your response as JSON with the following structure:
+ {{
+ "score": 85,
+ "recommendations": [
+ "Recommendation 1",
+ "Recommendation 2",
+ "Recommendation 3"
+ ]
+ }}
+ """
+
+ seo_analysis = llm.call(prompt)
+
+ import json
+ try:
+ analysis = json.loads(seo_analysis)
+ self.state.seo_score = analysis.get("score", 0)
+ return analysis
+ except:
+ self.state.seo_score = 50
+ return {"score": 50, "recommendations": ["Unable to parse SEO analysis"]}
+
+# Run the flow
+content_flow = ContentProductionFlow()
+result = content_flow.kickoff()
+```
+
+## إطار التقييم العملي
+
+لتحديد النهج الصحيح لحالة استخدامك المحددة، اتبع إطار التقييم التدريجي هذا:
+
+### الخطوة 1: تقييم التعقيد
+
+قيّم تعقيد تطبيقك على مقياس من 1-10 من خلال النظر في:
+
+1. **عدد الخطوات**: كم عدد العمليات المميزة المطلوبة؟
+ - 1-3 خطوات: تعقيد منخفض (1-3)
+ - 4-7 خطوات: تعقيد متوسط (4-7)
+ - 8+ خطوات: تعقيد عالٍ (8-10)
+
+2. **التبعيات المتبادلة**: ما مدى ترابط الأجزاء المختلفة؟
+ - تبعيات قليلة: تعقيد منخفض (1-3)
+ - بعض التبعيات: تعقيد متوسط (4-7)
+ - تبعيات معقدة كثيرة: تعقيد عالٍ (8-10)
+
+3. **المنطق الشرطي**: ما مقدار التفرع وصنع القرار المطلوب؟
+ - عملية خطية: تعقيد منخفض (1-3)
+ - بعض التفرع: تعقيد متوسط (4-7)
+ - أشجار قرار معقدة: تعقيد عالٍ (8-10)
+
+4. **المعرفة التخصصية**: ما مدى تخصص المعرفة المطلوبة؟
+ - معرفة عامة: تعقيد منخفض (1-3)
+ - بعض المعرفة المتخصصة: تعقيد متوسط (4-7)
+ - خبرة عميقة في مجالات متعددة: تعقيد عالٍ (8-10)
+
+احسب متوسط درجتك لتحديد التعقيد الكلي.
+
+### الخطوة 2: تقييم متطلبات الدقة
+
+قيّم متطلبات الدقة على مقياس من 1-10 من خلال النظر في:
+
+1. **هيكل المخرجات**: ما مدى التنظيم المطلوب في المخرجات؟
+ - نص حر: دقة منخفضة (1-3)
+ - شبه منظم: دقة متوسطة (4-7)
+ - منسّق بشكل صارم (JSON، XML): دقة عالية (8-10)
+
+2. **احتياجات الدقة**: ما أهمية الدقة الواقعية؟
+ - محتوى إبداعي: دقة منخفضة (1-3)
+ - محتوى معلوماتي: دقة متوسطة (4-7)
+ - معلومات حرجة: دقة عالية (8-10)
+
+3. **إمكانية التكرار**: ما مدى اتساق النتائج عبر التشغيلات؟
+ - التباين مقبول: دقة منخفضة (1-3)
+ - بعض الاتساق مطلوب: دقة متوسطة (4-7)
+ - تكرار دقيق مطلوب: دقة عالية (8-10)
+
+4. **تحمّل الأخطاء**: ما تأثير الأخطاء؟
+ - تأثير منخفض: دقة منخفضة (1-3)
+ - تأثير معتدل: دقة متوسطة (4-7)
+ - تأثير عالٍ: دقة عالية (8-10)
+
+احسب متوسط درجتك لتحديد متطلبات الدقة الكلية.
+
+### الخطوة 3: التعيين على المصفوفة
+
+ارسم درجات التعقيد والدقة على المصفوفة:
+
+- **تعقيد منخفض (1-4)، دقة منخفضة (1-4)**: Crews بسيطة
+- **تعقيد منخفض (1-4)، دقة عالية (5-10)**: Flows مع استدعاءات LLM مباشرة
+- **تعقيد عالٍ (5-10)، دقة منخفضة (1-4)**: Crews معقدة
+- **تعقيد عالٍ (5-10)، دقة عالية (5-10)**: Flows تنسّق Crews
+
+### الخطوة 4: مراعاة عوامل إضافية
+
+بالإضافة إلى التعقيد والدقة، ضع في اعتبارك:
+
+1. **وقت التطوير**: غالبًا ما تكون Crews أسرع في النماذج الأولية
+2. **احتياجات الصيانة**: توفر Flows قابلية صيانة أفضل على المدى الطويل
+3. **خبرة الفريق**: ضع في اعتبارك ألفة فريقك مع النُهج المختلفة
+4. **متطلبات التوسع**: عادةً ما تتوسع Flows بشكل أفضل للتطبيقات المعقدة
+5. **احتياجات التكامل**: ضع في اعتبارك كيف سيتكامل الحل مع الأنظمة الحالية
+
+## الخلاصة
+
+الاختيار بين Crews وFlows — أو الجمع بينهما — قرار معماري حاسم يؤثر على فعالية وقابلية صيانة وتوسع تطبيق CrewAI. من خلال تقييم حالة الاستخدام على أبعاد التعقيد والدقة، يمكنك اتخاذ قرارات مدروسة تتماشى مع متطلباتك المحددة.
+
+تذكر أن أفضل نهج غالبًا يتطور مع نضج تطبيقك. ابدأ بأبسط حل يلبي احتياجاتك، وكن مستعدًا لصقل بنيتك مع اكتساب الخبرة ووضوح المتطلبات.
+
+ +
+
+## الخطوة 2: فهم هيكل المشروع
+
+يستخدم الـ crew المبدئي المضمّن في مشروع Flow بنية Python/YAML الكلاسيكية. لاستخدام crew بنمط JSON-first داخل Flow، أنشئ `crew.jsonc` و `agents/*.jsonc` داخل مجلد الـ crew وحمّله عبر `crewai.project.load_crew` كما في [Flows](/ar/concepts/flows#building-your-crews).
+
+```
+guide_creator_flow/
+├── .gitignore
+├── pyproject.toml
+├── README.md
+├── .env
+└── src/
+ └── guide_creator_flow/
+ ├── __init__.py
+ ├── main.py
+ ├── crews/
+ │ └── poem_crew/
+ │ ├── config/
+ │ │ ├── agents.yaml
+ │ │ └── tasks.yaml
+ │ └── poem_crew.py
+ └── tools/
+ └── custom_tool.py
+```
+
+يوفر هذا الهيكل فصلاً واضحًا بين مكونات Flow المختلفة. سنعدّل هذا الهيكل لإنشاء Flow منشئ الدليل.
+
+## الخطوة 3: إضافة Crew كتابة المحتوى
+
+```bash
+crewai flow add-crew content-crew
+```
+
+## الخطوة 4: تهيئة Crew كتابة المحتوى
+
+سنهيئ crew كتابة المحتوى باستخدام JSONC. سنعرّف Agent للكتابة وAgent للمراجعة، ثم نحمّل `crew.jsonc` من خطوة Flow.
+
+1. أنشئ `src/guide_creator_flow/crews/content_crew/agents/content_writer.jsonc`:
+
+```jsonc
+{
+ "role": "Educational Content Writer",
+ "goal": "Create engaging, informative content that thoroughly explains the assigned topic and provides valuable insights to the reader.",
+ "backstory": "You are a talented educational writer who explains complex concepts in accessible language and organizes information clearly.",
+ "llm": "provider/model-id",
+ "settings": {
+ "verbose": true
+ }
+}
+```
+
+2. أنشئ `src/guide_creator_flow/crews/content_crew/agents/content_reviewer.jsonc`:
+
+```jsonc
+{
+ "role": "Educational Content Reviewer and Editor",
+ "goal": "Ensure content is accurate, comprehensive, well-structured, and consistent with previously written sections.",
+ "backstory": "You are a meticulous editor with an eye for detail, clarity, and coherence.",
+ "llm": "provider/model-id",
+ "settings": {
+ "verbose": true
+ }
+}
+```
+
+استبدل `provider/model-id` بالنموذج الذي تستخدمه، مثل `openai/gpt-4o` أو `gemini/gemini-2.0-flash-001` أو `anthropic/claude-sonnet-4-6`.
+
+3. أنشئ `src/guide_creator_flow/crews/content_crew/crew.jsonc`:
+
+```jsonc
+{
+ "name": "Content Crew",
+ "agents": ["content_writer", "content_reviewer"],
+ "tasks": [
+ {
+ "name": "write_section_task",
+ "description": "Write a comprehensive section on the topic: \"{section_title}\".\n\nSection description: {section_description}\nTarget audience: {audience_level} level learners\n\nYour content should begin with a brief introduction, explain key concepts clearly with examples, include practical applications where appropriate, end with a summary, and be approximately 500-800 words.\n\nPreviously written sections:\n{previous_sections}",
+ "expected_output": "A well-structured, comprehensive section in Markdown format that thoroughly explains the topic and is appropriate for the target audience.",
+ "agent": "content_writer",
+ "markdown": true
+ },
+ {
+ "name": "review_section_task",
+ "description": "Review and improve this section on \"{section_title}\":\n\n{draft_content}\n\nTarget audience: {audience_level} level learners\nPreviously written sections:\n{previous_sections}\n\nFix errors, improve clarity, verify consistency, enhance structure, and add missing key information.",
+ "expected_output": "An improved, polished version of the section that maintains the original structure but enhances clarity, accuracy, and consistency.",
+ "agent": "content_reviewer",
+ "context": ["write_section_task"],
+ "markdown": true
+ }
+ ],
+ "process": "sequential",
+ "verbose": true
+}
+```
+
+4. استبدل `src/guide_creator_flow/crews/content_crew/content_crew.py` بمحمل صغير:
+
+```python
+from pathlib import Path
+
+from crewai.project import load_crew
+
+
+def kickoff_content_crew(inputs: dict):
+ crew, default_inputs = load_crew(Path(__file__).with_name("crew.jsonc"))
+ return crew.kickoff(inputs={**default_inputs, **inputs})
+```
+
+## الخطوة 5: إنشاء Flow
+
+الآن الجزء المثير - إنشاء Flow الذي سينسّق عملية إنشاء الدليل بالكامل. راجع الملف الإنجليزي الأصلي للكود الكامل لـ `main.py` حيث أن الكود يبقى كما هو.
+
+## الخطوة 6: إعداد متغيرات البيئة
+
+أنشئ ملف `.env` في جذر مشروعك بمفاتيح API. راجع [دليل إعداد LLM](/ar/concepts/llms#setting-up-your-llm) لتفاصيل تهيئة المزود.
+
+```sh .env
+OPENAI_API_KEY=your_openai_api_key
+# or
+GEMINI_API_KEY=your_gemini_api_key
+# or
+ANTHROPIC_API_KEY=your_anthropic_api_key
+```
+
+## الخطوة 7: تثبيت التبعيات
+
+```bash
+crewai install
+```
+
+## الخطوة 8: تشغيل Flow
+
+```bash
+crewai run
+```
+
+عند تشغيل هذا الأمر، ستشاهد Flow يعمل:
+1. سيطلب منك موضوعًا ومستوى الجمهور
+2. سينشئ مخططًا منظمًا لدليلك
+3. سيعالج كل قسم مع تعاون الكاتب والمراجع
+4. أخيرًا سيجمع كل شيء في دليل شامل
+
+## الخطوة 9: تصوير Flow
+
+```bash
+crewai flow plot
+```
+
+سينشئ ملف HTML يوضح هيكل Flow بما في ذلك العلاقات بين الخطوات المختلفة.
+
+## الخطوة 10: مراجعة المخرجات
+
+بمجرد اكتمال Flow، ستجد ملفين في مجلد `output`:
+
+1. `guide_outline.json`: يحتوي على المخطط المنظم للدليل
+2. `complete_guide.md`: الدليل الشامل بجميع الأقسام
+
+## الميزات الرئيسية الموضّحة
+
+يوضح Flow منشئ الدليل عدة ميزات قوية لـ CrewAI:
+
+1. **تفاعل المستخدم**: يجمع Flow مدخلات مباشرة من المستخدم
+2. **استدعاءات LLM المباشرة**: يستخدم فئة LLM لتفاعلات AI فعّالة وأحادية الغرض
+3. **بيانات منظمة مع Pydantic**: يستخدم نماذج Pydantic لضمان سلامة الأنواع
+4. **معالجة تسلسلية مع سياق**: يكتب الأقسام بالترتيب ويوفر الأقسام السابقة كسياق
+5. **Crews متعددة الـ Agents**: يستفيد من Agents متخصصة (كاتب ومراجع) لإنشاء المحتوى
+6. **إدارة الحالة**: يحافظ على الحالة عبر خطوات العملية المختلفة
+7. **بنية قائمة على الأحداث**: يستخدم مزخرف `@listen` للاستجابة للأحداث
+
+## الخطوات التالية
+
+1. جرّب هياكل Flow أكثر تعقيدًا وأنماطًا
+2. جرّب استخدام `@router()` لإنشاء فروع شرطية
+3. استكشف دوال `and_` و`or_` لتنفيذ متوازٍ أكثر تعقيدًا
+4. اربط Flow بواجهات API خارجية وقواعد بيانات وواجهات مستخدم
+5. ادمج عدة Crews متخصصة في Flow واحد
+6. أنشئ تطبيقات دردشة متعددة الجولات مع [تدفقات المحادثة](/ar/guides/flows/conversational-flows) (`kickoff` لكل رسالة، `ChatSession`، تأجيل التتبع)
+
+
+
+
+## الخطوة 2: فهم هيكل المشروع
+
+يستخدم الـ crew المبدئي المضمّن في مشروع Flow بنية Python/YAML الكلاسيكية. لاستخدام crew بنمط JSON-first داخل Flow، أنشئ `crew.jsonc` و `agents/*.jsonc` داخل مجلد الـ crew وحمّله عبر `crewai.project.load_crew` كما في [Flows](/ar/concepts/flows#building-your-crews).
+
+```
+guide_creator_flow/
+├── .gitignore
+├── pyproject.toml
+├── README.md
+├── .env
+└── src/
+ └── guide_creator_flow/
+ ├── __init__.py
+ ├── main.py
+ ├── crews/
+ │ └── poem_crew/
+ │ ├── config/
+ │ │ ├── agents.yaml
+ │ │ └── tasks.yaml
+ │ └── poem_crew.py
+ └── tools/
+ └── custom_tool.py
+```
+
+يوفر هذا الهيكل فصلاً واضحًا بين مكونات Flow المختلفة. سنعدّل هذا الهيكل لإنشاء Flow منشئ الدليل.
+
+## الخطوة 3: إضافة Crew كتابة المحتوى
+
+```bash
+crewai flow add-crew content-crew
+```
+
+## الخطوة 4: تهيئة Crew كتابة المحتوى
+
+سنهيئ crew كتابة المحتوى باستخدام JSONC. سنعرّف Agent للكتابة وAgent للمراجعة، ثم نحمّل `crew.jsonc` من خطوة Flow.
+
+1. أنشئ `src/guide_creator_flow/crews/content_crew/agents/content_writer.jsonc`:
+
+```jsonc
+{
+ "role": "Educational Content Writer",
+ "goal": "Create engaging, informative content that thoroughly explains the assigned topic and provides valuable insights to the reader.",
+ "backstory": "You are a talented educational writer who explains complex concepts in accessible language and organizes information clearly.",
+ "llm": "provider/model-id",
+ "settings": {
+ "verbose": true
+ }
+}
+```
+
+2. أنشئ `src/guide_creator_flow/crews/content_crew/agents/content_reviewer.jsonc`:
+
+```jsonc
+{
+ "role": "Educational Content Reviewer and Editor",
+ "goal": "Ensure content is accurate, comprehensive, well-structured, and consistent with previously written sections.",
+ "backstory": "You are a meticulous editor with an eye for detail, clarity, and coherence.",
+ "llm": "provider/model-id",
+ "settings": {
+ "verbose": true
+ }
+}
+```
+
+استبدل `provider/model-id` بالنموذج الذي تستخدمه، مثل `openai/gpt-4o` أو `gemini/gemini-2.0-flash-001` أو `anthropic/claude-sonnet-4-6`.
+
+3. أنشئ `src/guide_creator_flow/crews/content_crew/crew.jsonc`:
+
+```jsonc
+{
+ "name": "Content Crew",
+ "agents": ["content_writer", "content_reviewer"],
+ "tasks": [
+ {
+ "name": "write_section_task",
+ "description": "Write a comprehensive section on the topic: \"{section_title}\".\n\nSection description: {section_description}\nTarget audience: {audience_level} level learners\n\nYour content should begin with a brief introduction, explain key concepts clearly with examples, include practical applications where appropriate, end with a summary, and be approximately 500-800 words.\n\nPreviously written sections:\n{previous_sections}",
+ "expected_output": "A well-structured, comprehensive section in Markdown format that thoroughly explains the topic and is appropriate for the target audience.",
+ "agent": "content_writer",
+ "markdown": true
+ },
+ {
+ "name": "review_section_task",
+ "description": "Review and improve this section on \"{section_title}\":\n\n{draft_content}\n\nTarget audience: {audience_level} level learners\nPreviously written sections:\n{previous_sections}\n\nFix errors, improve clarity, verify consistency, enhance structure, and add missing key information.",
+ "expected_output": "An improved, polished version of the section that maintains the original structure but enhances clarity, accuracy, and consistency.",
+ "agent": "content_reviewer",
+ "context": ["write_section_task"],
+ "markdown": true
+ }
+ ],
+ "process": "sequential",
+ "verbose": true
+}
+```
+
+4. استبدل `src/guide_creator_flow/crews/content_crew/content_crew.py` بمحمل صغير:
+
+```python
+from pathlib import Path
+
+from crewai.project import load_crew
+
+
+def kickoff_content_crew(inputs: dict):
+ crew, default_inputs = load_crew(Path(__file__).with_name("crew.jsonc"))
+ return crew.kickoff(inputs={**default_inputs, **inputs})
+```
+
+## الخطوة 5: إنشاء Flow
+
+الآن الجزء المثير - إنشاء Flow الذي سينسّق عملية إنشاء الدليل بالكامل. راجع الملف الإنجليزي الأصلي للكود الكامل لـ `main.py` حيث أن الكود يبقى كما هو.
+
+## الخطوة 6: إعداد متغيرات البيئة
+
+أنشئ ملف `.env` في جذر مشروعك بمفاتيح API. راجع [دليل إعداد LLM](/ar/concepts/llms#setting-up-your-llm) لتفاصيل تهيئة المزود.
+
+```sh .env
+OPENAI_API_KEY=your_openai_api_key
+# or
+GEMINI_API_KEY=your_gemini_api_key
+# or
+ANTHROPIC_API_KEY=your_anthropic_api_key
+```
+
+## الخطوة 7: تثبيت التبعيات
+
+```bash
+crewai install
+```
+
+## الخطوة 8: تشغيل Flow
+
+```bash
+crewai run
+```
+
+عند تشغيل هذا الأمر، ستشاهد Flow يعمل:
+1. سيطلب منك موضوعًا ومستوى الجمهور
+2. سينشئ مخططًا منظمًا لدليلك
+3. سيعالج كل قسم مع تعاون الكاتب والمراجع
+4. أخيرًا سيجمع كل شيء في دليل شامل
+
+## الخطوة 9: تصوير Flow
+
+```bash
+crewai flow plot
+```
+
+سينشئ ملف HTML يوضح هيكل Flow بما في ذلك العلاقات بين الخطوات المختلفة.
+
+## الخطوة 10: مراجعة المخرجات
+
+بمجرد اكتمال Flow، ستجد ملفين في مجلد `output`:
+
+1. `guide_outline.json`: يحتوي على المخطط المنظم للدليل
+2. `complete_guide.md`: الدليل الشامل بجميع الأقسام
+
+## الميزات الرئيسية الموضّحة
+
+يوضح Flow منشئ الدليل عدة ميزات قوية لـ CrewAI:
+
+1. **تفاعل المستخدم**: يجمع Flow مدخلات مباشرة من المستخدم
+2. **استدعاءات LLM المباشرة**: يستخدم فئة LLM لتفاعلات AI فعّالة وأحادية الغرض
+3. **بيانات منظمة مع Pydantic**: يستخدم نماذج Pydantic لضمان سلامة الأنواع
+4. **معالجة تسلسلية مع سياق**: يكتب الأقسام بالترتيب ويوفر الأقسام السابقة كسياق
+5. **Crews متعددة الـ Agents**: يستفيد من Agents متخصصة (كاتب ومراجع) لإنشاء المحتوى
+6. **إدارة الحالة**: يحافظ على الحالة عبر خطوات العملية المختلفة
+7. **بنية قائمة على الأحداث**: يستخدم مزخرف `@listen` للاستجابة للأحداث
+
+## الخطوات التالية
+
+1. جرّب هياكل Flow أكثر تعقيدًا وأنماطًا
+2. جرّب استخدام `@router()` لإنشاء فروع شرطية
+3. استكشف دوال `and_` و`or_` لتنفيذ متوازٍ أكثر تعقيدًا
+4. اربط Flow بواجهات API خارجية وقواعد بيانات وواجهات مستخدم
+5. ادمج عدة Crews متخصصة في Flow واحد
+6. أنشئ تطبيقات دردشة متعددة الجولات مع [تدفقات المحادثة](/ar/guides/flows/conversational-flows) (`kickoff` لكل رسالة، `ChatSession`، تأجيل التتبع)
+
+
+  +
+
+
+
+
+## ابدأ
+
+
+
+
+
+
+أطلق أنظمة متعددة الـ Agents بثقة
++ صمم Agents، ونسّق Crews، وأتمت Flows مع حواجز حماية وذاكرة ومعرفة ومراقبة مدمجة. +
+
+
+
+توفر Flows:
+- **إدارة الحالة**: حفظ البيانات عبر الخطوات والتنفيذات.
+- **تنفيذ قائم على الأحداث**: تشغيل إجراءات بناءً على أحداث أو مدخلات خارجية.
+- **التحكم في التدفق**: استخدام المنطق الشرطي والحلقات والتفرع.
+
+### 2. Crews: الذكاء
+
+ +
+
+توفر Crews:
+- **Agents بأدوار محددة**: Agents متخصصة بأهداف وأدوات محددة.
+- **تعاون مستقل**: تعمل الـ Agents معًا لحل المهام.
+- **تفويض المهام**: يتم تعيين المهام وتنفيذها بناءً على قدرات الـ Agent.
+
+## كيف يعمل الكل معًا
+
+1. يبدأ **Flow** حدثًا أو يشغّل عملية.
+2. يدير **Flow** الحالة ويقرر ما يجب فعله بعد ذلك.
+3. يفوّض **Flow** مهمة معقدة إلى **Crew**.
+4. تتعاون Agents الـ **Crew** لإكمال المهمة.
+5. يعيد **Crew** النتيجة إلى **Flow**.
+6. يستمر **Flow** في التنفيذ بناءً على النتيجة.
+
+## الميزات الرئيسية
+
+
+
+
+توفر Crews:
+- **Agents بأدوار محددة**: Agents متخصصة بأهداف وأدوات محددة.
+- **تعاون مستقل**: تعمل الـ Agents معًا لحل المهام.
+- **تفويض المهام**: يتم تعيين المهام وتنفيذها بناءً على قدرات الـ Agent.
+
+## كيف يعمل الكل معًا
+
+1. يبدأ **Flow** حدثًا أو يشغّل عملية.
+2. يدير **Flow** الحالة ويقرر ما يجب فعله بعد ذلك.
+3. يفوّض **Flow** مهمة معقدة إلى **Crew**.
+4. تتعاون Agents الـ **Crew** لإكمال المهمة.
+5. يعيد **Crew** النتيجة إلى **Flow**.
+6. يستمر **Flow** في التنفيذ بناءً على النتيجة.
+
+## الميزات الرئيسية
+
+ +
+
+
+  +
+
+
+  +
+
+
+  +
+
+بالإضافة إلى ذلك، يمكنك عرض رسم بياني لتنفيذ التتبع، الذي يوضح تدفق التحكم والبيانات للتتبع.
+
+
+
+
+
+بالإضافة إلى ذلك، يمكنك عرض رسم بياني لتنفيذ التتبع، الذي يوضح تدفق التحكم والبيانات للتتبع.
+
+
+ +
+
+## المراجع
+
+- [Datadog LLM Observability](https://www.datadoghq.com/product/llm-observability/)
+- [التجهيز التلقائي لـ CrewAI من Datadog LLM Observability](https://docs.datadoghq.com/llm_observability/instrumentation/auto_instrumentation?tab=python#crew-ai)
diff --git a/docs/v1.15.0/ar/observability/galileo.mdx b/docs/v1.15.0/ar/observability/galileo.mdx
new file mode 100644
index 0000000000..9c51f2306c
--- /dev/null
+++ b/docs/v1.15.0/ar/observability/galileo.mdx
@@ -0,0 +1,86 @@
+---
+title: Galileo
+description: تكامل Galileo مع CrewAI للتتبع والتقييم
+icon: telescope
+mode: "wide"
+---
+
+## نظرة عامة
+
+يوضح هذا الدليل كيفية دمج **Galileo** مع **CrewAI** للتتبع الشامل وهندسة التقييم. بنهاية هذا الدليل، ستتمكن من تتبع وكلاء CrewAI ومراقبة أدائهم وتقييم سلوكهم باستخدام منصة المراقبة القوية من Galileo.
+
+> **ما هو Galileo؟** [Galileo](https://galileo.ai) هو منصة تقييم ومراقبة للذكاء الاصطناعي توفر تتبعاً شاملاً وتقييماً ومراقبة لتطبيقات الذكاء الاصطناعي. تمكّن الفرق من التقاط البيانات الحقيقية وإنشاء حواجز قوية وتشغيل تجارب منهجية مع تتبع تجارب مدمج وتحليلات أداء.
+
+## البدء
+
+يتبع هذا البرنامج التعليمي [البدء السريع مع CrewAI](/ar/quickstart) ويوضح كيفية إضافة [CrewAIEventListener](https://v2docs.galileo.ai/sdk-api/python/reference/handlers/crewai/handler) من Galileo كمعالج أحداث.
+
+> **ملاحظة** يفترض هذا البرنامج التعليمي أنك أكملت [البدء السريع مع CrewAI](/ar/quickstart).
+
+### الخطوة 1: تثبيت الاعتماديات
+
+ثبّت الاعتماديات المطلوبة لتطبيقك:
+
+```bash
+uv add galileo
+```
+
+### الخطوة 2: أضف إلى ملف .env من [البدء السريع مع CrewAI](/ar/quickstart)
+
+```bash
+# Your Galileo API key
+GALILEO_API_KEY="your-galileo-api-key"
+
+# Your Galileo project name
+GALILEO_PROJECT="your-galileo-project-name"
+
+# The name of the Log stream you want to use for logging
+GALILEO_LOG_STREAM="your-galileo-log-stream "
+```
+
+### الخطوة 3: إضافة مستمع أحداث Galileo
+
+لتفعيل التسجيل مع Galileo، تحتاج إلى إنشاء مثيل من `CrewAIEventListener`. استورد حزمة معالج CrewAI من Galileo بإضافة الكود التالي في أعلى ملف main.py:
+
+```python
+from galileo.handlers.crewai.handler import CrewAIEventListener
+```
+
+في بداية دالة التشغيل، أنشئ مستمع الأحداث:
+
+```python
+def run():
+ # Create the event listener
+ CrewAIEventListener()
+ # The rest of your existing code goes here
+```
+
+عند إنشاء مثيل المستمع، يتم تسجيله تلقائياً مع CrewAI.
+
+### الخطوة 4: شغّل طاقمك
+
+شغّل طاقمك باستخدام CrewAI CLI:
+
+```bash
+crewai run
+```
+
+### الخطوة 5: عرض التتبعات في Galileo
+
+بمجرد انتهاء طاقمك، سيتم تفريغ التتبعات وستظهر في Galileo.
+
+
+
+## فهم تكامل Galileo
+
+يتكامل Galileo مع CrewAI عن طريق تسجيل مستمع أحداث يلتقط أحداث تنفيذ الطاقم (مثل إجراءات الوكلاء واستدعاءات الأدوات واستجابات النماذج) ويعيد توجيهها إلى Galileo للمراقبة والتقييم.
+
+### فهم مستمع الأحداث
+
+إنشاء مثيل `CrewAIEventListener()` هو كل ما يلزم لتفعيل Galileo لتشغيل CrewAI. عند الإنشاء، يقوم المستمع بـ:
+
+- التسجيل تلقائياً مع CrewAI
+- قراءة إعدادات Galileo من متغيرات البيئة
+- تسجيل جميع بيانات التشغيل في مشروع Galileo وتدفق السجل المحدد بواسطة `GALILEO_PROJECT` و `GALILEO_LOG_STREAM`
+
+لا يلزم أي إعداد إضافي أو تغييرات في الكود.
diff --git a/docs/v1.15.0/ar/observability/langdb.mdx b/docs/v1.15.0/ar/observability/langdb.mdx
new file mode 100644
index 0000000000..42726faaaf
--- /dev/null
+++ b/docs/v1.15.0/ar/observability/langdb.mdx
@@ -0,0 +1,167 @@
+---
+title: تكامل LangDB
+description: إدارة وتأمين وتحسين سير عمل CrewAI مع بوابة LangDB AI — الوصول إلى أكثر من 350 نموذجاً وتوجيه تلقائي وتحسين التكاليف ومراقبة كاملة.
+icon: database
+mode: "wide"
+---
+
+# مقدمة
+
+توفر [بوابة LangDB AI](https://langdb.ai) واجهات API متوافقة مع OpenAI للاتصال بنماذج لغة كبيرة متعددة وتعمل كمنصة مراقبة تجعل تتبع سير عمل CrewAI شاملاً وسهلاً مع توفير الوصول إلى أكثر من 350 نموذج لغة. مع استدعاء `init()` واحد، يتم التقاط جميع تفاعلات الوكلاء وتنفيذ المهام واستدعاءات LLM، مما يوفر مراقبة شاملة وبنية تحتية جاهزة للإنتاج لتطبيقاتك.
+
+
+
+
+
+## المراجع
+
+- [Datadog LLM Observability](https://www.datadoghq.com/product/llm-observability/)
+- [التجهيز التلقائي لـ CrewAI من Datadog LLM Observability](https://docs.datadoghq.com/llm_observability/instrumentation/auto_instrumentation?tab=python#crew-ai)
diff --git a/docs/v1.15.0/ar/observability/galileo.mdx b/docs/v1.15.0/ar/observability/galileo.mdx
new file mode 100644
index 0000000000..9c51f2306c
--- /dev/null
+++ b/docs/v1.15.0/ar/observability/galileo.mdx
@@ -0,0 +1,86 @@
+---
+title: Galileo
+description: تكامل Galileo مع CrewAI للتتبع والتقييم
+icon: telescope
+mode: "wide"
+---
+
+## نظرة عامة
+
+يوضح هذا الدليل كيفية دمج **Galileo** مع **CrewAI** للتتبع الشامل وهندسة التقييم. بنهاية هذا الدليل، ستتمكن من تتبع وكلاء CrewAI ومراقبة أدائهم وتقييم سلوكهم باستخدام منصة المراقبة القوية من Galileo.
+
+> **ما هو Galileo؟** [Galileo](https://galileo.ai) هو منصة تقييم ومراقبة للذكاء الاصطناعي توفر تتبعاً شاملاً وتقييماً ومراقبة لتطبيقات الذكاء الاصطناعي. تمكّن الفرق من التقاط البيانات الحقيقية وإنشاء حواجز قوية وتشغيل تجارب منهجية مع تتبع تجارب مدمج وتحليلات أداء.
+
+## البدء
+
+يتبع هذا البرنامج التعليمي [البدء السريع مع CrewAI](/ar/quickstart) ويوضح كيفية إضافة [CrewAIEventListener](https://v2docs.galileo.ai/sdk-api/python/reference/handlers/crewai/handler) من Galileo كمعالج أحداث.
+
+> **ملاحظة** يفترض هذا البرنامج التعليمي أنك أكملت [البدء السريع مع CrewAI](/ar/quickstart).
+
+### الخطوة 1: تثبيت الاعتماديات
+
+ثبّت الاعتماديات المطلوبة لتطبيقك:
+
+```bash
+uv add galileo
+```
+
+### الخطوة 2: أضف إلى ملف .env من [البدء السريع مع CrewAI](/ar/quickstart)
+
+```bash
+# Your Galileo API key
+GALILEO_API_KEY="your-galileo-api-key"
+
+# Your Galileo project name
+GALILEO_PROJECT="your-galileo-project-name"
+
+# The name of the Log stream you want to use for logging
+GALILEO_LOG_STREAM="your-galileo-log-stream "
+```
+
+### الخطوة 3: إضافة مستمع أحداث Galileo
+
+لتفعيل التسجيل مع Galileo، تحتاج إلى إنشاء مثيل من `CrewAIEventListener`. استورد حزمة معالج CrewAI من Galileo بإضافة الكود التالي في أعلى ملف main.py:
+
+```python
+from galileo.handlers.crewai.handler import CrewAIEventListener
+```
+
+في بداية دالة التشغيل، أنشئ مستمع الأحداث:
+
+```python
+def run():
+ # Create the event listener
+ CrewAIEventListener()
+ # The rest of your existing code goes here
+```
+
+عند إنشاء مثيل المستمع، يتم تسجيله تلقائياً مع CrewAI.
+
+### الخطوة 4: شغّل طاقمك
+
+شغّل طاقمك باستخدام CrewAI CLI:
+
+```bash
+crewai run
+```
+
+### الخطوة 5: عرض التتبعات في Galileo
+
+بمجرد انتهاء طاقمك، سيتم تفريغ التتبعات وستظهر في Galileo.
+
+
+
+## فهم تكامل Galileo
+
+يتكامل Galileo مع CrewAI عن طريق تسجيل مستمع أحداث يلتقط أحداث تنفيذ الطاقم (مثل إجراءات الوكلاء واستدعاءات الأدوات واستجابات النماذج) ويعيد توجيهها إلى Galileo للمراقبة والتقييم.
+
+### فهم مستمع الأحداث
+
+إنشاء مثيل `CrewAIEventListener()` هو كل ما يلزم لتفعيل Galileo لتشغيل CrewAI. عند الإنشاء، يقوم المستمع بـ:
+
+- التسجيل تلقائياً مع CrewAI
+- قراءة إعدادات Galileo من متغيرات البيئة
+- تسجيل جميع بيانات التشغيل في مشروع Galileo وتدفق السجل المحدد بواسطة `GALILEO_PROJECT` و `GALILEO_LOG_STREAM`
+
+لا يلزم أي إعداد إضافي أو تغييرات في الكود.
diff --git a/docs/v1.15.0/ar/observability/langdb.mdx b/docs/v1.15.0/ar/observability/langdb.mdx
new file mode 100644
index 0000000000..42726faaaf
--- /dev/null
+++ b/docs/v1.15.0/ar/observability/langdb.mdx
@@ -0,0 +1,167 @@
+---
+title: تكامل LangDB
+description: إدارة وتأمين وتحسين سير عمل CrewAI مع بوابة LangDB AI — الوصول إلى أكثر من 350 نموذجاً وتوجيه تلقائي وتحسين التكاليف ومراقبة كاملة.
+icon: database
+mode: "wide"
+---
+
+# مقدمة
+
+توفر [بوابة LangDB AI](https://langdb.ai) واجهات API متوافقة مع OpenAI للاتصال بنماذج لغة كبيرة متعددة وتعمل كمنصة مراقبة تجعل تتبع سير عمل CrewAI شاملاً وسهلاً مع توفير الوصول إلى أكثر من 350 نموذج لغة. مع استدعاء `init()` واحد، يتم التقاط جميع تفاعلات الوكلاء وتنفيذ المهام واستدعاءات LLM، مما يوفر مراقبة شاملة وبنية تحتية جاهزة للإنتاج لتطبيقاتك.
+
+
+  +
+
+**تحقق من:** [عرض مثال التتبع المباشر](https://app.langdb.ai/sharing/threads/3becbfed-a1be-ae84-ea3c-4942867a3e22)
+
+## الميزات
+
+### قدرات بوابة AI
+- **الوصول إلى أكثر من 350 LLM**: الاتصال بجميع نماذج اللغة الرئيسية من خلال تكامل واحد
+- **النماذج الافتراضية**: إنشاء إعدادات نماذج مخصصة مع معاملات وقواعد توجيه محددة
+- **MCP الافتراضي**: تفعيل التوافق والتكامل مع أنظمة MCP لتعزيز اتصال الوكلاء
+- **حواجز الحماية**: تنفيذ تدابير السلامة وضوابط الامتثال لسلوك الوكلاء
+
+### المراقبة والتتبع
+- **تتبع تلقائي**: استدعاء `init()` واحد يلتقط جميع تفاعلات CrewAI
+- **رؤية شاملة**: مراقبة سير عمل الوكلاء من البداية إلى النهاية
+- **تتبع استخدام الأدوات**: تتبع الأدوات التي يستخدمها الوكلاء ونتائجها
+- **مراقبة استدعاءات النماذج**: رؤى مفصلة لتفاعلات LLM
+- **تحليلات الأداء**: مراقبة زمن الاستجابة واستخدام الرموز والتكاليف
+- **دعم التصحيح**: تنفيذ خطوة بخطوة لاستكشاف الأخطاء
+- **المراقبة في الوقت الفعلي**: لوحة معلومات التتبعات والمقاييس الحية
+
+## تعليمات الإعداد
+
+
+
+
+**تحقق من:** [عرض مثال التتبع المباشر](https://app.langdb.ai/sharing/threads/3becbfed-a1be-ae84-ea3c-4942867a3e22)
+
+## الميزات
+
+### قدرات بوابة AI
+- **الوصول إلى أكثر من 350 LLM**: الاتصال بجميع نماذج اللغة الرئيسية من خلال تكامل واحد
+- **النماذج الافتراضية**: إنشاء إعدادات نماذج مخصصة مع معاملات وقواعد توجيه محددة
+- **MCP الافتراضي**: تفعيل التوافق والتكامل مع أنظمة MCP لتعزيز اتصال الوكلاء
+- **حواجز الحماية**: تنفيذ تدابير السلامة وضوابط الامتثال لسلوك الوكلاء
+
+### المراقبة والتتبع
+- **تتبع تلقائي**: استدعاء `init()` واحد يلتقط جميع تفاعلات CrewAI
+- **رؤية شاملة**: مراقبة سير عمل الوكلاء من البداية إلى النهاية
+- **تتبع استخدام الأدوات**: تتبع الأدوات التي يستخدمها الوكلاء ونتائجها
+- **مراقبة استدعاءات النماذج**: رؤى مفصلة لتفاعلات LLM
+- **تحليلات الأداء**: مراقبة زمن الاستجابة واستخدام الرموز والتكاليف
+- **دعم التصحيح**: تنفيذ خطوة بخطوة لاستكشاف الأخطاء
+- **المراقبة في الوقت الفعلي**: لوحة معلومات التتبعات والمقاييس الحية
+
+## تعليمات الإعداد
+
+ +
+
+### ما ستراه
+
+- **تفاعلات الوكلاء**: التدفق الكامل لمحادثات الوكلاء وتسليم المهام
+- **استخدام الأدوات**: الأدوات التي تم استدعاؤها ومدخلاتها ومخرجاتها
+- **استدعاءات النماذج**: تفاعلات LLM المفصلة مع المطالبات والاستجابات
+- **مقاييس الأداء**: تتبع زمن الاستجابة واستخدام الرموز والتكاليف
+- **الجدول الزمني للتنفيذ**: عرض خطوة بخطوة لسير العمل بالكامل
+
+## استكشاف الأخطاء وإصلاحها
+
+### المشاكل الشائعة
+
+- **عدم ظهور تتبعات**: تأكد من استدعاء `init()` قبل أي استيرادات CrewAI
+- **أخطاء المصادقة**: تحقق من مفتاح API ومعرف المشروع في LangDB
+
+## الموارد
+
+
+
+
+### ما ستراه
+
+- **تفاعلات الوكلاء**: التدفق الكامل لمحادثات الوكلاء وتسليم المهام
+- **استخدام الأدوات**: الأدوات التي تم استدعاؤها ومدخلاتها ومخرجاتها
+- **استدعاءات النماذج**: تفاعلات LLM المفصلة مع المطالبات والاستجابات
+- **مقاييس الأداء**: تتبع زمن الاستجابة واستخدام الرموز والتكاليف
+- **الجدول الزمني للتنفيذ**: عرض خطوة بخطوة لسير العمل بالكامل
+
+## استكشاف الأخطاء وإصلاحها
+
+### المشاكل الشائعة
+
+- **عدم ظهور تتبعات**: تأكد من استدعاء `init()` قبل أي استيرادات CrewAI
+- **أخطاء المصادقة**: تحقق من مفتاح API ومعرف المشروع في LangDB
+
+## الموارد
+
+ +
+  +
+  +
+
+
+ + تقييم السجلات الملتقطة تلقائياً من واجهة المستخدم بناءً على المرشحات والعينات +
++ استخدام التقييم البشري أو التصنيف لتقييم جودة سجلاتك +
++ تقييم أي مكون من تتبعك أو سجلك للحصول على رؤى حول سلوك وكيلك +
+ +
+ 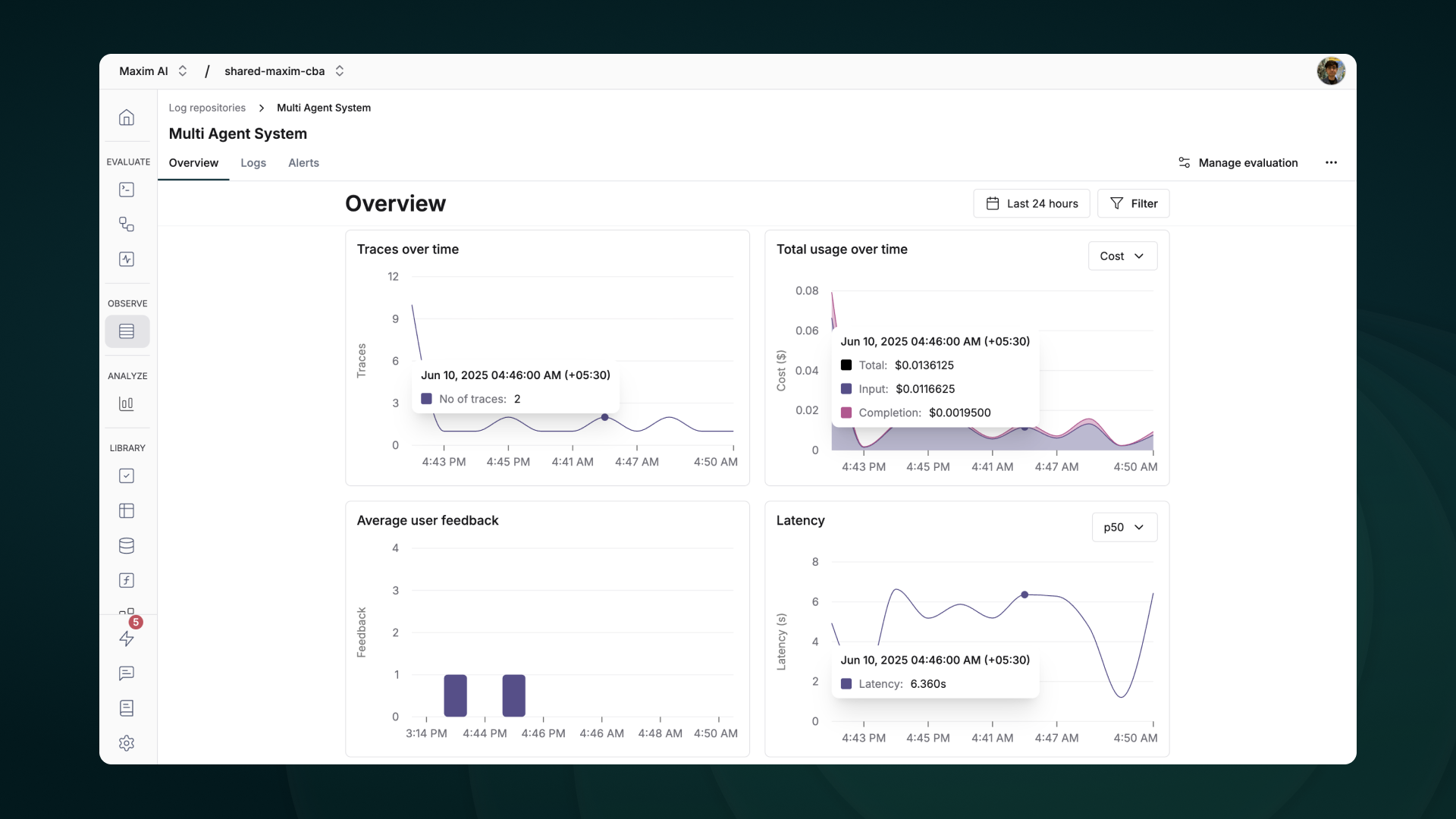 +
+ 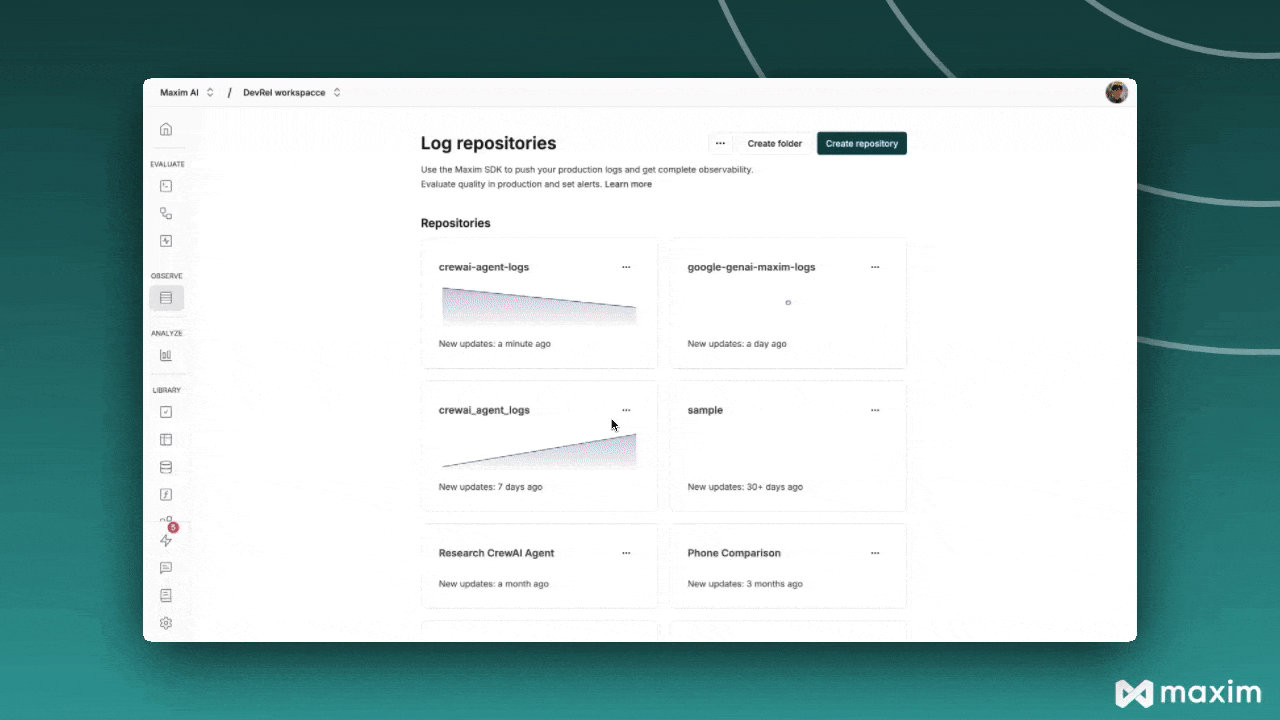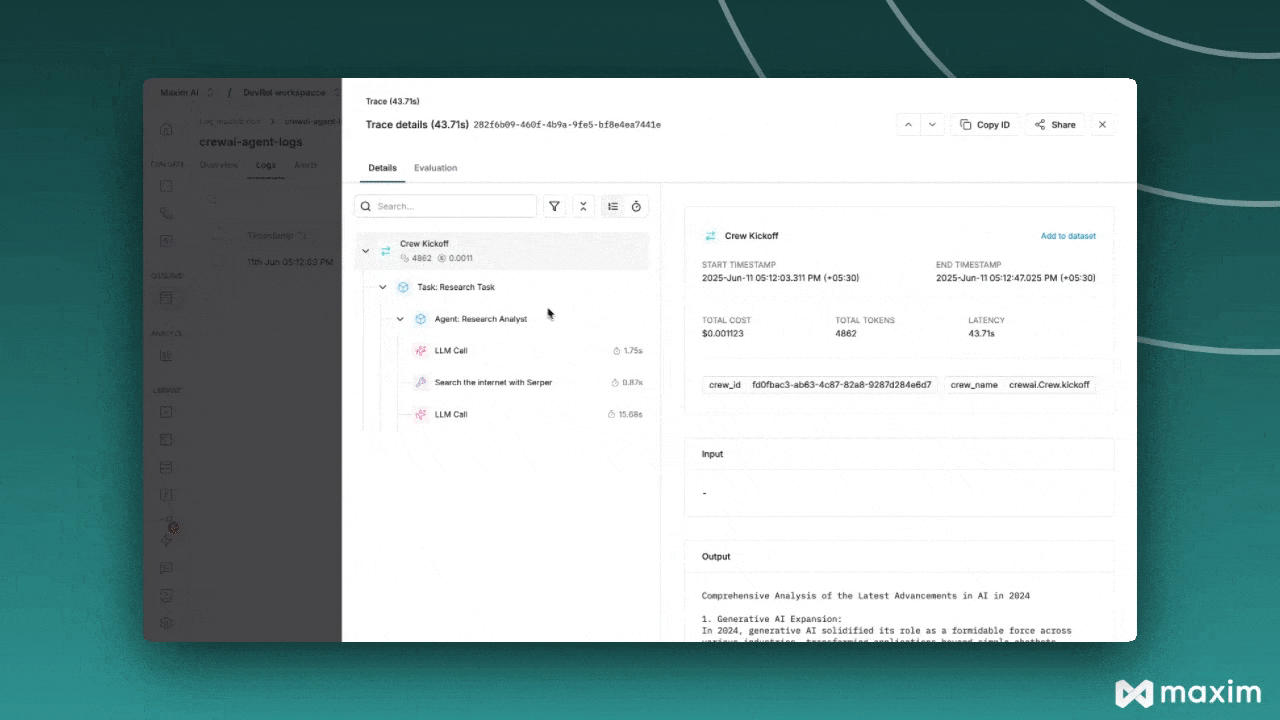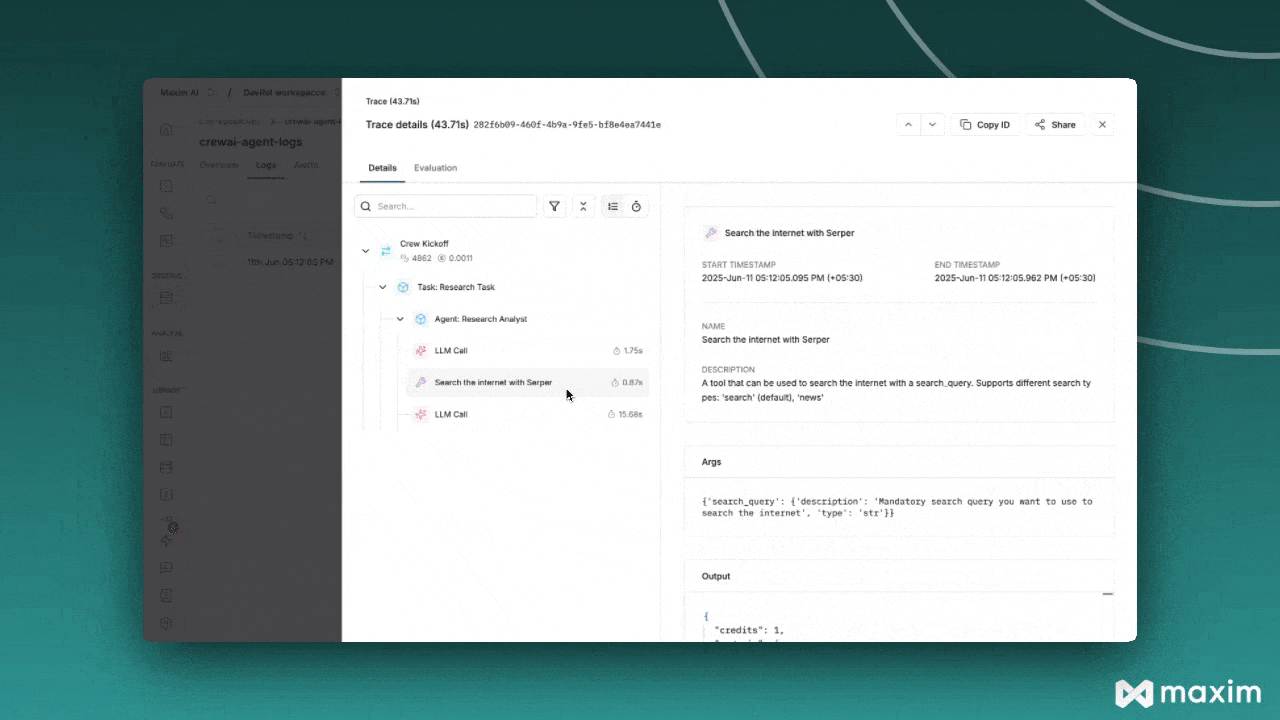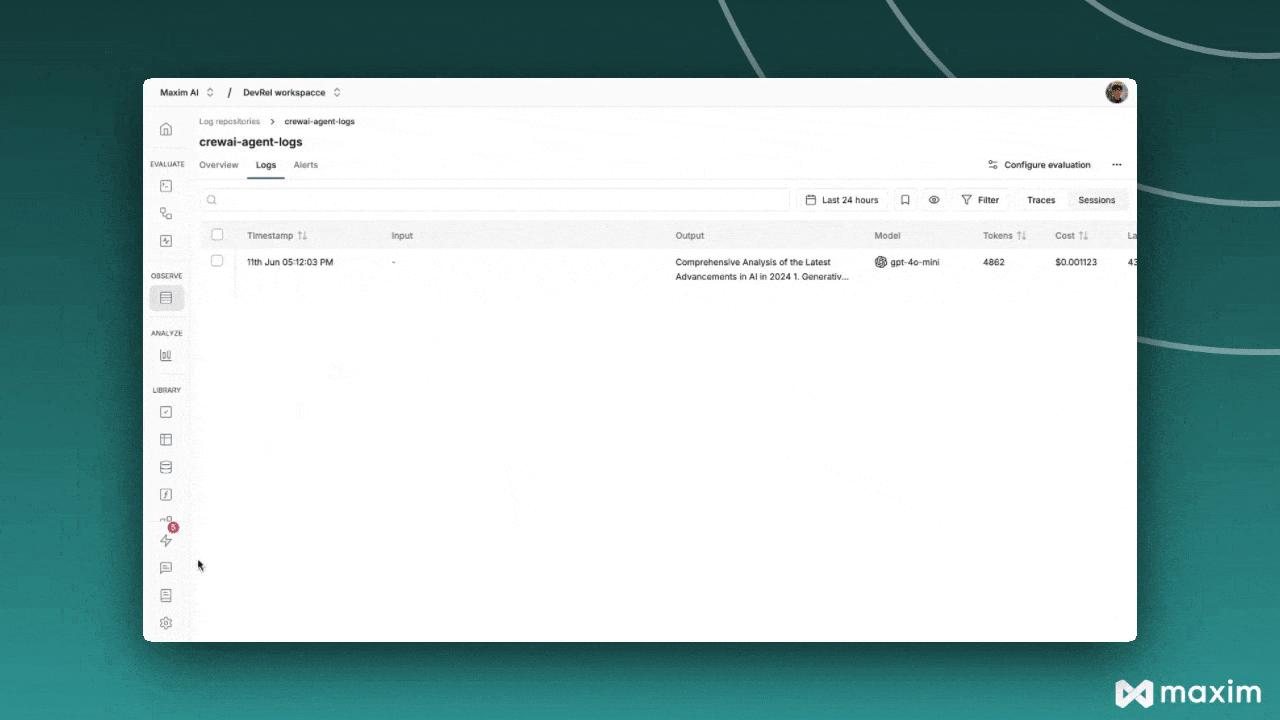 +
+## استكشاف الأخطاء وإصلاحها
+
+### المشاكل الشائعة
+
+- **عدم ظهور تتبعات**: تأكد من صحة مفتاح API ومعرف المستودع
+- تأكد من استدعاء **`instrument_crewai()`** **_قبل_** تشغيل طاقمك
+- عيّن `debug=True` في استدعاء `instrument_crewai()` لإظهار أي أخطاء داخلية:
+
+ ```python
+ instrument_crewai(logger, debug=True)
+ ```
+- أعدّ وكلاءك مع `verbose=True` لالتقاط سجلات مفصلة
+- تحقق مرة أخرى من أن `instrument_crewai()` يُستدعى **قبل** إنشاء أو تنفيذ الوكلاء
+
+## الموارد
+
+
+
+## استكشاف الأخطاء وإصلاحها
+
+### المشاكل الشائعة
+
+- **عدم ظهور تتبعات**: تأكد من صحة مفتاح API ومعرف المستودع
+- تأكد من استدعاء **`instrument_crewai()`** **_قبل_** تشغيل طاقمك
+- عيّن `debug=True` في استدعاء `instrument_crewai()` لإظهار أي أخطاء داخلية:
+
+ ```python
+ instrument_crewai(logger, debug=True)
+ ```
+- أعدّ وكلاءك مع `verbose=True` لالتقاط سجلات مفصلة
+- تحقق مرة أخرى من أن `instrument_crewai()` يُستدعى **قبل** إنشاء أو تنفيذ الوكلاء
+
+## الموارد
+
+ +
+
+
+  +
+  +
+  +
+
+### الميزات
+
+- **لوحة معلومات التحليلات**: راقب صحة وأداء وكلائك من خلال لوحات معلومات تفصيلية تتتبع المقاييس والتكاليف وتفاعلات المستخدمين.
+- **SDK مراقبة أصلي لـ OpenTelemetry**: حزم SDK محايدة للمورد لإرسال التتبعات والمقاييس إلى أدوات المراقبة الحالية مثل Grafana وDataDog وغيرها.
+- **تتبع التكاليف للنماذج المخصصة والمعدّلة**: خصّص تقديرات التكلفة لنماذج محددة باستخدام ملفات تسعير مخصصة لوضع ميزانية دقيقة.
+- **لوحة مراقبة الاستثناءات**: اكتشف وحل المشكلات بسرعة من خلال تتبع الاستثناءات والأخطاء الشائعة بلوحة مراقبة.
+- **الامتثال والأمان**: اكتشف التهديدات المحتملة مثل الألفاظ البذيئة وتسريبات المعلومات الشخصية.
+- **كشف حقن الموجهات**: حدد حقن الكود المحتمل وتسريبات الأسرار.
+- **إدارة مفاتيح API والأسرار**: تعامل مع مفاتيح API لنماذج LLM وأسرارك مركزياً بأمان، مع تجنب الممارسات غير الآمنة.
+- **إدارة الموجهات**: أدر وأصدر موجهات الوكلاء باستخدام PromptHub للوصول المتسق والسهل عبر الوكلاء.
+- **ساحة تجربة النماذج**: اختبر وقارن نماذج مختلفة لوكلاء CrewAI قبل النشر.
+
+## تعليمات الإعداد
+
+
+
+
+
+
+
+
+### الميزات
+
+- **لوحة معلومات التحليلات**: راقب صحة وأداء وكلائك من خلال لوحات معلومات تفصيلية تتتبع المقاييس والتكاليف وتفاعلات المستخدمين.
+- **SDK مراقبة أصلي لـ OpenTelemetry**: حزم SDK محايدة للمورد لإرسال التتبعات والمقاييس إلى أدوات المراقبة الحالية مثل Grafana وDataDog وغيرها.
+- **تتبع التكاليف للنماذج المخصصة والمعدّلة**: خصّص تقديرات التكلفة لنماذج محددة باستخدام ملفات تسعير مخصصة لوضع ميزانية دقيقة.
+- **لوحة مراقبة الاستثناءات**: اكتشف وحل المشكلات بسرعة من خلال تتبع الاستثناءات والأخطاء الشائعة بلوحة مراقبة.
+- **الامتثال والأمان**: اكتشف التهديدات المحتملة مثل الألفاظ البذيئة وتسريبات المعلومات الشخصية.
+- **كشف حقن الموجهات**: حدد حقن الكود المحتمل وتسريبات الأسرار.
+- **إدارة مفاتيح API والأسرار**: تعامل مع مفاتيح API لنماذج LLM وأسرارك مركزياً بأمان، مع تجنب الممارسات غير الآمنة.
+- **إدارة الموجهات**: أدر وأصدر موجهات الوكلاء باستخدام PromptHub للوصول المتسق والسهل عبر الوكلاء.
+- **ساحة تجربة النماذج**: اختبر وقارن نماذج مختلفة لوكلاء CrewAI قبل النشر.
+
+## تعليمات الإعداد
+
+
+
+
+
+  +
+
+يوفر Opik دعماً شاملاً لكل مرحلة من مراحل تطوير تطبيق CrewAI الخاص بك:
+
+- **تسجيل التتبعات والنطاقات**: تتبع تلقائي لاستدعاءات LLM ومنطق التطبيق لتصحيح الأخطاء وتحليل أنظمة التطوير والإنتاج. أضف التعليقات التوضيحية يدوياً أو برمجياً، واعرض وقارن الاستجابات عبر المشاريع.
+- **تقييم أداء تطبيق LLM**: قيّم وفقاً لمجموعة اختبار مخصصة وشغّل مقاييس تقييم مدمجة أو حدد مقاييسك الخاصة في SDK أو واجهة المستخدم.
+- **الاختبار ضمن خط أنابيب CI/CD**: أنشئ خطوط أساس أداء موثوقة مع اختبارات وحدة LLM من Opik، المبنية على PyTest. شغّل تقييمات عبر الإنترنت للمراقبة المستمرة في الإنتاج.
+- **مراقبة وتحليل بيانات الإنتاج**: افهم أداء نماذجك على بيانات غير مرئية في الإنتاج وأنشئ مجموعات بيانات لتكرارات التطوير الجديدة.
+
+## الإعداد
+يوفر Comet نسخة مستضافة من منصة Opik، أو يمكنك تشغيل المنصة محلياً.
+
+لاستخدام النسخة المستضافة، ما عليك سوى [إنشاء حساب Comet مجاني](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) والحصول على مفتاح API الخاص بك.
+
+لتشغيل منصة Opik محلياً، راجع [دليل التثبيت](https://www.comet.com/docs/opik/self-host/overview/) لمزيد من المعلومات.
+
+في هذا الدليل سنستخدم مثال البدء السريع الخاص بـ CrewAI.
+
+
+
+
+يوفر Opik دعماً شاملاً لكل مرحلة من مراحل تطوير تطبيق CrewAI الخاص بك:
+
+- **تسجيل التتبعات والنطاقات**: تتبع تلقائي لاستدعاءات LLM ومنطق التطبيق لتصحيح الأخطاء وتحليل أنظمة التطوير والإنتاج. أضف التعليقات التوضيحية يدوياً أو برمجياً، واعرض وقارن الاستجابات عبر المشاريع.
+- **تقييم أداء تطبيق LLM**: قيّم وفقاً لمجموعة اختبار مخصصة وشغّل مقاييس تقييم مدمجة أو حدد مقاييسك الخاصة في SDK أو واجهة المستخدم.
+- **الاختبار ضمن خط أنابيب CI/CD**: أنشئ خطوط أساس أداء موثوقة مع اختبارات وحدة LLM من Opik، المبنية على PyTest. شغّل تقييمات عبر الإنترنت للمراقبة المستمرة في الإنتاج.
+- **مراقبة وتحليل بيانات الإنتاج**: افهم أداء نماذجك على بيانات غير مرئية في الإنتاج وأنشئ مجموعات بيانات لتكرارات التطوير الجديدة.
+
+## الإعداد
+يوفر Comet نسخة مستضافة من منصة Opik، أو يمكنك تشغيل المنصة محلياً.
+
+لاستخدام النسخة المستضافة، ما عليك سوى [إنشاء حساب Comet مجاني](https://www.comet.com/signup?utm_medium=github&utm_source=crewai_docs) والحصول على مفتاح API الخاص بك.
+
+لتشغيل منصة Opik محلياً، راجع [دليل التثبيت](https://www.comet.com/docs/opik/self-host/overview/) لمزيد من المعلومات.
+
+في هذا الدليل سنستخدم مثال البدء السريع الخاص بـ CrewAI.
+
+ +
+
+
+## مقدمة
+
+يعزز Portkey إمكانيات CrewAI بميزات جاهزة للإنتاج، محولاً طواقم الوكلاء التجريبية إلى أنظمة متينة من خلال توفير:
+
+- **مراقبة كاملة** لكل خطوة وكيل واستخدام أداة وتفاعل
+- **موثوقية مدمجة** مع آليات الاحتياط وإعادة المحاولة وموازنة الأحمال
+- **تتبع التكاليف وتحسينها** لإدارة إنفاقك على الذكاء الاصطناعي
+- **الوصول إلى أكثر من 200 نموذج LLM** من خلال تكامل واحد
+- **حواجز الحماية** للحفاظ على سلوك الوكلاء آمناً ومتوافقاً
+- **موجهات مُتحكم بإصداراتها** لأداء وكلاء متسق
+
+
+### التثبيت والإعداد
+
+
+
+
+
+## مقدمة
+
+يعزز Portkey إمكانيات CrewAI بميزات جاهزة للإنتاج، محولاً طواقم الوكلاء التجريبية إلى أنظمة متينة من خلال توفير:
+
+- **مراقبة كاملة** لكل خطوة وكيل واستخدام أداة وتفاعل
+- **موثوقية مدمجة** مع آليات الاحتياط وإعادة المحاولة وموازنة الأحمال
+- **تتبع التكاليف وتحسينها** لإدارة إنفاقك على الذكاء الاصطناعي
+- **الوصول إلى أكثر من 200 نموذج LLM** من خلال تكامل واحد
+- **حواجز الحماية** للحفاظ على سلوك الوكلاء آمناً ومتوافقاً
+- **موجهات مُتحكم بإصداراتها** لأداء وكلاء متسق
+
+
+### التثبيت والإعداد
+
+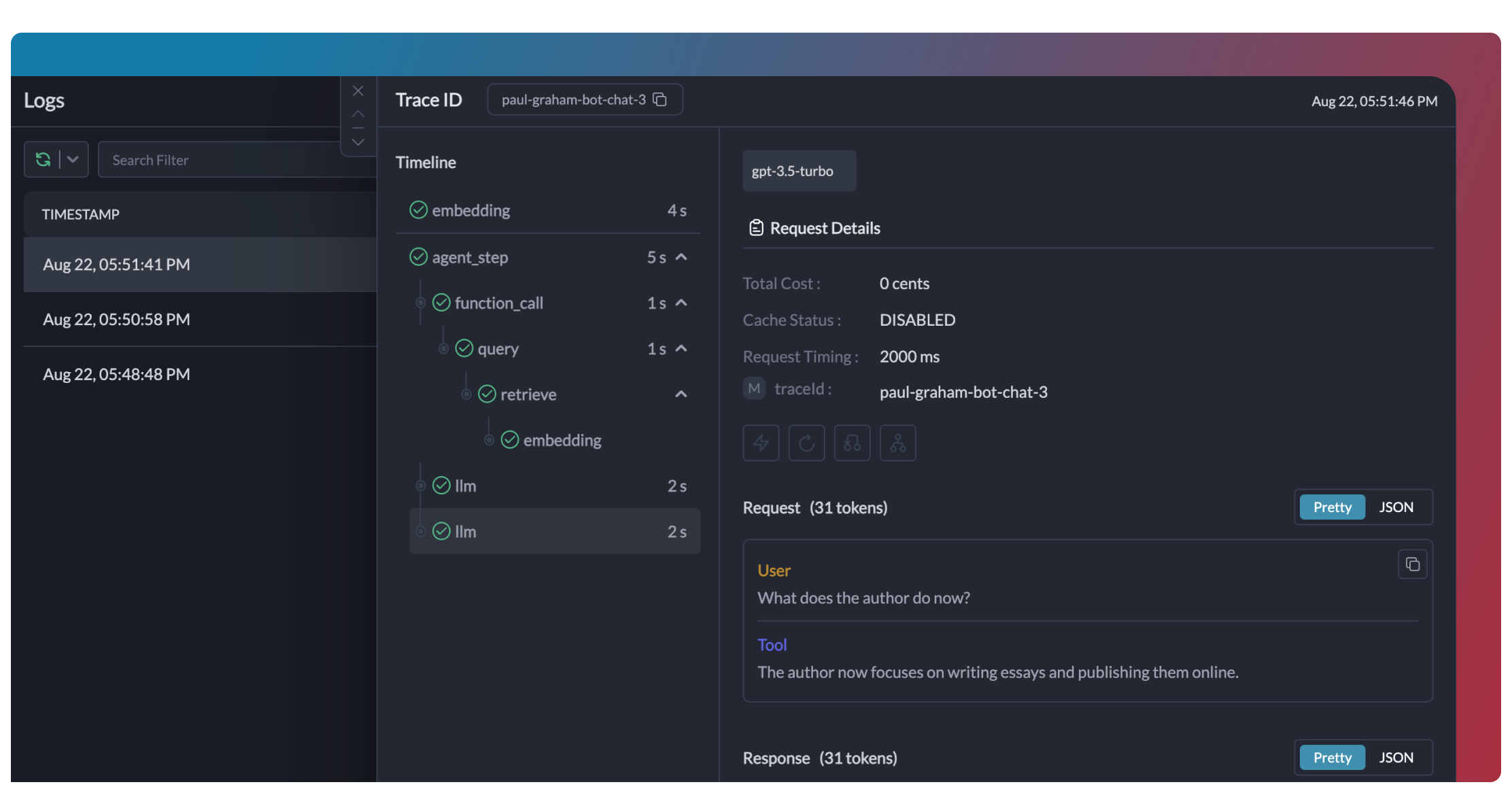 +
+
+توفر التتبعات عرضاً هرمياً لتنفيذ طاقمك، يظهر تسلسل استدعاءات LLM واستدعاءات الأدوات وانتقالات الحالة.
+
+```python
+# Add trace_id to enable hierarchical tracing in Portkey
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ trace_id="unique-session-id" # Add unique trace ID
+ )
+)
+```
+
+
+
+توفر التتبعات عرضاً هرمياً لتنفيذ طاقمك، يظهر تسلسل استدعاءات LLM واستدعاءات الأدوات وانتقالات الحالة.
+
+```python
+# Add trace_id to enable hierarchical tracing in Portkey
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ trace_id="unique-session-id" # Add unique trace ID
+ )
+)
+```
+  +
+
+يسجّل Portkey كل تفاعل مع نماذج LLM، بما في ذلك:
+
+- حمولات الطلب والاستجابة الكاملة
+- مقاييس زمن الاستجابة واستخدام الرموز المميزة
+- حسابات التكلفة
+- استدعاءات الأدوات وتنفيذ الدوال
+
+يمكن تصفية جميع السجلات حسب البيانات الوصفية ومعرّفات التتبع والنماذج والمزيد، مما يسهّل تصحيح أخطاء عمليات تشغيل طاقم محددة.
+
+
+
+يسجّل Portkey كل تفاعل مع نماذج LLM، بما في ذلك:
+
+- حمولات الطلب والاستجابة الكاملة
+- مقاييس زمن الاستجابة واستخدام الرموز المميزة
+- حسابات التكلفة
+- استدعاءات الأدوات وتنفيذ الدوال
+
+يمكن تصفية جميع السجلات حسب البيانات الوصفية ومعرّفات التتبع والنماذج والمزيد، مما يسهّل تصحيح أخطاء عمليات تشغيل طاقم محددة.
+ 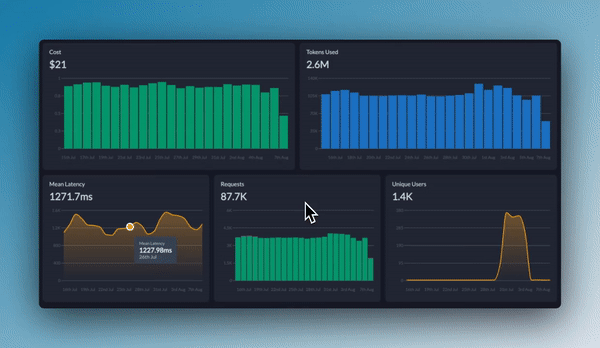 +
+
+يوفر Portkey لوحات معلومات مدمجة تساعدك على:
+
+- تتبع التكلفة واستخدام الرموز المميزة عبر جميع عمليات تشغيل الطاقم
+- تحليل مقاييس الأداء مثل زمن الاستجابة ومعدلات النجاح
+- تحديد الاختناقات في سير عمل الوكلاء
+- مقارنة تكوينات الطاقم ونماذج LLM المختلفة
+
+يمكنك تصفية وتقسيم جميع المقاييس حسب بيانات وصفية مخصصة لتحليل أنواع طواقم أو مجموعات مستخدمين أو حالات استخدام محددة.
+
+
+
+يوفر Portkey لوحات معلومات مدمجة تساعدك على:
+
+- تتبع التكلفة واستخدام الرموز المميزة عبر جميع عمليات تشغيل الطاقم
+- تحليل مقاييس الأداء مثل زمن الاستجابة ومعدلات النجاح
+- تحديد الاختناقات في سير عمل الوكلاء
+- مقارنة تكوينات الطاقم ونماذج LLM المختلفة
+
+يمكنك تصفية وتقسيم جميع المقاييس حسب بيانات وصفية مخصصة لتحليل أنواع طواقم أو مجموعات مستخدمين أو حالات استخدام محددة.
+  +
+
+أضف بيانات وصفية مخصصة لتكوين LLM في CrewAI لتمكين تصفية وتقسيم قوية:
+
+```python
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ metadata={
+ "crew_type": "research_crew",
+ "environment": "production",
+ "_user": "user_123", # Special _user field for user analytics
+ "request_source": "mobile_app"
+ }
+ )
+)
+```
+
+يمكن استخدام هذه البيانات الوصفية لتصفية السجلات والتتبعات والمقاييس في لوحة تحكم Portkey، مما يتيح لك تحليل عمليات تشغيل طاقم أو مستخدمين أو بيئات محددة.
+
+
+
+يمكّن هذا:
+- تتبع التكاليف والميزانية لكل مستخدم
+- تحليلات مستخدم مخصصة
+- مقاييس على مستوى الفريق أو المؤسسة
+- مراقبة خاصة بالبيئة (التجريب مقابل الإنتاج)
+
+
+
+
+أضف بيانات وصفية مخصصة لتكوين LLM في CrewAI لتمكين تصفية وتقسيم قوية:
+
+```python
+portkey_llm = LLM(
+ model="gpt-4o",
+ base_url=PORTKEY_GATEWAY_URL,
+ api_key="dummy",
+ extra_headers=createHeaders(
+ api_key="YOUR_PORTKEY_API_KEY",
+ virtual_key="YOUR_OPENAI_VIRTUAL_KEY",
+ metadata={
+ "crew_type": "research_crew",
+ "environment": "production",
+ "_user": "user_123", # Special _user field for user analytics
+ "request_source": "mobile_app"
+ }
+ )
+)
+```
+
+يمكن استخدام هذه البيانات الوصفية لتصفية السجلات والتتبعات والمقاييس في لوحة تحكم Portkey، مما يتيح لك تحليل عمليات تشغيل طاقم أو مستخدمين أو بيئات محددة.
+
+
+
+يمكّن هذا:
+- تتبع التكاليف والميزانية لكل مستخدم
+- تحليلات مستخدم مخصصة
+- مقاييس على مستوى الفريق أو المؤسسة
+- مراقبة خاصة بالبيئة (التجريب مقابل الإنتاج)
+
+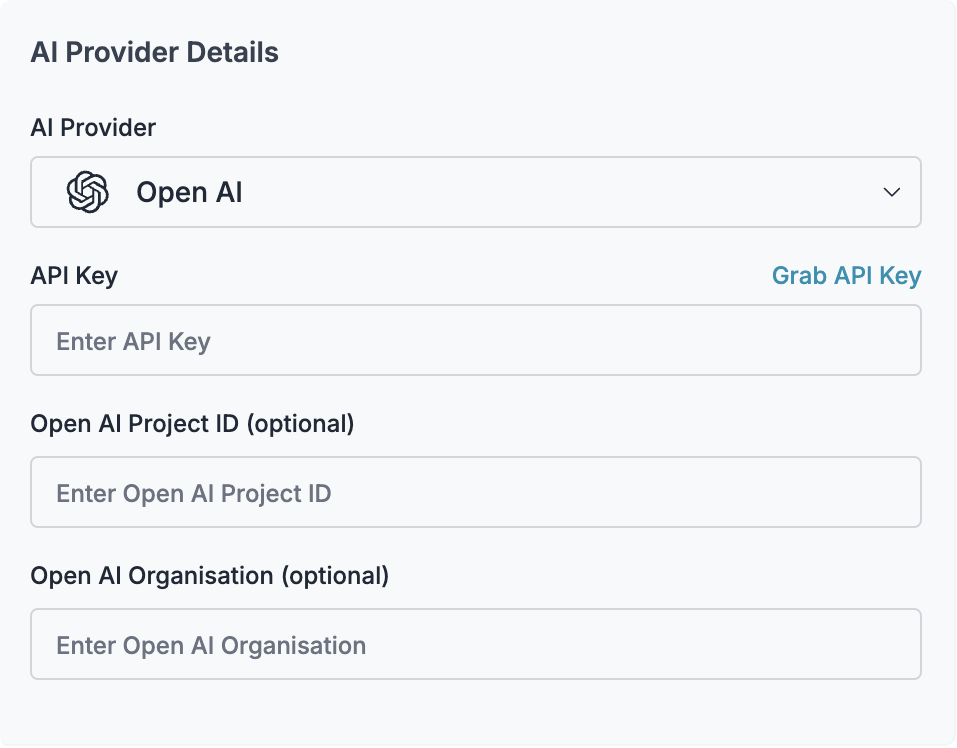 +
+
+
+
+
+ +
+
+
+
+
+ +
+
+
+
+
+
+
+
+
+ وثائق CrewAI الرسمية
+احصل على إرشادات مخصصة لتنفيذ هذا التكامل
+ +
+
+
+
+ The left panel groups checkpoints by branch; forks nest under their parent. Selecting a checkpoint opens the detail panel with metadata, entity state, and task progress. **Resume** continues the run; **Fork** starts a new branch.
+
+
+
+
+
+ The detail panel exposes two editable areas:
+
+ - **Inputs** — original kickoff inputs, pre-filled and editable.
+
+
+
+
+
+ - **Task outputs** — outputs of completed tasks. Editing an output and hitting **Fork** invalidates downstream tasks so they re-run against the modified context.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ The left panel groups checkpoints by branch; forks nest under their parent. Selecting a checkpoint opens the detail panel with metadata, entity state, and task progress. **Resume** continues the run; **Fork** starts a new branch.
+
+
+
+
+
+ The detail panel exposes two editable areas:
+
+ - **Inputs** — original kickoff inputs, pre-filled and editable.
+
+
+
+
+
+ - **Task outputs** — outputs of completed tasks. Editing an output and hitting **Fork** invalidates downstream tasks so they re-run against the modified context.
+
+
+
+
+
+
+
+
+
+ stop parameter, you can simply omit it from your LLM call:
+
+ ```python
+ from crewai import LLM
+ import os
+
+ os.environ["OPENAI_API_KEY"] = "CLI: crewai train -n -f
or Python: crew.train(...)"] --> B["Setup training mode
- task.human_input = true
- disable delegation
- init training_data.pkl + trained file"] + + subgraph "Iterations" + direction LR + C["Iteration i
initial_output"] --> D["User human_feedback"] + D --> E["improved_output"] + E --> F["Append to training_data.pkl
by agent_id and iteration"] + end + + B --> C + F --> G{"More iterations?"} + G -- "Yes" --> C + G -- "No" --> H["Evaluate per agent
aggregate iterations"] + + H --> I["Consolidate
suggestions[] + quality + final_summary"] + I --> J["Save by agent role to trained file
(default: trained_agents_data.pkl)"] + + J --> K["Normal (non-training) runs"] + K --> L["Auto-load suggestions
from trained_agents_data.pkl"] + L --> M["Append to prompt
for consistent improvements"] +``` + +### During training runs + +- On each iteration, the system records for every agent: + - `initial_output`: the agent’s first answer + - `human_feedback`: your inline feedback when prompted + - `improved_output`: the agent’s follow-up answer after feedback +- This data is stored in a working file named `training_data.pkl` keyed by the agent’s internal ID and iteration. +- While training is active, the agent automatically appends your prior human feedback to its prompt to enforce those instructions on subsequent attempts within the training session. + Training is interactive: tasks set `human_input = true`, so running in a non-interactive environment will block on user input. + +### After training completes + +- When `train(...)` finishes, CrewAI evaluates the collected training data per agent and produces a consolidated result containing: + - `suggestions`: clear, actionable instructions distilled from your feedback and the difference between initial/improved outputs + - `quality`: a 0–10 score capturing improvement + - `final_summary`: a step-by-step set of action items for future tasks +- These consolidated results are saved to the filename you pass to `train(...)` (default via CLI is `trained_agents_data.pkl`). Entries are keyed by the agent’s `role` so they can be applied across sessions. +- During normal (non-training) execution, each agent automatically loads its consolidated `suggestions` and appends them to the task prompt as mandatory instructions. This gives you consistent improvements without changing your agent definitions. + +### File summary + +- `training_data.pkl` (ephemeral, per-session): + - Structure: `agent_id -> { iteration_number: { initial_output, human_feedback, improved_output } }` + - Purpose: capture raw data and human feedback during training + - Location: saved in the current working directory (CWD) +- `trained_agents_data.pkl` (or your custom filename): + - Structure: `agent_role -> { suggestions: string[], quality: number, final_summary: string }` + - Purpose: persist consolidated guidance for future runs + - Location: written to the CWD by default; use `-f` to set a custom (including absolute) path + +## Small Language Model Considerations + +
+
+
+
+
+
+### Email Notifications
+
+Toggle to enable or disable email notifications for HITL requests.
+
+| Setting | Default | Description |
+|---------|---------|-------------|
+| Email Notifications | Enabled | Send emails when feedback is requested |
+
+
+
+
+### Rule Structure
+
+```json
+{
+ "name": "Approvals to Finance",
+ "match": {
+ "method_name": "approve_*"
+ },
+ "assign_to_email": "finance@company.com",
+ "assign_from_input": "manager_email"
+}
+```
+
+### Matching Patterns
+
+| Pattern | Description | Example Match |
+|---------|-------------|---------------|
+| `approve_*` | Wildcard (any chars) | `approve_payment`, `approve_vendor` |
+| `review_?` | Single char | `review_a`, `review_1` |
+| `validate_payment` | Exact match | `validate_payment` only |
+
+### Assignment Priority
+
+1. **Dynamic assignment** (`assign_from_input`): If configured, pulls email from flow state
+2. **Static email** (`assign_to_email`): Falls back to configured email
+3. **Deployment creator**: If no rule matches, the deployment creator's email is used
+
+### Dynamic Assignment Example
+
+If your flow state contains `{"sales_rep_email": "alice@company.com"}`, configure:
+
+```json
+{
+ "name": "Route to Sales Rep",
+ "match": {
+ "method_name": "review_*"
+ },
+ "assign_from_input": "sales_rep_email"
+}
+```
+
+The request will be assigned to `alice@company.com` automatically.
+
+
+
+
+### Use Cases
+
+- **SLA compliance**: Ensure flows don't hang indefinitely
+- **Default approval**: Auto-approve low-risk requests after timeout
+- **Graceful degradation**: Continue with a safe default when reviewers are unavailable
+
+
+
+
+### Response Methods
+
+Reviewers can respond via three channels:
+
+| Method | Description |
+|--------|-------------|
+| **Email Reply** | Reply directly to the notification email |
+| **Dashboard** | Use the Enterprise dashboard UI |
+| **API/Webhook** | Programmatic response via API |
+
+### History & Audit Trail
+
+Every HITL interaction is tracked with a complete timeline:
+
+- Decision history (approve/reject/revise)
+- Reviewer identity and timestamp
+- Feedback and comments provided
+- Response method (email/dashboard/API)
+- Response time metrics
+
+## Analytics & Monitoring
+
+Track HITL performance with comprehensive analytics.
+
+### Performance Dashboard
+
+
+
+
+
+
+
+
+### Configuring Webhooks
+
+
+
+
+## Users and Roles
+
+Each member in your CrewAI workspace is assigned a role, which determines their access across various features.
+
+You can:
+
+- Use predefined roles (Owner, Member)
+- Create custom roles tailored to specific permissions
+- Assign roles at any time through the settings panel
+
+You can configure users and roles in Settings → Roles.
+
+
+
+
+### Deployment Permission Types
+
+When granting entity-level access to a specific automation, you can assign these permission types:
+
+| Permission | What it allows |
+| :------------------- | :-------------------------------------------------- |
+| `run` | Execute the automation and use its API |
+| `traces` | View execution traces and logs |
+| `manage_settings` | Edit, redeploy, rollback, or delete the automation |
+| `human_in_the_loop` | Respond to human-in-the-loop (HITL) requests |
+| `full_access` | All of the above |
+
+### Entity-level RBAC for Other Resources
+
+When entity-level RBAC is enabled, access to these resources can also be controlled per user or role:
+
+| Resource | Controlled by | Description |
+| :--------------------- | :------------------------------- | :---------------------------------------------------- |
+| Environment variables | Entity RBAC feature flag | Restrict which roles/users can view or manage specific env vars |
+| LLM connections | Entity RBAC feature flag | Restrict access to specific LLM provider configurations |
+| Git repositories | Git repositories RBAC org setting | Restrict which roles/users can access specific connected repos |
+
+---
+
+## Common Role Patterns
+
+While CrewAI ships with Owner and Member roles, most teams benefit from creating custom roles. Here are common patterns:
+
+### Developer Role
+
+A role for team members who build and deploy automations but don't manage organization settings.
+
+| Feature | Permission |
+| :------------------------ | :--------- |
+| `usage_dashboards` | Read |
+| `crews_dashboards` | Manage |
+| `invitations` | Read |
+| `training_ui` | Read |
+| `tools` | Manage |
+| `agents` | Manage |
+| `environment_variables` | Manage |
+| `llm_connections` | Manage |
+| `default_settings` | No access |
+| `organization_settings` | No access |
+| `studio_projects` | Manage |
+
+### Viewer / Stakeholder Role
+
+A role for non-technical stakeholders who need to monitor automations and view results.
+
+| Feature | Permission |
+| :------------------------ | :--------- |
+| `usage_dashboards` | Read |
+| `crews_dashboards` | Read |
+| `invitations` | No access |
+| `training_ui` | Read |
+| `tools` | Read |
+| `agents` | Read |
+| `environment_variables` | No access |
+| `llm_connections` | No access |
+| `default_settings` | No access |
+| `organization_settings` | No access |
+| `studio_projects` | No access |
+
+### Ops / Platform Admin Role
+
+A role for platform operators who manage infrastructure settings but may not build agents.
+
+| Feature | Permission |
+| :------------------------ | :--------- |
+| `usage_dashboards` | Manage |
+| `crews_dashboards` | Manage |
+| `invitations` | Manage |
+| `training_ui` | Read |
+| `tools` | Read |
+| `agents` | Read |
+| `environment_variables` | Manage |
+| `llm_connections` | Manage |
+| `default_settings` | Manage |
+| `organization_settings` | Read |
+| `studio_projects` | No access |
+
+---
+
+